Tabla de contenido
INTROCUCCIėN
1.2. Justificaci¾n del proyecto
1.4. Organizaci¾n del documento
1.5. La doble utilidad del documento
1.6. Convenciones y tipografĒa
2.3. Requerimientos del proyecto
PRIMERA PARTE: SISTEMAS DE CLUSTERING
4.2. Sistemas de ficheros distribuidos
4.2.1.
Network File System (NFS)
4.3. Sistemas de ficheros paralelos
6.1. Funcionamiento de un sistema HA
6.2. Soluciones de HA en entornos Linux
SEGUNDA PARTE: DISEčO E IMPLEMENTACIėN
7. Estudio, anßlisis y dise±o de una soluci¾n
7.1. Anßlisis del sistema inicial
7.2. Revisi¾n de objetivos y requisitos
7.2.2.
Requisitos no funcionales
7.3.7.
Sistema de Monitorizaci¾n
9.1. Arquitectura propuesta (versi¾n 1.0)
9.2. Instalaci¾n (versi¾n 1.0)
9.3. Configuraci¾n (versi¾n 1.0)
9.3.1.
Consideraciones previas
9.5. Revisi¾n de la arquitectura (versi¾n 1.1)
9.6. Pruebas del nuevo modelo (versi¾n 1.1)
10.1. Arquitectura propuesta (versi¾n 2.0)
10.2. Instalaci¾n (versi¾n 2.0)
10.3. Configuraci¾n (versi¾n 2.0)
10.4.2.
Pruebas de rendimiento
11.1.1.
Instalaci¾n del Master host
11.1.2.
Instalaci¾n de un Execution host
11.2.1.
Zona Spool de mater hosts
12.2.1.
Cluster con GlusterFS (versi¾n 2.0)
13.4. Personalizaci¾n de imßgenes
14.3.1.
Trabajos en ejecuci¾n:
15.2.1. Configuraci¾n
en cliente
15.2.2.
Configuraci¾n en servidor
16.1.2.
Configuraci¾n del servidor
16.1.3.
Configuraci¾n de los clientes
TERCERA PARTE: CONCLUSIONES
18.1. Objetivos y requisitos cumplidos
18.2. Planificaci¾n y estudios de costes
18.2.1.
Planificaci¾n temporal
18.3. Mejoras y ampliaciones del sistema
18.3.1.
Infraestructura de red
18.3.3.
Sistema de almacenamiento
18.3.5.
Checkpointing (transparente) de procesos
AP╔NDICES
19.1. Ficheros de configuraci¾n y scripts
19.1.3. Fichero glusterfs-server.vol
19.1.4. Fichero glusterfs-client.vol
19.1.5. Fichero ha.cf de master-cluster1
19.1.6.
Fichero ha.cf de master-cluster2
19.1.8. Script sungrid de heartbeat
19.1.9.
Fichero drbd.conf de zona spool
19.1.10. Fichero glusterfs-server_sge-common.vol
19.1.11. Fichero glusterfs-client-sge.vol
19.1.12. Fichero bootnode-gluster.shtml
19.1.17. Script jobs_run-slave.sh
19.1.18. Script jobs_queued.sh
19.1.20.
Fichero cluster_extra.tpl
19.1.21. Fichero meta_view.tpl
19.1.25. Fichero update.exim4.conf en master-cluster1
19.1.26.
Fichero update.exim4.conf en nodos de computaci¾n y servidores de disco
19.1.27. Fichero ntp.conf en nodos master-cluster
19.1.28.
Fichero ntp.conf en nodos de computaci¾n y servidores de disco
19.1.32. Script wakeup-cluster.sh
19.1.33. Script halt-cluster.sh
19.1.35.
Script alta_usuario.sh
19.1.36. Script build_users.sh
19.1.37. Script build_homes.sh
19.1.38. Script master_lectura.sh
19.1.40. Script test-disco_lectura.sh
19.1.41. Script
master_escritura.sh
19.1.43. Script test-disco_escritura.sh
19.1.44.
Fichero resultado_lectura.sh
19.1.45.
Listado de paquetes de software instalado
19.4. Referencias bibliogrßficas
1. Introducci¾n
De igual manera que en la dķcada de los 70s el advenimiento de los miniordenadores dio un giro a la idea de computaci¾n masiva, relegando a los poderosos y caros mainframes a aplicaciones prßcticas muy concretas, hoy en dĒa cada vez son mßs las empresas e instituciones, p·blicas y privadas, que se decantan por utilizar clusters en detrimento de grandes mßquinas.
La idea que hay detrßs de los clusters de computaci¾n es simple. Si la potencia de los ordenadores personales de hoy en dĒa es considerable, ┐por quķ no utilizar la potencia conjunta de unas decenas, centenares o incluso miles de ķstos para que, trabajando conjuntamente, puedan llevar a cabo tareas mßs complicadas en un menor tiempo y a un menor coste?
En los ·ltimos a±os, paralelamente al crecimiento en potencia del hardware, ha aumentado la cantidad y calidad de las soluciones software que proveen el sistema necesario para hacer que un conjunto de mßquinas interconectadas trabajen al unĒsono como una gran mßquina. Los avances en redes de computadores y el abaratamiento del hardware han contribuido a universalizar el uso de clusters.
Si bien la mayorĒa de las grandes empresas del sector informßtico han desarrollado alg·n sistema de clustering propio, no hay que menospreciar el esfuerzo de la comunidad open source que, contando con una cantidad ingente de desarrolladores en todo el mundo, ofrecen soluciones totalmente vßlidas que de hecho, se utilizan en las universidades mßs prestigiosas del mundo amen de muchas empresas punteras.
ĀĀĀĀĀĀĀĀĀĀĀ
Este proyecto, ubicado en Laboratorio de Cßlculo del Departamento de Lenguajes y Sistemas Informßticos (LCLSI), estß formado por distintos grupos de investigaci¾n en los que se llevan a cabo tareas que requieren de una gran potencia de cßlculo. Estß claro que el modelo ōejecuto mis simulaciones en mi PCö, a estos niveles, no es una soluci¾n vßlida. Para dar respuesta a estas necesidades se barajan tres posibles opciones, que pasan por disponer de:
Ę Una mßquina muy potente (muchas CPUs, mucha memoria)
Ę Alquiler de recursos de un superordenador (Marenostrum)
Ę Un cluster de computaci¾n propio, mßs escalable y econ¾mico.
Las dos primeras opciones pueden resultar prohibitivas para una secci¾n de un Departamento como LSI, por exigir un fuerte desembolso inicial, de tal forma que la compra de un cluster parece lo mßs razonable. Y lo es mßs si tenemos en cuenta que la secci¾n puede hacer un desembolso inicial, comenzar a explotar el hardware disponible e ir comprando mßs ordenadores (nodos) a medida que dispongan de los fondos necesarios.
1.1. Descripci¾n del proyecto
El proyecto
que nos ocupa consiste en la implantaci¾n de un nuevo sistema de clustering o
computaci¾n masiva para el Departamento de Lenguajes y Sistemas Informßticos de
Las principales actividades del departamento son la docencia y la investigaci¾n.Ā Es esta faceta la que requiere de una gran potencia de cßlculo dada la complejidad y variedad de los proyectos que se tratan.
Durante este proyecto llevaremos a cabo un anßlisis de los requisitos para el nuevo sistema de clustering, estudiaremos las distintas opciones y realizaremos una propuesta que finalmente se implementarß.
1.2. Justificaci¾n del proyecto
El Laboratorio de Cßlculo de LSI, y por tanto el Departamento, viene utilizando clusters desde el a±o 2002. Actualmente hay principalmente tres grupos de investigaci¾n que utilizan clusters en LSI. Hist¾ricamente el primero de ellos se puso en marcha hace cinco a±os, dando servicio a unos pocos usuarios que hasta entonces ejecutaban sus trabajos en sus PCs de escritorio o en mßquinas departamentales, carentes de la potencia necesaria.
En su dĒa se opt¾ por un sistema de clustering tipo SSI (Single System Image) bajo sistema operativo Linux. En este modelo todos los nodos del cluster cuentan con un kernel com·n modificado para que el conjunto del cluster se comporte como una sola mßquina con tantas CPUs como nodos, donde las interconexiones de red sustituyen a las conexiones entre CPUs de un sistema multiprocesador. La gran ventaja de este modelo es la potente abstracci¾n del hardware resultante: los usuarios del cluster pueden ejecutar sus procesos de la misma forma que lo hacen en su PC, despreocupßndose del hardware subyacente. El middleware OpenMosix se encargaba de balancear la carga del cluster moviendo a discreci¾n los procesos de un nodo a otro, buscando en cada momento la optimizaci¾n de los recursos disponibles.
Esta soluci¾n, que ha funcionado bastante bien hasta la fecha, se topa con tres grandes problemas:
ĀĀĀĀĀĀĀĀĀĀĀ
ĀĀĀĀĀĀĀĀĀĀĀ 1. El sistema no cuenta con ning·n mecanismo de protecci¾n ante sobrecargas por exceso de trabajos en ejecuci¾n, de tal forma que podrĒa llegar a colapsarse cuando se lanzan tantos procesos como para consumir toda la memoria disponible.
ĀĀĀĀĀĀĀĀĀĀĀ 2. El proyecto OpenMosix lleva a±os sin facilitar ninguna actualizaci¾n, de tal manera que la versi¾n mßs reciente s¾lo estß disponible para un kernel antiguo que no soporta el hardware de los ordenadores mßs modernos, obligando a las secciones que quieren comprar nuevos nodos para su cluster a comprar hardware obsoleto.
ĀĀĀĀĀĀĀĀĀĀĀ 3. El n·mero de usuarios que utilizan los clusters crece continuamente (actualmente disponemos de unos 100 usuarios), por lo que es imperativo un sistema de colas para que los procesos se ejecuten de forma ordenada, maximizando la utilizaci¾n del hardware en el tiempo.
ĀĀĀĀĀĀĀĀĀĀĀ
La gesti¾n del espacio de disco dentro del cluster es otro punto de vital importancia. Este modelo no cuenta con servidores de disco dedicados, sino que los nodos dedicados a computaci¾n exportan su espacio de disco al resto de nodos.
Nuevamente observamos tres problemas:
ĀĀĀĀĀĀĀĀĀĀĀ
- Es engorroso para el usuario, que cuenta con tantas zonas de disco como nodos tiene el cluster (mßs de 20 zonas en alg·n cluster).
- El sistema de ficheros en red utilizado (NFS) produce un gran overhead en la red.
- No es tolerable a fallos. En caso de que uno de los nodos falle, los datos que se encuentran en su zona dejan de estar disponibles.
Desde el Laboratorio de Cßlculo la propuesta que se realiza apuesta por cambiar el paradigma de clustering por uno basado en colas, mßs escalable, seguro, moderno y con garantĒas de continuidad.
Dado que las soluciones hardware de almacenamiento de disco dedicados quedan fuera de nuestro alcance, optamos por aprovechar el espacio de disco disponible en los nodos de la mejor manera posible, utilizando un sistema de ficheros en red distribuido y paralelo.
Tanto el sistema de colas como el sistema de ficheros deben ser tolerables a fallos, de tal forma que la caĒda de un nodo no comprometa el funcionamiento del resto del cluster ni a nivel deĀ computaci¾n ni a nivel de disponibilidad de informaci¾n.
1.3. Motivaci¾n personal
Durante nueve a±os he trabajado en el Laboratorio de Cßlculo de LSI, primero como becario y mßs tarde como personal laboral. Durante este tiempo he desempe±ando labores de administrador de sistemas, siempre ligado a entornos UNIX y a clusters de computaci¾n.
Mi motivaci¾n a la hora de encarar este proyecto no puede ser mayor, ya que se me presenta la oportunidad de continuar la labor comenzada seis a±os atrßs cuando decidimos apostar por la tecnologĒa cluster. Igualmente, quķ mejor forma de corresponder el compromiso y agradecimiento recibido por parte de los usuarios que implementar un nuevo sistema, mßs potente y fiable que les permita obtener mayores cotas de productividad y satisfacci¾n.
El desarrollo de este proyecto me ha permitido explorar el estado del arte de los distintos elementos que componen un cluster de computaci¾n. El punto de partida de cualquier proyecto de esta envergadura debe contemplar las soluciones ya implementadas.
En este sentido establecimos contacto con distintos departamentos de nuestra universidad como Arquitectura de Computadores, Matemßtica Aplicada I y administradores de sistemas del supercomputador Marenostrum, lo que nos permiti¾ conocer de primera mano la forma de encarar la construcci¾n de un cluster desde el punto de vista de departamentos similares al nuestro.
Una vez el
cluster entr¾ en funcionamiento decidimos compartir la experiencia adquirida
con todos aquellos que nos abrieron sus puertas, asĒ como todo aquel administrador
de sistemas de
Por otra parte los conocimientos adquiridos en el desarrollo de este proyecto han servido como base para la presentaci¾n de la ponencia que llev¾ por tĒtulo Sistemes de computaci¾ dÆaltes prestacions i programari lliure en las VII Jornades de programari Lliure, que tuvieron lugar en Junio de 2008. La documentaci¾n de la ponencia puede consultarse en:
http://gabriel.verdejo.alvarez.googlepages.com/cluster
1.4. Organizaci¾n del documento
Un cluster de computaci¾n es un sistema complejo, formado por multitud de elementos hardware y software en cuya construcci¾n se realiza una verdadera labor de ingenierĒa. La optimizaci¾n de los recursos disponibles buscando el mßximo rendimiento al menor coste implica un conocimiento exhaustivo de las tecnologĒas que utiliza; a saber: sistemas operativos, redes de datos, software de clustering, filesystems paralelos, alta disponibilidad, etc.
Este documento consta de cuatro partes:
Ę Una primera parte de introducci¾n donde se presentan los diferentes componentes de un cluster y se exploran diversas alternativas para cada componente
Ę Una segunda parte donde se realiza el anßlisis tķcnico del proyecto, se analizan las distintas alternativas y propone una soluci¾n.
Ę Una tercera parte que comprende la implementaci¾n de la soluci¾n propuesta, explicando el proceso de instalaci¾n y configuraci¾n de cada uno de los componentes y la implantaci¾n del nuevo cluster en sustituci¾n del actual.
Ę Finalmente un apartado de bibliografĒa y anexos. Por lo general toda referencia aparecerß en los anexos.
Este documento pretende servir como obra de referencia en la construcci¾n y mantenimiento de un cluster de computaci¾n. Se asume un cierto conocimiento de informßtica en general y deĀ administraci¾n de sistemas UNIX en particular, ya que es imposible profundizar completamente en todos los temas tratados. De todas formas, el documento estß redactado de forma que un lector menos experto, pero con interķs, pueda seguir los procedimientos explicados obviando los detalles mßs tķcnicos.
1.5. La doble utilidad del documento
Este escrito, ademßs de documentar este proyecto, pretende servir tambiķn como referencia a las personas encargadas de la administraci¾n del cluster.
En este sentido es interesante que, ademßs de existir una copia en papel, exista una copia disponible en formato electr¾nico. Esto permitirß una mayor facilidad de consulta y abrirß la puerta a posibles correcciones y actualizaciones.
El cluster cuenta con su propio servidor web que, ademßs de ofrecer servicios relacionados con la monitorizaci¾n y administraci¾n del cluster sirve un repositorio de documentaci¾n propia:
http://master-cluster1.lsi.upc.edu/docu
En esta url, ademßs de una copia de este documento, se encuentra informaci¾n adicional como manuales y presentaciones.
1.6. Convenciones y tipografĒa
Para una mejor comprensi¾n de este documento, dada la elevada naturaleza tķcnica de su contenido se seguirßn una serie de convenciones tipogrßficas.
Convenciones tipogrßficas
Como ya se ha podido ver, los nombres propios de origen extranjero, asĒ como los nombres de instituciones u organizaciones (como Departamento de Lenguajes y Sistemas Informßticos) aparecen en cursiva.
Igualmente, todos aquellos anglicismos que necesariamente aparecen en este texto, asĒ como cualquier otro vocablo del ßmbito de la informßtica, aparecerßn tambiķn en cursiva la primera vez que se referencien. Lo mismo sucederß con palabras que, si bien son de origen forßneo, forman ya parte de nuestro lenguaje (como por ejemplo software).
Una parte importante de este proyecto consiste en c¾digo fuente de programas, contenido de ficheros datos y configuraci¾n, nombres de directorios, ficheros, etc. En estos casos el texto aparecerß en fuente de ancho fijo (como /etc/dhcp3), y los comandos o nombres de programas o scripts, ademßs, en negrita (como check_sge.sh).
Convenciones no tipogrßficas
La ambig³edad propia del lenguaje tambiķn estß presente, en gran medida, en los documentos de carßcter tķcnico. De esta forma, a lo largo del documento, utilizamos indistintamente el tķrmino sistema de clustering para denotar tanto al hardware que conforma un cluster como al software que lo gobierna. Siempre que la utilizaci¾n de estos tķrminos pueda llevar a equĒvoco se aclararß su significado.
Siglas y acr¾nimos serßn utilizados, previa introducci¾n de su significado, para facilitar la lectura del texto.
2. Anßlisis preliminar
2.1. Situaci¾n actual
En el momento de comenzar este proyecto, el Departamento de Lenguajes y Sistemas Informßticos contaba con tres clusters de computaci¾n. Cada uno ellos propiedad de un grupo de investigaci¾n distinto.
El modelo HPC[1] Āutilizado basado en openMosix que proporcionaba un entorno confortable y productivo para la cantidad inicial de usuarios, ha quedado obsoleto ante el continuo crecimiento tanto en n·mero de usuarios como en necesidades de cßlculo y espacio de disco.
Igualmente, el esquema l¾gico de la infraestructura hardware asĒ como el sistema que sustenta los datos de usuario, no cuentan con ning·n mecanismo que proporcione tolerancia a fallos (caĒda de un nodo, fallo de un disco) ni alta disponibilidad.
Mßs adelante, en apartado [7.1] dedicado al anßlisis del sistema actual, se detallarß a nivel tķcnico las carencias del modelo actual.
2.2. Objetivos del proyecto
La finalidad de este proyecto es doble. Por una parte, la sustituci¾n de los Āclusters por uno nuevo que se adapte a las nuevas necesidades del Departamento y por otra, la creaci¾n de una documentaci¾n que sirva comoĀ referencia tķcnica al Laboratorio de Cßlculo.
El sistema debe proveer a los usuarios un entorno de trabajo sencillo, amigable y proporcionar una escalabilidad que permita afrontar el futuro sentando unas bases s¾lidas.
2.3. Requerimientos del proyecto
Una vez expuestos los objetivos del proyecto, enumerarķ los requerimientos que tendremos en cuenta a la hora de llevar a cabo el dise±o y la implementaci¾n:
Ę La infraestructura hardware del nuevo cluster debe hacer uso del hardware existente (nodos, red y discos).
Ę Debe soportar una carga de trabajo superior a la actual, dada la tendencia creciente en cuanto a n·mero de usuarios y, por tanto, de volumen de trabajo.
Ę Debe ser tolerable a fallos. El fallo de una parte del sistema no puede comprometer el funcionamiento del conjunto del cluster.
Ę Debe ser escalable, tanto a nivel de software como a nivel de infraestructura hardware.
En cuanto a la documentaci¾n, debe ser clara, concisa y no omitir informaci¾n bßsica pero necesaria para el entendimiento completo de conceptos mßs complejos. Al fin y al cabo esta documentaci¾n debe permitir a cualquier persona cualificada del Laboratorio de Cßlculo entender el funcionamiento del cluster y poder actuar en caso de que se produzca cualquier incidencia.
PRIMERA PARTE
SISTEMAS DE CLUSTERING
![]()
3. Clusters
En este apartado daremos una visi¾n general de lo que es un cluster de c¾mputo, repasaremos brevemente su historia y los clasificaremos atendiendo a diversos criterios seg·n la bibliografĒa existente.
3.1. ┐Quķ es un cluster?
Cuando hablamos de Clusters en el ßmbito de la computaci¾n nos referimos al conjunto de hardware y software que aglutina a grupos de ordenadores que, unidos mediante redes de alta velocidad, trabajan de forma conjunta en la resoluci¾n de problemas.
Los clusters se usan habitualmente para mejorar el rendimiento y/o la disponibilidad por encima de la que provee un solo ordenador, resultando mucho mßs econ¾mico que grandes ordenadores de velocidad y disponibilidad comparables.
Cualquier cluster ofrece uno o varios de los siguientes servicios:
Ę Alto rendimiento: el conjunto del cluster ofrece una capacidad computacional por encima de la de cualquiera de los elementos que lo conforman.
Ę Alta disponibilidad: la redundancia del hardware permite mantener el servicio que ofrecen a·n y cuando falle alguno de los componentes del cluster.
Ę BalanceoĀ de carga: la calidad de servicio mejora repartiendo el trabajo entre los nodos del cluster.
Ę Escalabilidad: la adici¾n de nuevos elementos al cluster provoca un aumento proporcional de su capacidad.
En general, un cluster necesita de varios componentes software y hardware para funcionar:
Ę Nodos
Ę Sistema de almacenamiento
Ę Sistema Operativo
Ę Conexi¾n de red
Ę Middleware
Ę Protocolos de comunicaci¾n y servicios
Ę Aplicaciones
Nodos
Pueden ser desde ordenadores corrientes hasta caros sistemas multiprocesador. En general, cuando hablamos de nodo dentro del ßmbito de la computaci¾n nos referimos a cada uno de los ordenadores que lo conforman. Los nodos pueden ser dedicados si se dedican exclusivamente a labores del cluster o no dedicados si lo hacen de forma parcial o compartida con alguna otra tarea.
Sistema de almacenamiento
El sistema de almacenamiento en un cluster no es un tema baladĒ. En un cluster de tama±o medio puede haber cientos de nodos, cada uno ejecutando uno o varios trabajos que acceden simultßneamente Āa datos. Si estos datos no son accesibles de forma eficiente, el rendimiento del cluster se verß afectado.
Los sistemas de almacenamiento tĒpicos son:
Ę NAS (Network Attached Storage): es un dispositivo dedicado al almacenamiento de datos y a su compartici¾n en red. Cuenta con un sistema operativo optimizado que permite el acceso a los datos a travķs de diversos protocolos como CIFS y NFS.
Ę SAN (Storage Area Network): son unidades de almacenamiento externo que se conectan a uno o varios servidores.
Ę Discos locales: se utilizan los discos locales de los nodos, ya sean IDE, SATA, SCSI o SAS.
La elecci¾n de un sistema u otro depende en gran parte de la disponibilidad econ¾mica. Los discos duros locales siempre estßn disponibles en cualquier nodo que se adquiera y siempre pueden sustituirse por discos de mayor tama±o por poco dinero.
Los sistemas NAS y SAN son sistemas de un rendimiento superior pero que requieren de un desembolso inicial importante. Posteriormente estos sistemas pueden crecer a±adiendo mßs discos.
Como lo habitual es que todos los nodos tengan acceso a los mismos datos, la informaci¾n del sistema de almacenamiento disponible se exporta mediante alg·n sistema de ficheros distribuido como NFS (Network Filesystem) o distribuido paralelo como Lustre o GlusterFS.
Sistema operativo
El sistema operativo de un cluster debe ser Āmultiproceso y multiusuario. Existen distribuciones especĒficas que se componen de un sistema operativo y del software de clustering, si bien tambiķn es posible a±adir la capacidad de clustering a casi cualquier sistema operativo.
Sin lugar a dudas es dentro del mundo UNIX donde encontramos la mayor oferta de sistemas de clustering. Mßs concretamente Linux, dado su carßcter libre y su gran difusi¾n es, en cualquiera de sus variantes, el sistema operativo mßs extendido para estos sistemas de c¾mputo.
Conexi¾n de red
La interconexi¾n de los nodos juega un papel muy importante dentro de la arquitectura de un cluster, siendo una parte crĒtica en determinados tipos de clusters. No en vano las conexiones de red en un cluster vienen a ser lo que las conexiones interprocesador son en un ordenador multiprocesador.
La tecnologĒa de conexi¾n puede ser desde la mßs barata y extendida ethernet hasta las mßs caras y avanzadas como Myrinet o Infiniband. Estas ·ltimas cuentan con mayor ancho de banda y menor latencia, la cual cosa las hace ideales para clusters de tipo HPC.
Middleware
El middleware es una pieza de software que se sit·a entre el sistema operativo y las aplicaciones con el fin de proveer:
Ę Abstracci¾n del hardware: los usuarios ven el cluster como un ·nico ordenador muy potente con el que interact·an, desentendiķndose de la arquitectura subyacente.
Ę Herramientas de gesti¾n del sistema: migraci¾n de procesos, checkpointing, balanceo de carga, tolerancia a fallos, etc.
Ā
Ę Escalabilidad: detecci¾n e incorporaci¾n automßtica de nuevos nodos al cluster.
El middleware recoge los trabajos enviados al cluster por los usuarios y los distribuye entre los nodos de computaci¾n de la mejor manera posible, atendiendo a polĒticas mßs o menos sofisticadas de planificaci¾n.
Aplicaciones
Son las tareas que los usuarios envĒan al cluster. El sistema de clustering debe estar preparado para atender los requisitos de ejecuci¾n de las tareas, que pueden ser desde simples scripts a complejos programas paralelos. Estos ·ltimos necesitan del apoyo de librerĒas de programaci¾n paralela como MPI o PVM, que deben integrarse adecuadamente en el sistema.
3.2. Un poco de historia
La bibliografĒa no fija una fecha concreta para el origen del tķrmino cluster pero es bien sabido que comenz¾ a utilizarse entre finales de los a±os 50s y principios de los 60s.
ĀLa idea de la explotaci¾n de sistemas de ordenadores como un medio para acelerar el cßlculo paralelo data de 1967 cuando Gene Amdahl de IBM, public¾ su famosa ley, que describe matemßticamente la ganancia esperada al paralelizar tareas en una arquitectura paralela. El artĒculo define la base para la ingenierĒa multiprocesador, que es extrapolable a clusters de computaci¾n, donde la comunicaci¾n interprocesador es sustituida por conexiones de red.
La historia de los primeros clusters trascurre paralela a la historia de las primeras redes. Una de las principales motivaciones para el desarrollo de las redes de entonces era conectar recursos de cßlculo, creando de hecho un gigantesco cluster.
Las redes de conmutaci¾n de paquetes fueron inventadas por la corporaci¾n RAND en 1962. Utilizando esta tecnologĒa, en 1969, el proyecto ARPANET cre¾ la primera red de computadoras, que unĒan los recursos de cuatro centros de cßlculo. El proyecto ARPANET creci¾ Āhasta convertirse lo que hoy en dĒa es Internet.
El desarrollo de PCs y clusters de grupos de investigaci¾n continu¾ de la mano con el de las redes y el sistema operativo Unix que a principios de los 1970s, ya incluĒa protocolos de comunicaciones de red como TCP/IP.
Pero no fue hasta 1983 cuando, gracias a los conceptos formalizados por BSD Unix e implementados por Sun Microsystems, el p·blico cont¾ con verdaderas herramientas que permitiesen la compartici¾nĀ recursos, como ficheros gracias a la inclusi¾n del sistema de ficheros distribuido NFS.
ARCnet, el primer cluster comercial desarrollado por Datapoint en 1977, no tuvo una gran acogida. Sin embargo en 1984 Digital introdujo con gran ķxito el VAXcluster, acompa±ado del sistema operativo VAX/VMS. Ambos sistemas no permitĒan el procesamiento paralelo, pero sĒ la compartici¾n de recursos como archivos y perifķricos.
Otros productos pioneros fueron el Tandem Himalaya en 1994 como producto de alta disponibilidadĀ y el IBM S/390 Parallell Sysplex destinado a grandes empresas.
Cabe remarcar tambiķn el papel jugado por el software Parallel Virtual Machine (PVM), creado en 1989. Este proyecto open source basado en comunicaciones TCP/IP permiti¾ la creaci¾n de superordenadores creados por cualquier cantidad de sistemas conectados por red. Rßpidamente estos clusters superaron con creces la potencia de los grandes y caros superordenadores de la ķpoca.
Finalmente, en 1995 se cre¾ el primer Beowulf, cluster con sistema operativo Linux caracterizado por utilizar ordenadores y redes convencionales con el fin ·nico de procesar tareas paralelas con un gran throughput.
3.3. Tipos de cluster
El tķrmino cluster tiene diferentes connotaciones en funci¾n de los servicios que ofrecen. Si atendemos a una categorizaci¾n seg·n el fin para el que fueron concebidos, tenemos los siguientes tipos:
Ę HPC (High Performance Clusters o Clusters de Alto Rendimiento): Llevan a cabo tareas de una gran capacidad computacional, que ejecutadas en ordenadores corrientes serĒan inabarcables, ya sea por sus altos requisitos de memoria, potencia de cßlculo o de ambas.
Ę HTC (High Throughput Clusters o Clusters de Alta Eficiencia): Estßn dise±ados para llevar a cabo la mayor cantidad de tareas en el menor tiempo posible. Los datos de las tareas son individuales entre si y la latencia entre los nodos no es tan importante como en los clusters HPC.Ā
Ę HA (High Availability Clusters o clusters de Alta Disponibilidad): Tambiķn conocidos como clusters Failover, su principal cometido es mejorar la disponibilidad de los servicios que proporciona. Su arquitectura se compone de nodos redundantes que proveen el servicio cuando alg·n componente falla.
ĀNormalmente estßn formados por dos nodos, que es lo mĒnimo necesario para tener redundancia. La existencia de redundancia en el hardware evita tener un ·nico punto de fallo, maximizando asĒ la disponibilidad.
Parte del ķxito de los clusters radica en su extrema flexibilidad desde el punto de vista de la arquitectura. En este sentido encontramos las siguientes categorĒas:
Ę Clusters Homogķneos: Todos los nodos cuentan con el mismo hardware y sistema operativo.
Ę Clusters Heterogķneos: Nodos con diferente hardware y sistema operativo.
Ę Clusters Semihomogķneos: Hardware y sistemas operativos similares, pero con distinto rendimiento.
4. Cluster Filesystems
Cuando hablamos de un sistema de ficheros para un cluster se suele pensar en sistemas de ficheros complejos, extra±os y alejados de los utilizados habitualmente en sistemas mßs convencionales. Nada mßs lejos de la realidad. Un cluster no tiene porquķ contar con el filesystem mßs complejo ni con el que usan los clusters mßs potentes, ni siquiera con uno concebido a tal efecto. Para cada cluster, o mejor dicho, dependiendo del uso y de la exigencia que se vaya a dar, hay un abanico enorme de posibilidades que van desde filesystems distribuidos ordinarios a complejos filesystems paralelos.
4.1. Glosario
En este apartado estudiaremos algunos filesystems susceptibles de ser utilizados dentro de un cluster de computaci¾n como el que proyectamos. Antes es necesario dar algunas definiciones para facilitar su comprensi¾n:
Ę Filesystem: mķtodo de almacenamiento y organizaci¾n de ficheros y los datos que permite su b·squeda y acceso.
Ę Servidor: mßquina que pone a disposici¾n de otras mßquinas (clientes) conectadas por red un sistema de ficheros.
Ę Cliente: mßquina que accede al sistema de ficheros de una mßquina remota (servidor).
Ā
Ę Daemon: o demonio es un programa que se ejecuta en segundo plano (background) de forma indefinida encargado de recibir y procesar peticiones.
Ę Automounter: sistema que monta sistemas de ficheros bajo demanda, reduciendo asĒ el overhead de mantener la conexi¾n entre servidor y clientes cuando los clientes no estßn accediendo al filesystem remoto.
Ę Bloqueo: o en inglķs lock, es un mecanismo que permite asegurar la integridad de los datos cuando son accedidos de forma concurrente.
Ā
Ę Stripe: aplicado a filesystems paralelos, cada una de las partes en que se divide un fichero y que son guardadas en servidores de datos distintos para aumentar el rendimiento de lectura y escritura.
Ā
Ę Network filesystem o distributed filesystem: es un sistema de ficheros que soporta la compartici¾n de ficheros, impresoras u otros recursos de forma persistente a travķs de una red.
Ę Parallel filesystem: sistemas de ficheros distribuidos que distribuyen los datos en varios servidores para obtener un mayor rendimiento. Suelen utilizarse en clusters de alto rendimiento (HPC).
4.2. Sistemas de ficheros distribuidos
Un sistema de ficheros distribuido se muestra a los usuarios como un sistema de ficheros local convencional. La multiplicidad y la dispersi¾n de los servidores y su almacenamiento queda oculto. De hecho, los programas que tratan con datos no distinguen si ķstos son locales o no.
El rendimiento esperado de un sistema de ficheros distribuido es menor que el de un sistema de ficheros local, ya que al tiempo de acceso a disco y proceso de CPU hay que sumar el overhead producido por la comunicaci¾n por la red. Esto incluye el tiempo de realizar la petici¾n al servidor y el tiempo en obtener la respuesta en ambas direcciones mßs el overhead de CPU que provoca el protocolo de comunicaciones.
4.2.1. Network File System (NFS)
NFS es un
protocolo de nivel de aplicaci¾n seg·n el modelo OSI que se utiliza en sistemas de archivos distribuidos en redes de
ßrea local. Permite que distintos sistemas conectados a una misma red tengan
acceso a ficheros remotos como si fueran locales. Fue desarrollado en 1984 por Sun
Microsystems con el objetivo de que fuera independiente de la mßquina, el
sistema operativo y el protocolo de transporte.
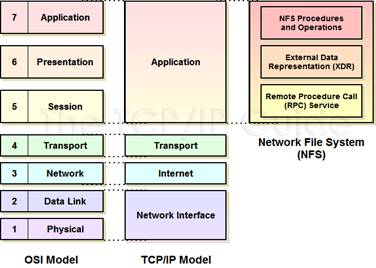
Figura 4.1. El protocolo NFS en los modelos OSI y TCP/IP
El protocolo NFS estß incluido por defecto en los sistemas operativos UNIX. NFS utiliza un esquema cliente-servidor, donde los clientes acceden de forma remota a los datos que se encuentran almacenados en el servidor.
Los clientes utilizan menos espacio de disco, ya que los datos estßn centralizados en un servidor, evitando asĒ tener datos replicados. La centralizaci¾n del home de usuarios es un uso habitual de NFS dentro de organizaciones.
Todas las operaciones sobre ficheros son sĒncronas. Esto quiere decir que la operaci¾n s¾lo retorna cuando se ha completado el trabajo asociado, que en el caso de una escritura serß cuando el servidor escriba fĒsicamente los datos en disco. De esta forma la integridad de los ficheros queda garantizada.
Actualmente hay tres versiones en uso:
Ę Versi¾n 2: originalmente desarrollada sobre UDP,Ā es la mßs antigua y estß soportada por muchos sistemas operativos.
Ę Versi¾n 3: incluye soporte 64 bits que permite manejar ficheros de mßs de 4 GB, escrituras asĒncronas para mejorar el rendimiento, atributos extendidos y en algunas implementaciones, soporte TCP como transporte.
Ę Versi¾n 4: influenciado por AFS y CIFS, incluye cambios orientados a mejorar el rendimiento y la seguridad como soporte Kerberos y ACLs.
4.2.2. Samba
Samba es un software opensource para sistemas UNIX que implementa el protocolo SMB (Server Message Protocol) de archivos compartidos de Microsoft Windows, que permite la compartici¾n de ficheros e impresoras entre sistemas Windows y UNIX.
Samba implementa una docena de protocolos entre los que se encuentran NetBIOS, WINS la suit de protocolos de dominio NT, Active Directory y SMB, tambiķn conocido como CIFS.
Como hemos comentado, Samba permite la compartici¾n de recursos en sistemas heterogķneos. Ahora bien, limitaciones como la incompatibilidad con los atributos de ficheros y los enlaces simb¾licos de los sistemas de ficheros del mundo UNIX, lo desaconsejan como filesystem distribuido para clusters formados exclusivamente por mßquinas UNIX.
4.3. Sistemas de ficheros paralelos
Los sistemas de ficheros distribuidos paralelos surgen de la necesidad de solucionar los problemas que nos encontramos al utilizar sistemas de ficheros distribuidos convencionales en clusters de computaci¾n.
Sistemas de ficheros distribuidos como NFS provocan un gran overhead de red que en condiciones de E/S intensiva llegan a saturar el acceso a los datos. Si imaginamos un escenario con un cluster de tama±o medio de unos pocos centenares de nodos es fßcil hacerse a la idea de la cantidad ingente de peticiones de E/S que pueden generarse en un disco compartido.
Los sistemas de ficheros distribuidos paralelos solucionan este problema reduciendo el overhead de red y distribuyendo los datos entre varios servidores para paralelizar las lecturas y escrituras.
4.3.1. GPFS
General Parallel Filesystem (GPFS) es un sistema de ficheros distribuido paralelo desarrollado por IBM. Proporciona acceso compartido concurrente de alta velocidad a aplicaciones que se ejecutan en distintos nodos de un cluster.
Inicialmente fue dise±ado para soportar las altas tasas de transferencia requeridas por las aplicaciones multimedia, pero su dise±o result¾ muy adecuado para la computaci¾n cientĒfica. Fue desarrollado en 1993, pero no vio la luz comercialmente hasta 1998 cuando fue publicado para el sistema operativo AIX. Desde 2001 tambiķn hay disponible una versi¾n para Linux.
El principio de funcionamiento de GPFS es el mismo que el de cualquier sistema de ficheros paralelo. En un cluster de almacenamiento GPFS hay nodos servidores, que almacenan datos, y nodos clientes que acceden a ellos. Cuando se realiza una operaci¾n de escritura sobre este filesystem los datos se troceanĀ y se distribuyen en tiras (stripes) que son almacenadas en varias mßquinas servidoras de disco. De esta forma se obtiene un mayor rendimiento al acceder a los distintos bloques en paralelo. Ademßs GPFS permite alta disponibilidad, ya que los datos pueden guardarse replicados en varios servidores.
4.3.2. Lustre
Lustre es un sistema de ficheros distribuido paralelo para clusters escalable, robusto y con alta disponibilidad. Desarrollado y mantenido por Sun Microsystems, estß disponible bajo licencia GNU GPL.
ProporcionaĀ un sistema de almacenamiento que escala correctamente desde sistemas con decenas de nodos y terabytes de capacidad de almacenamiento hasta grandes clusters con decenas de miles de nodos con petabytes de informaci¾n.
Lustre es considerado el mejor filesystem distribuido paralelo. De hecho 15 de los 30 mayores superordenadores del mundo[2] hacen uso de Lustre y su gran escalabilidad.
Durante la fase de pruebas/integraci¾n comprobaremos si, el que sobre el papel es el mejor sistema de ficheros distribuido paralelo, se adapta a nuestras necesidades. Nuestro sistema de cluster no llega al centenar de nodos y tiene algunas limitaciones hardware por lo que, como veremos, serß necesario aunar distintas tecnologĒas para tener un sistema funcional.
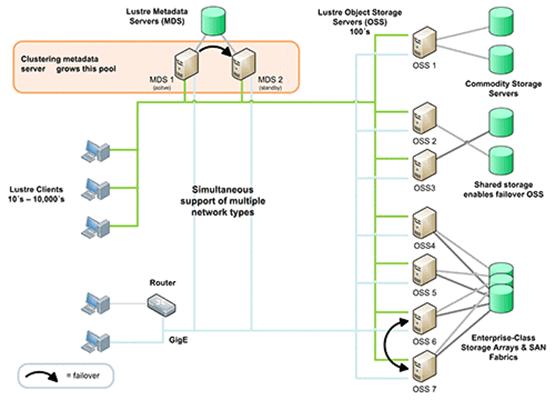
Figura 4.2: Ejemplo de cluster Lustre
4.3.3. GlusterFS
GlusterFS es un sistema de ficheros paralelo distribuido, disponible bajo licencia GNU v3, capaz de escalar hasta varios petabytes. GlusterFS aglutina varias unidades de almacenamiento independientes en un gran sistema de ficheros paralelo sencillo y altamente escalable. Cada unidad de almacenamiento cuenta con su propia CPU, memoria, bus de E/S, almacenamiento RAID e interfaz de red. El rendimiento pico te¾rico serĒa el rendimento agregado de todas las unidades. GlusterFS estß dise±ado para escalar linealmente en clusters de gran tama±o.
El servidor GlusterFS permite exportar vol·menes sobre la red. El cliente GlusterFS monta los vol·menes del servidor en el kernel VFS. La mayor parte de la funcionalidad de GlusterFS estß implementada mediante translators.
La idea de translator estß basada en el sistema operativo GNU/Hurd (http://hurd.gnu.org). Los Translators son un mecanismo muy potente que permite a GlusterFS extender sus capacidades a travķs de un interfaz bien definido. Los translators del lado cliente y servidor son compatibles, por lo que se pueden cargar indiferentemente en cada parte. Son objetos binarios compartidos (.so) que se cargan en tiempo de ejecuci¾n seg·n el ficheros de especificaci¾n del volumen.
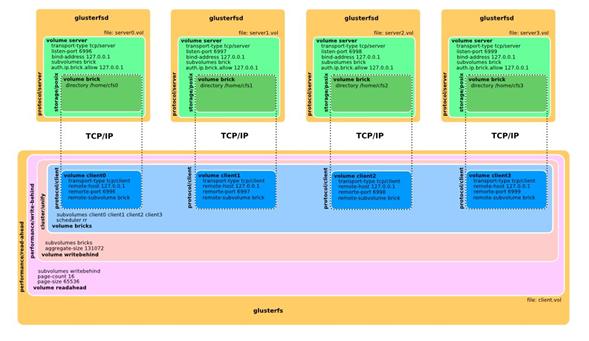
Figura 4.3: Ejemplo de configuraci¾n de GlusterFS con 4 nodos de almacenamiento y 1 nodo cliente
5. Software de Clustering
Como hemos visto en el capĒtulo [3] no basta con conectar una serie de ordenadores en red para tener un cluster. Es necesario un software o middleware que se encargue de distribuir los trabajos de los usuarios entre los nodos disponibles de forma ¾ptima.
A continuaci¾n veremos varios ejemplos de sistemas de clustering, profundizando especialmente en openMosix por ser el middleware de los tres clusters en producci¾n. Mßs adelante, en el anßlisis del sistema actual (apartado [7.1]), volveremos a hablar de openMosix y expondremos las limitaciones que nos han llevado a su sustituci¾n.
5.1. openMosix
openMosix
tiene su origen en Mosix, un sistema
de clustering SSI (Single System Image), cuyo desarrollo comenz¾ en 1981 en
A finales de 2001 Mosix deja de distribuirse bajo licencia GPL, y es entonces cuando nace openMosix, la versi¾n abierta de Mosix, bajo licencia full GPL2. Esto permiti¾ que el proyecto openMosix contase con una amplia comunidad respaldßndolo y contribuyendo a su desarrollo.
OpenMosix es un software que permite que ordenadores conectados en red funcionando bajo GNU/Linux trabajen de forma cooperativa. Es capaz de balancear automßticamenteĀ la carga entre los diferentes nodos del cluster y permite la adici¾n o sustracci¾n de nodos en caliente sin necesidad de interrumpir el servicio.
La carga se distribuye entre los distintos nodos atendiendo a parßmetros como tipo de conexi¾n, memoria disponible y velocidad de CPU.
Dado que openMosix forma parte del kernel y mantiene total compatibilidad con Linux, los programas de usuario, ficheros y otros recursos funcionarßn igualmente sin cambio alguno. El usuario final no notan diferencia alguna entre ejecutar sus aplicaciones en su sistema Linux o en un cluster openMosix. Para ellos, la totalidad del cluster se presenta como un gran sistema multiprocesador.
OpenMosix consta de un parche de kernel Linux compatible con plataformas IA32. Este parche introduce las modificaciones necesarias en el kernel que permiten la comunicaci¾n entre los nodos del cluster. Todos los nodos de un cluster openMosix cuentan con el mismo kernel modificado, de ahĒ el nombre de cluster Single System Image (SSI).
El algoritmo de balanceo de carga migra los procesos entre los distintos nodos de forma transparente, intentando optimizar su utilizaci¾n en todo momento, si bien el administrador puede modificar manualmente este algoritmo.
El hecho de
que la migraci¾n de procesos se haga de forma transparente hace que el conjunto
del cluster se muestre como un gran sistema multiprocesador (SMP) con tantos procesadores
disponibles como el sumatorio de los procesadores de todos los nodos.
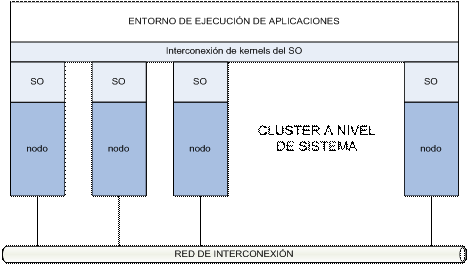
Figura
5.1: Arquitectura de un cluster tipo SSI
CaracterĒsticas
de openMosix
Ę Alta escalabilidad.
Ę Algoritmo adaptativo de balanceo de carga.
Ę Migraci¾n dinßmica de procesos.
Ę Middleware de clustering en kernel, por lo que no son necesarias librerĒas externas.
Ę Totalmente transparente a usuario y aplicaciones.
Ę Fßcil instalaci¾n y administraci¾n.
Ę Posibilidad de a±adir y eliminar nodos en caliente.
Ę Integraci¾n con librerĒas de paralelizaci¾n MPI/PVM.
Funcionamiento
de openMosix
OpenMosix consta de una parte de sistema (kernel space) y otra de usuario (user space):
Ā
La parte de usuario dispone de una serie de herramientas que permiten monitorizar el cluster y la modificaci¾n del comportamiento por defecto de openMosix.
La parte de sistema consiste en un parche de kernel que a su vez consta de cuatro subsistemas:
- Migraci¾n de procesos: Cada proceso tiene su nodo raĒz (UHN, Unique Home Node) que se corresponde con el nodo que lo ha creado. El concepto de migraci¾n implica la divisi¾n del proceso en dos partes: la parte de sistema y la de usuario. La parte de sistema (deputy) permanece en su UHN durante toda la vida del proceso, mientras que la parte de usuario puede moverse libremente por todos los nodos del cluster.
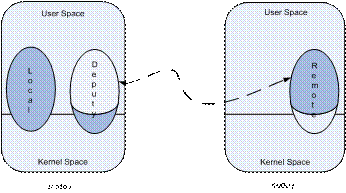
Figura 5.2: Divisi¾n de procesos en openMosix
Ā
El sistema de migraci¾n utiliza algoritmos del campo de la economĒa para decidir cußndo migrar un proceso. A cada recursoĀ (CPU, memoria, E/S) de cada nodo se le da un coste.
Estos costes son unificados en un GFC (global cost function). El valor del CFG de un nodo no se publicita a todo el cluster, sino a un subconjunto aleatorio de sus vecinos.
Los procesos son migrados al nodo donde tienen el menor coste: se obtiene asĒ la distribuci¾n mßs ōecon¾micaö posible. Cada proceso puede migrar cuantas veces sea necesario.
- Memory ushering: Este subsistema se encarga de migrar las tareas que superan la memoria disponible en el nodo en el que se ejecutan. Las tareas que superan este lĒmite son migradas forzosamente a otros nodos con la suficiente memoria como para ejecutar el proceso sin necesidad de hacer swap a disco, evitando asĒ una gran pķrdida de rendimiento.
- Mosix File System (MFS): MFS permite que sistemas de ficheros de nodos remotos sea accesibles localmente. Si se habilita esta opci¾n en el kernel, el sistema de ficheros del nodo local y los demßs aparecerßn montados en /mfs.
- Direct File System Access (DFSA): esta opci¾n permite a los procesos hacer operaciones de E/S de forma local en nodos remotos. Sin DFSA, cada operaci¾n de E/S que se produzca en un nodo ōmigradoö serß enviada al UHN, donde se resolverß.
5.2. Condor
Condor es un
software que crea un entorno de computaci¾n HTC formado por estaciones de
trabajo UNIX conectadas en red. Fue creado por
Condor puede configurarse para utilizar los ciclos libres en mßquinas conectadas a la red y que no estßn pensadas como mßquinas de computaci¾n, como de PCs de escritorio. En este caso, en momentos en los que estas mßquinas no son utilizadas pasan a formar parte del cluster. Cualquier evento de usuario como un input de teclado o rat¾n, provoca que la mßquina salga del cluster.
Este modelo es especialmente interesante para organizaciones que cuentan con una gran n·mero de PCs de usuario con muchos ciclos libres; por ejemplo, durante las noches o fuera del horario laboral. Durante estos espacios de tiempo, el cluster Condor crecerĒa considerablemente, incrementando notablemente el thoughput de c¾mputo.
5.3. PBS
PBS (Portable Batch System) es un sistema de
trabajos batch y un sistema de
gesti¾n de recursos. Fue desarrollado por
PBS consta de cuatro componentes:
Ę Commands: PBS proporciona una serie de comandos en lĒnea asĒ como un interfaz grßfico, ambos conforme al estßndar POSIX 1003.2d. Estos comandos permiten enviar, monitorizar, modificar y borrar trabajos.
Ę Job Server: es la parte central de PBS. Todos los comandos y daemons se comunican con el servidor. La principal funci¾n de ķste es proveer los servicios batch bßsicos como recibir y crear un trabajo, modificarlo, protegerlo de posibles caĒdas del sistema y ponerlo en ejecuci¾n.
Ę Job Executor: es el daemon que realmente pone el trabajo en ejecuci¾n. Su nombre, mom, se debe a que es la madre de todos los procesos en ejecuci¾n. Mom pone en ejecuci¾n el trabajo cuando recibe una copia del servidor. Tambiķn reproduce la sesi¾n del usuario propietario del trabajoĀ (shell, .login, .csh, etc). Finalmente, al acabar el trabajo, devuelve la salida al usuario.
Ę Job Scheduler: este daemon contiene las polĒticas que controlan quķ trabajo, cußndo u d¾nde se ejecutan los trabajos.
5.4. Sun Grid Engine
Sun Grid Engine (SGE) es un sistema de gesti¾n de colas open source desarrollado por Sun Microsystems.
En el a±o 2000 Sun adquiri¾ Gridware, empresa especializada en sistemas de gesti¾n de resursos de computaci¾n para ofrecer una versi¾n free de Gridware para Solaris y Linux a la que llam¾ Sun Grid Engine.
En 2001, liber¾ el c¾digo y adopt¾ el modelo de desarrollo open source, tras lo que surgieron ports para otros sistemas UNIX.
Es un sistema altamente configurable, sencillo de de administrar y de utilizar por parte de los usuarios. Su escalabilidad lo ha llevado a ser el sistema de clustering de mayor ķxito entre los mayores clusters de supercomputaci¾n.
Como sistema de gesti¾n de colas, SGE se encarga de aceptar, planificar y ejecutar grandes cantidades de trabajos. Tambiķn se encarga de la gesti¾n y planificaci¾n de recursos distribuidos como procesadores, memoria, disco y licencias de software.
Un cluster Sun Grid se compone de un master host y uno o mßs execution host. Ademßs pueden configurarse m·ltiples shadow hosts como hot spares capaces de tomar el control del master host cuando falle, proporcionando alta disponibilidad.
Al igual que Condor y PBS, Sun Grid trabaja con shellscripts que definen los requisitos de los trabajos de los usuarios, pero ademßs puede tratar directamente con binarios e incluso ejecutar trabajos interactivos.
Se trata, sin lugar a dudas, del producto mßs completo disponible en el mercado, tanto por rendimiento como por facilidad de uso y capacidad de configuraci¾n. A todo esto hay que sumar el hecho de que se trata de un proyecto opensource con una comunidad de desarrolladores y administradores ingente y, algo de lo que pecan otros proyectos, el respaldo de una empresa del prestigio como Sun Microsystems.
Ā
6. Alta disponibilidad
En el apartado [3.3] hemos visto que los clusters HA o de alta disponibilidad son un tipo de clusters con nodos redundantes encargados de mantener un servicio en caso de fallo hardware. En este capĒtulo explicaremos los principios bßsicos de la alta disponibilidad.
En servicios crĒticos suelen implementarse sistemas tolerables a fallos (fault tolerant o FT) en los que el servicio siempre estß disponible. Estos sistemas son extremadamente caros, por lo que suelen quedar fuera del abasto de empresas e instituciones de tama±o medio.
Los sistemas de alta disponibilidad intentan obtener prestaciones cercanas a la tolerancia a fallos a un precio mucho menor. La alta disponibilidad estß basada en la replicaci¾n de elementos, lo que resulta mucho mßs barato que contar con un solo elemento tolerable a fallos.
A efectos prßcticos, la diferencia entre los sistemas tolerables a fallos y los de alta disponibilidad es el periodo de tiempo en el cual el servicio no estß disponible (downtime). En sistemas tolerables a fallos este tiempo no existe, mientras que en los sistemas de alta disponibilidad se intenta minimizar pero existen, pudiendo ser de unos segundos a varios minutos, dependiendo del timeout que decide si el sistema ha fallado.
Un sistema de alta disponibilidad se basa en la replicaci¾n de elementos, ya sean piezas hardware concretas o servidores completos, tomando como modelo los RAID (Redundant Array of Independent Disks). El objetivo de la replicaci¾n es eliminar los puntos de fallo ·nicos (SPOF, Single Point of Failure). Cualquier elemento no replicado es susceptible de fallar y producir un corte en el servicio. Cuando lo que se replica es un servidor completo hablamos de un cluster HA.
6.1. Funcionamiento de un sistema HA
A continuaci¾n definiremos una serie de conceptos bßsicos para la alta disponibilidad:
Failover
Es el nombre genķrico que se da a un nodo que puede asumir la responsabilidad de otro, importar sus recursos y levantar sus servicios. Cuando se da esta situaci¾n, en el caso de servicios con nodos duplicados, nos encontramos temporalmente en un escenario de SPOF hasta que el administrador restaure el nodo caĒdo.
Takeover
Es un failover automßtico que se produce cuando un nodo detecta el fallo de otro. Para ello es necesario mecanismos de monitorizaci¾n del servicio. Debe haber mecanismos que obliguen al nodo fallado a ceder sus servicios para evitar inconsistencias de funcionamiento.
Switchover o Giveaway
Es un failover manual que consiste en ceder los servicios del nodo que ha fallado a otro nodo mientras se llevan a cabo las actuaciones administrativas pertinentes.
Splitbrain
Para la gesti¾n de un cluster HA es necesario un mecanismo de comunicaci¾n y verificaci¾n de los nodos que lo integran. Cada nodo debe gestionar sus propios recursos seg·n el estado del cluster a la vez que chequea el estado de los otros nodos y servicios.
Se produce un splitbrain cuando la comunicaci¾n entre los nodos falla. En esta situaci¾n cada nodo cree que es el ·nico activo y como no puede saber el estado de su compa±ero considera que ha fallado y fuerza un takeover.
Esta situaci¾n es peligrosa, ya que los dos nodos intentan apropiarse de los recursos. El peligro es a·n mayor cuando el servicio es, por ejemplo, un sistema de almacenamiento de datos, en el que cada nodo podrĒa escribir por su cuenta y provocar corrupci¾n de datos.
Para solucionar este tipo de situaciones, cuando un nodo detecta un fallo reserva un recurso compartido llamado qu¾rum. El qu¾rum es un recurso exclusivo, que s¾lo puede ser reservado por un nodo. El nodo que intente reservarlo y no pueda entiende que debe abandonar el cluster y ceder sus servicios.
6.2. Soluciones de HA en entornos Linux
A continuaci¾n analizamos algunas soluciones que implementan mecanismos de alta disponibilidad en entornos Linux:
Heartbeat
Heartbeat es considerado como el estßndar de facto de la alta disponibilidad en entornos Linux. Se engloba dentro del proyecto Linux-HA (Linux High Availability) y es ampliamente adoptado por miles de clusters en todo el mundo que proveen servicios crĒticos.
Heartbeat forma parte de la mayorĒa de las distribuciones Linux, si bien se trata de un software altamente portable que corre sin problemas en sistemas FreeBSD, Solaris, OpenBSD y MacOS/X. Cuenta con licencia GPL. Sus principales caracterĒsticas son:
Ę No hay limitaci¾n en elĀ n·mero de nodos que puede monitorizar. Puede utilizarse para monitorizar desde clusters sencillos hasta clusters muy grandes.
Ę Monitorizaci¾n de recursos: los recursos pueden relanzarse o moverse a otro nodo en caso de fallo.
Ę Dispone de sofisticadas polĒticas de gesti¾n de recursos.
Ę Permite definir distintas polĒticas en funci¾n del tiempo.
Ę Incluye scripts para la gesti¾n de recursos como BBDD, servidores web, filesystems, siendo fßcil crear scripts personalizados para nuevo servicios.
LVS
LVS (Linux Virtual Server) permite crear clusters de balanceo de carga, en los que un nodo master se encarga de gestionar y repartir las conexiones entre varios nodos slave. LVS puede llegar a gestionar hasta 200 nodos slave.
Ldirectord es un daemon que se ejecuta en el nodo master LVS que se encarga de comprobar el servicio en los nodos slave y eliminarlos e insertarlos en el cluster dinßmicamente.
En la prßctica resulta un producto menos versßtil que heartbeat.
Piranha
Es el nombre de la soluci¾n de RedHat basada en LVS, a la que se ha a±adido una interfaz de usuario que facilita su configuraci¾n.
UltraMonkey
Es una variante de LVS creada por VA Linux que utiliza Heartbeat para ofrecer clusters de alta disponibilidad con balanceo de carga. En este tipo de clusters se a±ade un segundo nodo master para eliminar el SPOF de los clusters LVS.
SEGUNDA PARTE
DISEčO E IMPLEMENTACIėN
![]()
7. Estudio, anßlisis y dise±o de una soluci¾n
Una
vez explicados los distintos componentes que forman un cluster, estamos en
disposici¾n de revisar las especificaciones y concretar los requisitos de
nuestro proyecto.
El anßlisis de los requisitos nos llevarß a lo largo del proyecto a plantear varios dise±os y arquitecturas[3] posibles para el nuevo cluster, que tras implementarlos y llevar a cabo las pertinentes pruebas de integraci¾n, estabilidad y rendimiento nos conducirßn a la propuesta final.
7.1. Anßlisis del sistema inicial
En
el apartado [2.1] hemos introducido los clusters existentes en el Departamento
de LSI. A continuaci¾n realizaremos un anßlisis en profundidad de sus
componentes y su funcionamiento.
El
Departamento de LSI tiene tres clusters de computaci¾n. Cada uno de ellos era
independiente de los otros, tanto a nivel fĒsico como l¾gico. Se trata de tres
clusters del mismo del mismo tipo, diferencißndose s¾lo en el n·mero de nodos
que lo conforman.
A
nivel hardware, cada cluster estß compuesto de una serie de mßquinas (PCs
enracables) conectados a una red privada medianteĀ un switch gigabit ethernet. Una de las
mßquinas estß conectada a la red de LSI y a la red privada del cluster,
sirviendo de puerta de acceso al mismo.
A
nivel software todas las mßquinas que pertenecen a un mismo cluster cuentan con
el mismo sistema operativo y la misma imagen de kernel, requisito
imprescindible al tratarse de mßquinas con un sistema de clustering tipo SSI.
Ā
Cada
mßquina cuenta con uno o dos discos duros, en cuyo caso se configuran en modo
RAID1[4],
en los que se crea una partici¾n para datos de usuario. Esta partici¾n se
exporta al resto de mßquinas del cluster por NFS, de tal forma, que en cada
nodo del cluster tenemos N zonas NFS montadas, una por cada una de las N
mßquinas que componen el cluster.
La
figura [7.1] muestra el esquema de los clusters actuales, con un nodo de acceso
y N mßquinas dedicadas a c¾mputo y a servidor disco.
Los
motivos que nos llevan a abandonar este modelo de cluster son los siguientes:
Ę
openMosix
o
No tiene ning·n mecanismo de limitaci¾n de recursos: cualquier
usuario puede, en un momento dado, lanzar tantos procesos como quiera y saturar
un nodo o el cluster completo.
o
Presenta problemas con varios tipos de aplicaciones: el mecanismo de
migraci¾n automßtica de openMosix no funciona con aplicaciones que hacen uso de
threads o memoria compartida.
o
Estrechamente ligado al kernel: openMosix impone el kernel de los
nodos, siendo el mßs reciente de la rama 2.4, sin soporte para el hardware de
los nuevos nodos.
o
Proyecto cancelado el

Figura
7.1: Esquema de cluster openMosix de LSI
Ę
Sistema de zonas de disco NFS
o
N zonas: Cada usuario tiene tantas zonas como nodos hay en el
cluster. Se hace difĒcil controlar d¾nde estßn los datos.
o
Fragmentaci¾n del espacio: no se aprovecha correctamente todo el
espacio disponible.
o
Rendimiento de NFS: bajo
situaciones de estrķs con multitud de accesos concurrentes las zonas exportadas
por NFS tienen un rendimiento mediocre.
7.2. Revisi¾n de objetivos y requisitosĀĀ
Recordemos
que este proyecto tiene dos objetivos:
- La
implantaci¾n de un nuevo sistema de cluster para el Departamento de LSI.
- La
creaci¾n de una documentaci¾n de referencia y administraci¾n para el
Laboratorio de Cßlculo de LSI.
Tras
exponer los conceptos necesarios para entender el funcionamiento de las partes
que conforman un cluster de computaci¾n, procedemos a realizar el anßlisis de
los requisitos del nuevo sistema.
7.2.1. Requisitos funcionalesĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
Veamos
quķ servicios debe prestar el nuevo cluster.
- En
primer lugar, el nuevo cluster debe ofrecer un servicio igual al que
ofrece el sistema actual, es decir, debe ser capaz de procesar los
trabajos de los usuarios y debe disponer de un espacio de disco para
albergar sus datos y programas en un sistema de disco centralizado.
- El
middleware elegido debe ser personalizable a nivel de gesti¾n de colas,
proyectos, grupos de usuarios, etc.
- Ademßs
debe contar con un software de gesti¾n de imßgenes de sistema que permita
instalar y modificar fßcilmente el sistema en los nodos que la componen,
de forma que la instalaci¾n y posterior mantenimiento de los nodos (mßs de
50) sea asumible.
- El
cluster debe ser monitorizable, es decir, el administrador debe tener las
herramientas necesarias para controlar el estado de sus componentes y
percatarse de cualquier fallo.
7.2.2. Requisitos no funcionalesĀĀĀ
- El
nuevo cluster tambiķn debe cumplir ciertos requerimientos de eficacia y
seguridad. Concretamente debe ser capaz de soportar una mayor carga de
trabajo y debe ser capaz de mantener el servicio a pesar del fallo de
cualquiera de sus componentes.
- Como
hemos comentado, el n·mero de usuarios de los clusters ha crecido
considerablemente los ·ltimos a±os y con ellos el volumen de trabajo que
el cluster debe procesar. El nuevo sistema debe ser capaz de procesar el
volumen actual y futuro de trabajo haciendo uso del hardware disponible.
En este sentido, el aumento del volumen de trabajo por encima de cierto
umbral nunca debe llevar a un fallo en el cluster.
- El
incremento del n·mero de usuarios trae consigo una mayor necesidad de
capacidad de almacenamiento de datos. El nuevo cluster debe contar con un
sistema rßpido, no fragmentado, transparente y escalable, que pueda crecer
cuando sea necesario.
- Se establece una baterĒa de
pruebas o benchmarks (ver
apartadoĀ [19.3]) encaminados a
probar la estabilidad, el rendimiento y la usabilidad de los sistemas
propuestos.
7.3. El nuevo cluster
Una vez introducidos los conceptos necesarios y descritos los distintos componentes del nuevo sistema estamos en disposici¾n de explicitar y analizar la soluci¾n propuesta.
En primer lugar describiremos el sistema base, es decir, la infraestructura hardware y software que sustentarß el sistema de clustering. Los siguientes puntos detallarßn cada uno de los componentes y servicios un cluster de computaci¾n.
7.3.1. El sistema base
Uno de los requerimientos no funcionales del proyecto es que debemos reutilizar el hardware que conforman los tres clusters existentes.
Contamos, inicialmente, con el hardware de los tres clusters de LSI:
Ę 20 nodos de eixam
Ę 10 nodos de tenada
Ę 10 nodos de nozomi
Ę 1 switch 3Com gigabit de 48 puertos
Ę 2 switches 3Com gigabit de 16 puertos
Ę 3 Multiplexadores de puertos KVM
Ademßs de estos nodos, cada grupo habĒa comprado nodos que a·n no habĒan sido instalados porque su hardware no era compatible con el kernel de openMosix:
Ę 6 nodos de eixam
Ę 4 nodos de tenada
Ę 6 nodos de nozomi
Algunos de estos nodos cuentan con discos de gran capacidad (750GB) que utilizaremos para crear el filesystem distribuido.

Figura 7.2: El CPD de UPC en el edificio Omega
El nuevo cluster estarß ubicado en el CPD de UPC (Edificio Omega en el Campus Nord), donde se encuentran todos los servidores del Departamento de LSI. Por cuestiones de limitaci¾n de espacio llegamos a un acuerdo con los responsables de los clusters para liberar espacio retirando las mßquinas mßs obsoletas. Se retiran mßquinas Pentium IV con chasis de 2U, que ademßs son poco eficientes desde el punto de vista energķtico.
Los nodos de entrada de los tres clusters antiguos tambiķn se retiraron. Se trata de mßquinasĀ menos potentesĀ ya que, por la naturaleza descentralizada de openMosix, su ·nica funci¾n era proveer acceso a la red del cluster.
Ademßs se llega al acuerdo con los distintos grupos de investigaci¾n de comprar dos mßquinas que correrßn los servicios principalesĀ del cluster, que proporcionarßn alta disponibilidad y servirßn como punto de entrada al cluster. Ambos servidores son idķnticos, y cuentan con las siguientes caracterĒsticas:
- Dell PowerEdge R200
- Procesador Intel Xeon E3110 a 3 Ghz, 6 MB de cache
- 8 GB de memoria RAM
- 2 tarjetas de red gigabyte Ethernet
- 2 discos SAS de 450 GB
- Chasis enrackable de 1U
Todos los nodos cuentan con sistema operativo Linux Debian. La elecci¾n de esta distribuci¾n viene dada por ser el sistema operativo utilizado en todos los servidores y estaciones de trabajo Linux del Departamento de LSI. Debian es una distribuci¾n con gran tradici¾n dentro del mundo Linux, estable, con un repositorio de software importante y muy enfocado hacia el segmento de los servidores. Concretamente se ha escogido la versi¾n Etch por ser la versi¾n estable en el momento de desarrollar este proyecto.
La instalaci¾n del sistema operativo es igual en todas las mßquinas, con la ·nica diferencia de los servicios que ejecutan, que se personalizan mediante scripts creados a tal efecto.
Siempre que ha
sido posible se ha instalado el software vĒa el repositorio oficial de Debian.
El listado completo de los paquetes instalados puede encontrarse en los
apķndices [
7.3.2. Sistema de pruebas
A excepci¾n de las mßquinas compradas mßs recientemente, que no pueden correr openMosix, el resto del hardware pertenece a alguno de los tres clusters existentes. AsĒ pues, para hacer las pruebas de los distintos subsistemas del nuevo cluster crearemos una rķplica a escala de lo que serß el futuro cluster. El dise±o modular nos permitirß abstraernos del n·mero y tipo de mßquinas instaladas.
El cluster de pruebas estß formado por:
- 16 nodos Dell con procesadores Intel Xeon de doble o cußdrule n·cleo y 4 u 8 GB de memoria RAM.
- 1 switch 3Com gigabit de 16 puertos
- 1 multiplexador de puertos KVM
7.3.3. Software de clustering
Como sistema de gesti¾n para el nuevo cluster hemos elegido Sun Grid Engine, que es quizßs el sistema de colas mßs utilizado, tanto en ßmbitos empresariales como en centros de investigaci¾n.
Se trata de un producto estable, maduro, con gran tradici¾n dentro del ßmbito de la supercomputaci¾n y que cuenta con una numerosĒsima comunidad de usuarios y administradores. Se trata, en fin, de uno de los proyectos de clustering mßs vivos que ademßs es de c¾digo abierto.
7.3.4. Sistema de ficheros
Nuestra primera opci¾n como filesystem fue Lustre, de SunMicrosystems. Se trata del sistema de ficheros distribuido paralelo mßs potente y escalable disponible y se adapta perfectamente a entornos de clustering. Como veremos, las peculiaridades y limitaciones de nuestro hardware harßn que el filesystem no rinda como se esperaba y nos veremos obligados a revisar nuestra elecci¾n. El overhead del sistema software de sincronizaci¾n de discos castiga el rendimiento en exceso, motivo por el que desechamos Lustre en nuestra soluci¾n. Mßs adelante se explica con detenimiento los problemas que nos encontramos.
La segunda opci¾n fue GlusterFS, un filesystem mßs modesto, no tan escalable pero que en entornos medianos como el nuestro, y con hardware no tan dedicado, puede dar un rendimiento adecuado.
7.3.5. Alta disponibilidad
Como software de alta disponibilidad elegimos Heartbeat, que forma parte del proyecto Linux-HA y que es el sistema de alta disponibilidad mßs extendido en el mundo Linux.
Se trata de un sistema de monitorizaci¾n sencillo capaz de comprobar el status de dos hosts unidos por una conexi¾n dedicada. Su funcionamiento es simple: si la conexi¾n de uno de los hosts se interrumpe, el host que queda en funcionamiento toma el control de los servicios que han caĒdo.
Este mecanismo de monitorizaci¾n nos proporcionarß alta disponibilidad de los servicios de clustering y de sistema de ficheros, protegiķndonos ante el fallo de uno de los nodos master o de cualquiera de los nodos servidores de disco.
7.3.6. Sistema de imßgenes
Desde que pusimos en marcha el primer cluster, vimos que era necesario disponer de un sistema de replicaci¾n de imßgenes de sistema que permitiese automatizar la gesti¾n del software de las mßquinas del cluster. Instalar un nodo manualmente es un proceso tedioso que consume un tiempo, instalar N nodos de esta forma no es prßctico. La elecci¾n en su dĒa fue Rembo. Se trata de un software que permite una gran personalizaci¾n de las imßgenes gracias a su sistema de scripts y con un amplio soporte de tarjetas ethernet. Ademßs contamos con licencia de campus UPC.
En 2006 IBM adquiri¾ Rembo, incorporßndolo dentro de su suite Tivoli. Dadas las buenas experiencias obtenidas con Rembo nos decidimos a utilizar Tivoli, que tambiķn cuenta con licencia UPC.
7.3.7. Sistema de Monitorizaci¾n
El interķs de monitorizaci¾n es doble. Por una parte queremos un sistema que nos informe del estatus del cluster y que sea capaz de aglutinar toda la informaci¾n generada por la gran cantidad de elementos que lo conforman. La informaci¾n mostrada debe adaptarse tanto a las necesidades de los administradores del sistema como a los usuarios. En este sentido ganglia proporciona un interfaz web perfectamente adaptado a la idiosincrasia de los clusters, y que con algunas modificaciones se adapta perfectamente a nuestra infraestructura.
Por otra parte, como administradores de sistemas, necesitamos saber el estatus de los componentes del cluster. De poco sirve tener un sistema de alta disponibilidad con dos hosts si al caer uno de ellos no somos informados. En el Laboratorio de Cßlculo todos los servicios crĒticos se monitorizan con el sistema operativo (so), asĒ que lo que haremos serß incluir los servicios del cluster dentro del sistema de monitorizaci¾n nagios de LCLSI.
7.3.8. Servicios auxiliares
Ademßs de los componentes propios del cluster, son necesarios una serie de servicios complementarios para el correcto funcionamiento del sistema. Servicios como:
Ę Servicio de nombres, que se encarga de la correspondencia entre las direcciones IPs de los nodos y sus nombres.
Ę Servicio de correo, que permite la gesti¾n de los emails administrativos generados por los nodos de computaci¾n dentro de SunGrid.
Ę Servicio de tiempo. Configuraremos nuestro propio servidor de tiempo que mantendrß la hora de todos los nodos sincronizada.
Ę Servicio de backup. Incorporamos el espacio de disco compartido del cluster al sistema de backups departamentales.
8. Implementaci¾n
Una vez dise±ado el nuevo sistema, describiremos la implementaci¾n del dise±o propuesto.
Primero nos centraremos en el proceso de instalaci¾n y configuraci¾n de cada uno de los servicios que conformarßn el Cluster:
Ę Lustre o GlusterFS como sistema de ficheros.
Ę SunGrid como sistema de clustering.
Ę Heratbeat como sistema de alta disponibilidad.
Ę Tivoli como sistema de replicaci¾n de imßgenes.
Ę Ganglia y Nagios como sistemas de monitorizaci¾n.
Ę Otros servicios (DHCP, correo, tiempo, etc).
Cabe notar que tanto en la instalaci¾n como en la configuraci¾n de cada uno de estos componentes seguiremos una serie de reglas:
Ę Siempre que sea posible utilizaremos el software proporcionado por el sistema operativo, lo que nos permitirß mantener el software actualizado fßcilmente.
Ę Todo el software adicional com·n se instalarß en un directorio dentro de /usr/local, accesible en cada nodo para todos los usuarios.
Ę Los distintos componentes del cluster se instalarßn de forma independiente y lo mßs aislados posibles del resto del sistema operativo. Esto nos permitirß actuar en cada uno de ellos sin afectar al resto.
Ę Se tratarß de independizar el cluster, en la medida de lo posible, del resto de servicios del Departamento, lo que nos proporcionarß una robustez a±adida.
9. Lustre
9.1. Arquitectura propuesta (versi¾n 1.0)
Uno de los objetivos del nuevo cluster es proporcionarĀ a los usuarios un espacio de disco unificado, solucionando el problema de zonas de usuario fragmentadas en el modelo de los clusters anteriores. En este volumen ·nico, que serß visible desde todos los nodos del cluster, los usuarios guardarßn sus programas, datos, salidas de procesos, etc.
Todas las mßquinas del cluster cuentan con un espacio de disco libre que va desde los 60 GB en las mßquinas mßs antiguas con discos de 80 GB hasta mßs de 700 GB en las mßquinas mßs modernas. El espacio total resultante de sumar todos estos vol·menes da como resultado una cantidad de disco considerable.
Lustre como sistema de ficheros paralelo permite crear un volumen unificado a partir de diferentes espacios de disco heterogķneo accesible por conexiones TCP/IP. Estos espacios de disco pueden ser NAS, SAN o, como en nuestro caso, hosts con discos locales.
Un sistema Lustre cuenta con tres unidades funcionales principales:
1. Un metadata target (MDT) por filesystem que almacena metadatos, como nombres de ficheros, directorios, permisos y file layout en el metadata server (MDS).
2. Uno o mßs object store targets (OSTs) que guardan los datos de los ficheros en uno o mßs object storage servers (OSSs). Dependiendo del hardware de los servidores, un OSS normalmente sirve entre dos y ocho targets, con cada target un sistema de ficheros en disco local con hasta 8 terabytyes de tama±o. La capacidad de un sistema Lustre es la suma de las capacidades de los targets.
3. Cliente(s) que acceden y usan los datos.
MDT, OST y cliente pueden estar en distintos nodos o en el mismo. En general estas funciones se separan en nodos distintos, de dos a cuatro OSTs por nodo OSS. Lustre soporta varios tipos de redes, incluyendo Infiniband, TCP/IP en ethernet, Myrinet, Quadrics y otras tecnologĒas propietarias.
El MDT y los OSTs pueden contar con un nodo configurado como failover que es capaz de acceder a sus datos en caso de que el nodo servidor falle.
La figura [4.2] en el apartado [4.3.2] muestra el esquema de un cluster
Lustre complejo, con diversos OSSs con OSTs albergados en SANs, sistemas de
failover, etc.
La alta disponibilidad es uno de los objetivos que nos hemos marcado a la hora de dise±ar el nuevo espacio de disco. Aprovechando las facilidades que proporciona Lustre, dotaremos de alta disponibilidad tanto al MDT como a los distintos OSTs. En nuestro caso esto implica tener dos hosts sirviendo el MDT y otros dos por cada OST. El segundo host, configurado como failover, debe ver el mismo disco que el host primario para ser capaz, en caso de fallo de ķste, de tomar el control y continuar sirviendo disco.
Lo mßs habitual en sistemas de alto rendimiento es disponer de un SAN (Storage Area Network) conectado a dos hosts. El SAN en estos casos cuenta con varias controladoras que permiten su conexi¾n a distintos hosts. Los hosts se configuran como primary y failover. El nodo primary es el que sirve el disco a la zona Lustre. En caso de caĒda del nodo primary, Lustre se darß cuenta y automßticamente comenzarß a utilizar el nodo failover.
En nuestro
caso utilizaremos los discos locales de las mßquinas como espacio de disco
compartido. Agruparemos las mßquinas del clusterĀ por parejas. Habrß una pareja que sirva el
MDT y el resto de parejas servirßn OSTs.
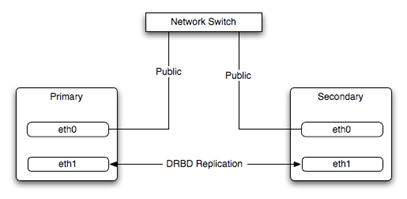
Figura
9.1: Esquema de dos hosts con replicaci¾n de datos vĒa conexi¾n de red dedicada
Cada uno de los hosts tienen acceso solamente a su disco local, y Lustre s¾lo "habla" con el host que act·a como primario. Es necesario alg·n mecanismo adicional que replique los datos que se escriben en el host primario al failover. Es mßs, esos datos deben mantenerse estrictamente sincronizados para evitar problemas de incoherencia de datos. En este sentido DRBD (Distributed Replicated Block Device) nos proporciona un mecanismo transparente de replicaci¾n de bloques entre dispositivos, particiones de discos duros en este caso, que se encuentran en hosts conectados por red. Algunas caracterĒsticas de DRBD son:
ĀĀĀĀĀĀĀĀĀĀĀ
Ę Trabaja en tiempo real. La replicaci¾n de datos es continua, mientras las aplicaciones modifican el contenido del dispositivo.
Ę Es transparente. Las aplicaciones que trabajan en el dispositivo replicado no son conscientes de que los datos estßn en varios servidores.
Ę La replicaci¾n puede ser sĒncrona o asĒncona.Ā Trabajando de forma sĒncrona, las escrituras por parte de aplicaciones se consideran finalizadas s¾lo cuando la escritura se ha realizado en los dos servidores que conforman el dispositivo replicado. La replicaci¾n asĒncrona implica que las escrituras se consideran finalizadas cuando se han completado de forma local, antes de que se hayan propagado al peer.
Dos hosts compartiendo un dispositivo de bloques DRBD juegan roles primary y secondary. El host primaryĀ es el host que monta el dispositivo DRBD y es sobre su disco fĒsico local sobre el que se realizan las lecturas. Las escrituras se realizan en primer lugar en el disco del host primary y posteriormente en el host secondary. En nuestro caso configuraremos DRBD en modo sĒncrono, de tal forma que una escritura no se considerarß realizada hasta que no se haya realizado en los discos de los hosts primary y secondary.
Los roles primary y secondary se corresponden con los roles primary y failover de Lustre.

Figura
9.2: Arquitectura del cluster con Lustre (versi¾n 1.0)
La replicaci¾n de datos entre parejas de hosts se realizarß utilizando una conexi¾n de red dedicada, tal y como se muestra en la figura [9.2]. Todos los nodos del cluster cuentan con al menos 2 interfaces de red gigabit ethernet. La interconexi¾n de los hosts de cada pareja mediante una conexi¾n de este tipo permite que la sincronizaci¾n de datos se realice de forma ¾ptima, sin ocupar el ancho de banda de la red privada del cluster.
Como hemos comentado anteriormente, Lustre es capaz de detectar el fallo de un servidor, ya sea de un MDT o de un OST, y utilizar en su lugar un host configurado como failover. En el caso por ejemplo de un OST formado por dos hosts en configuraci¾n failover sirviendo el disco de un SAN, si fallase el host primary, el host failover tendrĒa acceso de forma "automßtica" al SAN y Lustre pasarĒa a comunicarse con ķl. En nuestro caso, con las zonas replicadas con DRBD, necesitamos un mecanismo extra que nos permita detectar el fallo del host primary y que, en caso de fallo, configure el host seconday como primary y monte la zona DRBD. Heartbeat, tratado en el capĒtulo [12], permite monitorizar el estatus de servicios de alta disponibilidad y ejecutar scripts que los activen/desactiven.
9.2. Instalaci¾n (versi¾n 1.0)
9.2.1.Ā DRBD
La funcionalidad principal de DRBD estß implementada como m¾dulo del kernel. Concretamente, DRBD proporciona un driver para un dispositivo de bloques especial.
La ·ltima versi¾n disponible es la 8.2.6, que podemos descargar de la url:
http://oss.linbit.com/drbd/8.2/drbd-8.2.6.tar.gz
Como con todo el software que instalamos y que no viene con la distribuci¾n de software del sistema operativo, dejamos copia en /root/files.
Compilamos e instalamos el software:
master-cluster1>
tar xvfz drbd-8.2.6.tar.gz
master-cluster1>
cd drbd-8.2.6/drbd
master-cluster1> make && make install
El m¾dulo de kernel queda instalado en el directorio correspondiente a dispositivos de bloques en /lib/modules y las utilidades de administraci¾n en /sbin.
Comprobamos que el m¾dulo carga correctamente:
master-cluster1> modprobe drbd
El siguiente mensaje indica que el m¾dulo se ha cargado:
drbd:
initialised. Version: 8.2.6 (api:88/proto:86-88)
Para automatizar el proceso de carga del m¾dulo drbd al iniciar el sistema, lo incluimos en el fichero /etc/modules.
9.2.2. Lustre
Lustre estß dividido en tres partes:
- Parches de kernel
- M¾dulo de kernel
- Utilidades de espacio de usuario
El primer paso es disponer de un kernel con los parches necesarios para Lustre. Sun nos ofrece la posibilidad de instalar alguno de sus kernels precompilados oĀ modificar nuestro kernel con sus parches. En nuestro caso preferimos adecuar nuestro kernel3 (2.6.18-5) a Lustre en lugar de instalar un nuevo kernel, la cualĀ cosa nos darß mßs juego en caso de tener que realizar futuros ajustes en el mismo.
El software necesario estß disponible en la web de Sun:
https://cds.sun.com/is-bin/INTERSHOP.enfinity/WFS/CDS-CDS_SMI-Site/en_US/-/USD/ViewProductDetail-Start?ProductRef=LUSTRE-1651-G-F@CDS-CDS_SMI
Como queremos parchear nuestro propio kernel, seleccionamos la plataforma Source y descargamos el fichero "Lustre source code - lustre-1.6.5.1.tar.gz".
Descomprimimos el c¾digo fuente de Lustre:
master-cluster1> tar xvfz lustre-1.6.5.1.tar.gz -C /tmp
Los parches Lustre se instalan con la herramienta de gesti¾n de parches quilt. La instalamos:
master-cluster1> apt-get install quilt
Copiamos el
fichero con la configuraci¾n del kernel[5]
(versi¾n
master-cluster1> cp
lustre/kernel_patches/kernel_configs/kernel-2.6.18-2.6-vanilla-i686.config
/usr/src/linux/
Creamos sendos soft-links que utilizarß quilt para parchear nuestro kernel:
master-cluster1>
cd /usr/src/linux
master-cluster1>
ln -s /tmp/lustre-
1.6.5.1/lustre/kernel_patches/series/
master-cluster1>
ln -s
/tmp/lustre-1.6.5.1/lustre/kernel_patches/patches patches
Ahora aplicamos los parches indicados en el fichero series:
master-cluster1> quilt push -av
Una vez aplicados los parches debemos recompilar el kernel:
master-cluster1>
make && make modules_install
Generamos el ramdisk del kernel que acabamos de compilar:
master-cluster1> mkinitramfs -o /boot/linux-
Por ·ltimo hacemos este sea el kernel de arranque por defecto. A±adimos una nueva entrada en el gestor de arranque GRUB. El fichero de configuraci¾n /boot/grub/menu.lst puede encontrarse en los apķndices [19.1.1].
Rebotamos la mßquina y comprobamos que el nuevo kernel se carga correctamente y que todos los dispositivos se reconocen.
El siguiente paso es compilar el m¾dulo Lustre y las utilidades de gesti¾n:
master-cluster1>
cd/tmp/lustre-1.6.5.1
master-cluster1>
./configure --prefix=/
master-cluster1>
make && make install
Para hacer que el m¾dulo Lustre se cargue automßticamente, creamos un fichero lustre en /etc/modutils con el fin de que la herramienta update-modules cree la informaci¾n necesaria en /etc/modules.conf:
options lnet
networks="tcp"
options ost
oss_num_threads=4
options mds
mds_num_threads=10
En este fichero debemos indicar el tipo de red que utilizarß lnet para comunicar los hosts Lustre:
options lnet networks="tcp"
Para comprobar que el fichero modules.conf incluye correctamente la informaci¾n de los m¾dulos Lustre ejecutamos el comando update-modules, que se ejecuta cada vez que se inicia el sistema:
master-cluster1>
update-modules.modutils
9.3. Configuraci¾n (versi¾n 1.0)
9.3.1. Consideraciones previas
Una vez instalado el m¾dulo de kernel y las utilidades, debemos configurar el recurso DRBD. En primer lugar, debemos asegurarnos de que la replicaci¾n se realizarß sobre dispositivos de idķntico tama±o. El sistema de distribuci¾n de imßgenes Tivoli junto con el script de personalizaci¾n de imagen nos asegura contar con parejas de nodos con una partici¾n home del mismo tama±o (ver capĒtulo [13]).
Tambiķn contamos con un interfaz de red dedicado a la sincronizaci¾n de datos del dispositivo DRBD. El script de personalizaci¾n de sistema se encarga de configurar este interfaz en cada mßquina asignßndole la direcci¾n IP correspondiente seg·n juegue el rol primary o secondary.
9.3.2. DRBD
La configuraci¾n de DRBD reside en /etc/drbd.conf. Este fichero cuenta con varias secciones a configurar: global, common y resources, en las que se definen los recursos a replicar. Este fichero puede encontrarse en los apķndices [19.1.2].
En la secci¾n resource definimos un recurso denominado r0 que estß formado por la partici¾n RAID1 /dev/md2 de los nodos 1 y 2. La comunicaci¾n entre los nodos se establece por el interfaz dedicado y el puerto especificado.
Tras configurar el recurso correctamente, procedemos a crear e inicializar el dispositivo drbd. Para ello, debemos seguir los siguientes pasos en todos los nodos:
1. Creamos el dispositivo:
nodei> drbdadm create-md r0
2. Asociamos el recurso DRBD con su dispositivo fĒsico:
nodei> drbdadm attach r0
3. Conectamos el recurso DRBD con su compa±ero:
nodei> drbdadm connect r0
Comprobamos en /proc/drbd el estatus del recurso r0:
nodei>
cat /proc/drbd
version: 8.2.4 (api:88/proto:86-88)
GIT-hash: fc00c6e00a1b6039bfcebe37afa3e7e28dbd92fa build by buildsystem@linbit, 2008-01-11 12:44:36
0: cs:Connected st:Secondary/Secondary ds:Inconsistent/Inconsistent C r---
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0
resync: used:0/31 hits:0 misses:0 starving:0 dirty:0 changed:0
act_log: used:0/257 hits:0 misses:0 starving:0 dirty:0 changed:0
Como vemos en los logs ambos dispositivos del recuso estßn configurados como secondary. El siguiente paso establece el nodo que jugarß el rol de primary en la pareja DRBD e inicia la sincronizaci¾n entre ellos. Debe ejecutarse s¾lamente en los nodos primary:
nodei> dbdadm -- --overwrite-data-of-peer primary
r0
Tras ejecutar este comando comienza la sincronizaci¾n, que puede ser monitorizada vĒa /proc/drbd:
nodei> cat /proc/drbd
version: 8.2.6
(api:88/proto:86-88)
GIT-hash:
3e69822d3bb4920a8c1bfdf7d647169eba7d2eb4 build by root@master-cluster1,
Ā1: cs:Connected st:Primary/Secondary
ds:UpToDate/UpToDate C r---
ns:14596512 nr:0 dw:14351652 dr:887881 al:59 bm:39 lo:0 pe:0 ua:0 ap:0 oos:0
Despuķs de ejecutar este comando el dispositivo drbd ya es completamente funcional, eso sĒ, con un rendimiento reducido mientras dura la sincronizaci¾n. El siguiente paso es formatear el dispositivo para crear el filesystem; en nuestro caso Lustre.
9.3.3. Lustre
Debido al requisito de alta disponibilidad en todos los puntos del filesystem, el MDT estarß formado por dos MDS, master-cluster1 y master-cluster2.
En primer lugar formateamos el MDT desde el MDS activo (master-cluster1):
master-cluster1>
mkfs.lustre --fsname=lustrefs --mdt
--mgs --failnode=master-cluster2
/dev/drbd0
Una vez la zona estß formateada, montamos la zona MDT:
mastercluster1>
mount -t lustre /dev/drbd0
/mnt/lustrefs/mdt
Para cada uno de los 7 OSTs procedemos de forma anßloga. En primer lugar formateamos el dispositivo DRBD de los nodos primary (node1, node3, node5 y node7) y posteriormente montaremos la zona:
nodei> mkfs.lustre --fsname=lustrefs
--mgsnode=master-cluster1,master-cluster2 --ost --failnode=node2 /dev/drbd0
nodei> mount -t lustre /dev/drbd0
/mnt/lustrefs/ost
Cada vez que se monta un nuevo OST, el MDT lo reconoce como propio (mismo fsname) y lo agrega al filesystem. Desde el momento que formateamos el primer OST estamos en disposici¾n de montar la zona lustre en los nodos cliente.
9.4. Pruebas (versi¾n 1.0)
Una vez nuestro filesystem paralelo es funcional, procedemos a realizar las pruebas pertinentes, tal y como estß descritas en el apartado [19.3].
9.4.1. Test de estabilidad
Durante la fase de pruebas del filesystem nos encontramos con importantes problemas de estabilidad que provocaban la pķrdida del control sobre el filesystem, obligando a reiniciar los servicios Lustre, y en ocasiones la totalidad del sistema a las 24 horas aproximadamente de funcionamiento intensivo.
Los problemas eran fßcilmente reproducibles mediante el acceso concurrente de lectura y escritura a los datos por parte de varias decenas de procesos. Iniciada la situaci¾n de estrķs era cuesti¾n de horas que el filesystem se quedase inestable.
Probamos varias versiones de kernel y de utilidades Lustre, pero el problema persistĒa. Finalmente, tras consultar extensivamente los foros oficiales, encontramos un artĒculo sobre Lustre que indicaba que la combinaci¾n servidor OST y cliente en un mismo nodo no es una configuraci¾n estable. Los nodos cliente, que montan el filesystem, no pueden realizar funciones de OSS.
Esto nos hizoĀ replantearnos la arquitectura de nuestro sistema de pruebas, puesto que la estabilidad es un requisito fundamental.
Por otra parte como pudimos comprobar, el hecho de disponer los nodos de computaci¾n como mßquinas servidoras de disco Lustre, a±ade un overhead de uso de CPU, memoria y red que perjudicarĒa el rendimiento del trabajo de los usuarios en un entorno de computaci¾n.
9.5. Revisi¾n de la arquitectura (versi¾n 1.1)
Los graves problemas de estabilidad descritos en el apartado anterior nos obligan a replantearnos la arquitectura de nuestro filesystem paralelo. Los nodos servidores de disco deben ser nodos dedicados.
A tal efecto configuramos seis mßquinas provenientes del antiguo cluster eixam que iban a ser retiradas. Se trata de mßquinas con unos 5 a±os de antig³edad, con prestaciones a nivel de c¾mputo muy inferiores a las ·ltimas adquiridas, pero que pueden jugar un papel correcto como servidoras de disco.
Las seis mßquinas son idķnticas y cuentan con las siguientes caracterĒsticas:
Ę Procesador: Intel Pentium IV 3.0 Ghz
Ę Memoria: 4 GB RAM
Ę Disco: 2 discos SATA de 750 GBytes
Ę Red: 2 tarjetas de red gigabyte Ethernet
Ę Chasis: Enracable 2U
AsĒ pues todos los nodos con los que contßbamos anteriormente dejan de servir disco y pasan a ser exclusivamente clientes de la zona de disco paralela formada por las 6 mßquinas dedicadas.
El nuevo modelo se muestra en la figura [9.3].
Figura 9.3: Arquitectura revisada del cluster con LustreĀ (versi¾n 1.1)
9.6. Pruebas del nuevo modelo (versi¾n 1.1)
9.6.1. Test de estabilidad
Una vez separados los nodos servidores de disco de los nodos cliente, los problemas de estabilidad desaparecieron. El nuevo modelo se mostr¾ estable ejecutando el test de estrķs por periodos de tiempo de una semana. De esta forma pudimos centrarnos en las pruebas de rendimiento y usabilidad.
9.6.2. Pruebas de rendimiento
Las pruebas de rendimiento se basaron, por una parte, en una serie de tests sintķticos de rendimiento te¾rico, que nos proporcionarĒa el rendimiento pico mßximo. Por otra parte realizamos pruebas de estrķs basadas en la ejecuci¾n masiva de procesos con lecturas y escrituras concurrentes. Los detalles de las distintas pruebas de rendimiento se explican en el apartado [19.3.2].
9.6.2.1. Throughput mßximo
En primer lugar mostramos el throughput mßximo arrojado por la pruebas de lecturas y escrituras sobre el filesystem Lustre:
|
N·mero de instancias |
MB/s en lectura |
MB/s en escritura |
|
1 |
45.5 |
18.7 |
|
2 |
90.3 |
36.1 |
|
3 |
135.1 |
54.2 |
|
4 |
133.0 |
49.5 |
|
5 |
129.2 |
46.4 |
Como era de esperar las pruebas de rendimiento con Lustre arrojan resultados muy buenos, superando a partir de 2 instancias concurrentes el rendimiento de un disco local. El througput escala linealmente con el n·mero de OSTs. Dado que disponemos de 3 OSTs las lecturas y escrituras se realizan en 3 nodos (parejas de nodos) en paralelo.
|
|
|
Figura
9.4: Throughput de lectura y escritura del filesystem Lustre
Podemos estimar que el mßximo throughput te¾rico serĒa la velocidad deĀ un OST multiplicado por el n·mero de OSTs, que en nuestro caso serĒan 135.5 MB/s para las lecturas y 56.1 MB/s para las escrituras. Como podemos ver, los resultados con distintas concurrencias se aproximan a los mßximos te¾ricos, confirmando la excelente escalabilidad de Lustre.
Las escrituras estßn penalizadas, sin duda alguna, por el sistema de replicaci¾n utilizado. Recordemos que los datos escritos en un OST se envĒan al nodo primary y ķste los reenvĒa a su vez al nodo secondary de forma sĒncrona mediante DRBD. De todas formas las tasas de escritura son mßs que correctas y superan con creces las que puede ofrecer un sistema tipo NFS.
9.6.2.2. Test ad-hoc
El siguiente test consiste en la ejecuci¾n concurrente de procesos con un alto uso de E/S. La descripci¾n de la baterĒa de pruebas puede consultarse en los apķndices [19.3.2.2].
A continuaci¾n
mostramos los resultados obtenidos correspondientes a ejecutar un determinado
n·mero de procesos de lectura:
|
Concurrencia |
Tiempo |
Throughput agregado (MB/s) |
MB/s por proceso |
|
1 |
47.0ÆÆ |
104.5 |
104.5 |
|
2 |
|
206.4 |
103.2 |
|
3 |
|
303.9 |
101.3 |
|
6 |
|
300.0 |
50.0 |
|
9 |
|
292.5 |
32.5 |
|
18 |
|
264.3 |
14.6 |
|
36 |
|
215.2 |
5.9 |
Las cifras de throughput agregado demuestran la alta escalabilidad del filesystem Lustre. Dado que contamos con 3 OSTs el rendimiento mßximo esperado seria de 104.5 * 3 = 313.5 MB/s. Cuando la concurencia aumentaĀ las cifras de throughput agregado se siguen manteniendo bastante estables.
|
|
|
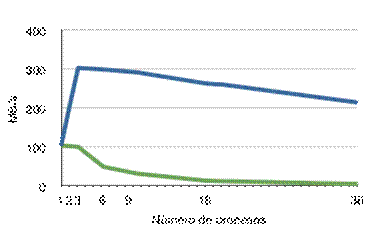
Figura 9.5: Throughput del filesystem Lustre en lecturas
Las pruebas de escritura arrojan los siguientes resultados:
|
Concurrencia |
Tiempo |
Throughput agregado (MB/s) |
MB/s por proceso |
|
1 |
|
19.0 |
19.0 |
|
2 |
|
37.3 |
18.6 |
|
3 |
|
54.7 |
18.2 |
|
6 |
|
52.3 |
8.71 |
|
9 |
|
51.5 |
5.72 |
|
18 |
|
49.7 |
2.76 |
|
36 |
|
46.8 |
1.3 |
De nuevo tenemos resultados muy estables a lo largo de todas las pruebas.
El throughput agregado se mantiene estable cerca del mßximo te¾rico, limitado
por el sistema de replicaci¾n DRBD.
|
|
|
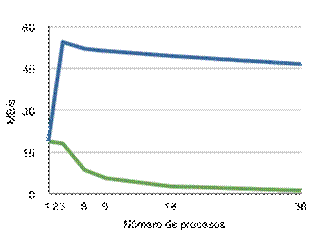
Figura
9.6: Throughput del filesystem Lustre en escrituras
9.6.3. Pruebas de usabilidad
Por ·ltimo las pruebas de usabilidad sirvieron para medir el grado de interactividad de los usuarios con la zona de disco compartido mientras el sistema estaba sometido a distintos niveles de carga de trabajo.
El uso conjunto del sistema de replicaci¾n de bloques DRBD y Lustre hacen crecer el tiempo de proceso y la latencia de ciertas llamadas al sistema sobre ficheros a niveles no asumibles.
Concretamente, un sistema como el nuestro sometido a una carga de 36 procesos simultßneos leyendo y escribiendo, tarda del orden de 10 segundos en procesar el comando ls sobre la zona compartida y entre 10 y 20 segundos en hacer un close de un fichero.
Esta falta de interactividad nos lleva a desechar la soluci¾n Lustre+DRBD. De todas maneras, en caso de incorporar alg·n dĒa un SAN al cluster, liberados de la necesidad de utilizar DRBD, volverĒamos a evaluar la posibilidad de utilizar Lustre como filesystem. Esta mejora se ha planteado en el apartado [18.3.3].
10. GlusterFS
10.1. Arquitectura propuesta (versi¾n 2.0)
Los problemas de rendimiento de la soluci¾n Lustre + DRBD nos obligaron a revisar nuestra elecci¾n de filesystem. Tras analizar varias opciones nos decantamos por GlusterFS, por tratarse de un sistema de ficheros paralelo con una caracterĒstica muy interesante: AFR (Automatic File Replication). AsĒ como Lustre es un filesystem de un rendimiento y una escalabilidad de primer nivel, la inclusi¾n del sistema de replicaci¾n de bloques DRBD hacĒa que el filesystem en su conjunto adoleciese de latencias altas en escenarios de estrķs de disco y en operaciones de apertura/cierre de fichero.
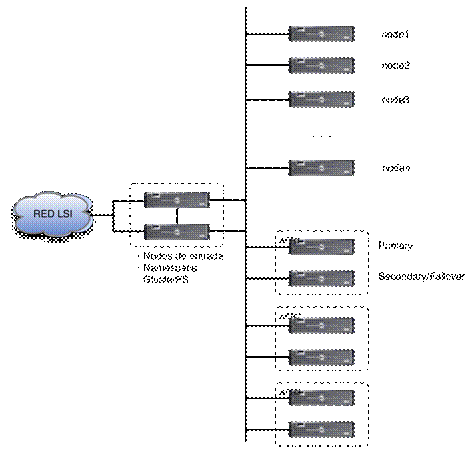
Figura
10.1: Arquitectura del cluster con GlusterFS (versi¾n 2.0)
AFR es un translator que permite que un brick[6] o unidad de almacenamiento estķ compuesto por mßs de un disco (en hosts distintos, por supuesto). La replicaci¾n de datos se hace de forma transparente, iniciada por los nodos clientes, que configurando vol·menes AFR, indican de forma explĒcita sobre quķ nodos se va a realizar la replicaci¾n de datos.
Los datos se escriben a la vez en los dos nodos que conforman un AFR, al contrario de lo que sucedĒa con DRBD, donde los datos se enviaban al nodo primario y este los reenviaba al secundario.
GlusterFS tiene la misma limitaci¾n que Lustre en cuanto a montar el filesystem en un host servidor de disco. Los problemas de estabilidad nos llevan a decantarnos una vez mßs por una soluci¾n con nodos dedicados a servir disco, similar al modelo de cluster versi¾n 1.1.
Con este fin, al igual que en la revisi¾n del sistema Lustre, contamos con 6 mßquinas dedicadas en exclusiva a servir disco. La figura [10.1] muestra el esquema del cluster con GlusterFS (versi¾n 2.0).
Ademßs de las mßquinas servidoras de disco, GlustrerFS necesita una mßquina que se encargue de almacenar el namespace del filesystem. Guardaremos el namespace en las mßquinas master-cluster, replicado utilizando AFR.
Las mßquinas servidoras de disco se agruparßn por parejas, replicando por AFR la zona de disco que exportan. Los nodos clientes configurarßn el filesystem global unificando el sumatorio de las tres zonas AFR y utilizando el namespace del AFR de las mßquinas master-cluster.
10.2. Instalaci¾n (versi¾n 2.0)
Obtenemos la ·ltima versi¾n[7] de GlusterFS de su web:
http://ftp.zresearch.com/pub/gluster/glusterfs/CURRENT/
Descomprimimos y compilamos el c¾digo fuente:
master-cluster1>
tar xfz glusterfs-1.3.9.tar.gz -C /tmp
master-cluster1>
cd /tmp
master-cluster1>
./configure --prefix=/
master-cluster1> make && make install
Las utilidades quedan instaladas en /sbin, los ficheros de configuraci¾n en /etc y los logs en /var/log/glusterfs.
GlusterFS utiliza FUSE (Filesystem in Userspace) para montar las zonas, por lo que es necesario contar con soporte en el kernel. La configuraci¾n por defecto de Debian soporta FUSE, por lo que no son necesarias instalaciones adicionales.
10.3. Configuraci¾n (versi¾n 2.0)
10.3.1 Servidores
Cada uno de los seis nodos servidores de disco cuenta con dos discos de 750 GB, que tras instalar sistema y swap nos dejan una partici¾nĀ exportable de unos 700GB. Lo habitual en nuestros servidores es utilizar una configuraci¾n RAID1 que permita el fallo de un disco sin pķrdida de datos. En el caso del sistema GlusterFS con AFR los datos de cada nodo ya estßn replicados en su peer, por lo que optamos por una configuraci¾n RAID0[8]. De esta manera no se pierde espacio y el acceso al volumen resultante es mßs rßpido.
Creamos el raid en cada nodo servidor:
node1> mdadm --create /dev/md2 --level=0
--raid-devices=2 /dev/sda3 /dev/sdb3
Comprobamos que el raid se ha creado correctamente:
node1> cat /proc/mdstat
Personalities :
[linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md2 : active
raid0 sda3[1] sdb3[0]
1417045248 blocks 64k chunks
El siguiente paso es formatear y montar la partici¾n que exportaremos:
node1> mke2fs -j /dev/md2
node1> mount /dev/md2 /mnt/glusterfs/home
Una vez disponemos de la zona de disco que queremos exportar, configuramos el lado servidor de GlusterFS, que serß idķntico en todos los nodos servidores de disco. La estructura del fichero de configuraci¾n es la siguiente:
Recurso a exportar
Translator 1
Translator 2
ģ
Translator n
Definici¾n del volumen servidor
El fichero de configuraci¾n de los nodos servidores de GlusterFS se puede encontrar en los apķndices [19.1.3].
La primera declaraci¾n en el fichero de configuraci¾n indica sobre quķ directorio vamos a trabajar. Las siguientes declaraciones son distintos translators[9] que aportan soporte para bloqueo de ficheros (posix-locks) e introducen mejoras de rendimiento (iothreads, wb, ra). La declaraci¾n server indica quķ zona se va a exportar, el transporte utilizado y las restricciones de acceso.
Por ·ltimo s¾lo queda lanzar el demonio GlusterFS con la configuraci¾n que hemos creado:
node1> /sbin/glusterfsd -f
/etc/glusterfs/glusterfs-server.vol
10.3.2. Namespace
A continuaci¾n guardaremos el namespace de la zona de usuario GlusterFS en los dos nodos master. Ambos nodos contarßn con una partici¾n idķntica en la que, por AFR, se replicarß el namespace.
Los nodos master cuentan con dos discos de 500GB. Creamos una partici¾n de 200 GB[10] en cada uno de los discos para, posteriormente crear un volumen RAID0 en las dos mßquinas master:
master-cluster1>
mdadm --create /dev/md2 --level=0
--raid-devices=2 /dev/sda3 /dev/sdb3
Formateamos y montamos el dispositivo, utilizando ext3 por ser un filesystem con journaling y ampliamente soportado por herramientas de recuperaci¾n de datos.
master-cluster1>
mke2fs -j /dev/md2
master-cluster1>
mount /dev/md2 /mnt/glusterfs/home-ns
Configuramos el servidor GlusterFS en los nodos master-cluster. La configuraci¾n serß idķntica en los dos nodos:
volume brick-ns
type
storage/posix
option
directory /mnt/glusterfs/home-ns
end-volume
volume server
type
protocol/server
subvolumes
brick-ns
option
transport-type tcp/server
option
auth.ip.brick-ns.allow *
end-volume
Arrancamos el servidor GlusterFS en los dos nodos master-cluster:
master-cluster1>
/sbin/glusterfsd -f
/etc/glusterfs/glusterfs-server.vol
Despuķs de estos pasos ya tenemos el lado servidor de la zona GlusterFS configurado.
10.3.3. Clientes
En un sistema GlusterFS los servidores exportan recursos, ya sea zonas de disco o namespace, sin saber el destino que se les va a dar o quķ exportan el resto de servidores. La comunicaci¾n inter-servidor no existe. Son los clientes los que agreganĀ los recursos que exportan los servidores para crear vol·menes grandes.
En nuestro caso la configuraci¾n de todos los nodos clientes serß idķntica. Se crearß un volumen formado por tres AFRs, que serßn parejas de nodos servidores: disc1+disc2, disc3+disc4 y disc5+disc6. El namespace serß el AFR formado por la zona exportada por master-cluster1+master-cluster2.
El fichero de configuraci¾n de los nodos clientes puede consultarse en los apķndices [19.1.4].
En primer lugar describimos todos los recursos que vamos a utilizar, definidos como client0-ns y client1-ns (namespaces) y client1,..,client6 (servidores de disco). Posteriormente definimos los vol·menes AFRs y su composici¾n. Finalmente creamos un volumen que unifica los tres AFRs y el namespace. Este volumen serß la zona de disco que verßn todos los clientes que monten la zona GlusterFS.
En la definici¾n indicamos que la polĒtica de escritura serß round-robin, que establece el orden de escritura de los ficheros de forma cĒclica entre los AFRs (AFR1→AFR2→AFR3→AFR1→ģ), ademßs dejamos un mĒnimo de un 1% de espacio libre en cada AFR.
Ya estamos en disposici¾n de lanzar el cliente GlusterFS, que montarß el volumen reciķn configurado. Como segundo parßmetro indicamos el punto de montaje del volumen:
master-cluster1>
/sbin/glusterfs -f
/etc/glusterfs/glusterfs-client.vol /home
10.4. Pruebas
10.4.1. Test de estabilidad
Una vez separados los nodos servidores de disco de los nodos cliente, los problemas de estabilidad desaparecieron. El nuevo modelo se mostr¾ estable ejecutando el test de estrķs por periodos de tiempo de una semana. De esta forma pudimos centrarnos en las pruebas de rendimiento y usabilidad del nuevo modelo.
10.4.2. Pruebas de rendimiento
Las pruebas de rendimiento se basaron, por una parte, en una serie de tests sintķticos de rendimiento te¾rico, que nos proporcionarĒa el rendimiento pico mßximo. Por otra parte realizamos pruebas de estrķs basadas en la ejecuci¾n masiva de procesos con lecturas y escrituras concurrentes. Los detalles de las distintas pruebas de rendimiento se explican en el apartado [19.3.2].
10.4.2.1. Throughput mßximo
En primer lugar, mostramos las cifras de throughput mßximo arrojado por la pruebas de lecturas y escrituras concurrentes con el comando dd:
|
N·mero de instancias |
MB/s en lectura |
MB/s en escritura |
|
1 |
42.3 |
39.3 |
|
2 |
83.2 |
59.7 |
|
3 |
118.9 |
80.9 |
|
4 |
119.2 |
77.9 |
|
5 |
119.1 |
73.6 |
Como podemos ver los resultados de las pruebas de lectura son muy buenos. El filesystem escala linealmente con el n·mero de AFRs.
En el caso de las escrituras, el throughput mßximo te¾rico puede enviar cada nodo cliente es de 62 MB/s, que corresponde a la mitad de la capacidad de nuestra red. Recordemos que nuestro filesystem hace uso del translator AFR como mecanismo de replicaci¾n de datos. Con AFR los nodos clientes envĒan los datos duplicados por la red, una copia para cada uno de los nodos de cada AFR.
|
|
|
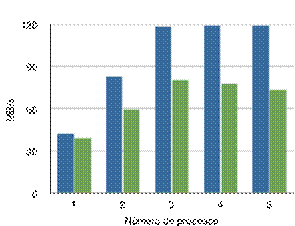
Figura 10.2: Throughput de lectura y escritura con GlusterFS
AFR proporciona por un lado un mecanismo sencillo de alta disponibilidad, pero por otro lado limita la tasa de escritura de cada nodo cliente a la mitad. De todas formas 62 MB/s es una cifra muy buena, cercana a la capacidad de escritura mßxima de un disco local.
El uso de la red por parte de Lustre es mucho mßs racional. Los datos que se escriben en el filesystem se envĒa por la red una sola vez, y se delega la posible replicaci¾n al backend de almacenamiento, en nuestro caso la pareja de nodos con replicaci¾n DRBD.
10.4.2.2. Test ad-hoc
El siguiente test consiste en la ejecuci¾n concurrente de procesos con un alto uso de E/S. La descripci¾n de la baterĒa de pruebas puede consultarse en los apķndices [19.3.2.2].
A continuaci¾n mostramos los resultados obtenidos correspondientes a ejecutar un determinado n·mero de procesos de lectura:
|
Concurrencia |
Tiempo |
Throughput agregado (MB/s) |
MB/s por proceso |
|
1 |
48.5ÆÆ |
101.3 |
101.3 |
|
2 |
|
199.8 |
99.9 |
|
3 |
|
285.2 |
95.0 |
|
6 |
|
267.4 |
44.5 |
|
9 |
|
243.3 |
27.0 |
|
18 |
|
219.0 |
12.16 |
|
36 |
|
171.6 |
4.7 |
Los resultados no distan mucho de los obtenidos con el fielsystem Lustre. GlusterFS tambiķn demuestra ser un filesystem altamente escalable a tenor de los valoresĀ de throughput agregado obtenido. Si bien las cifras se quedan un poco por debajo de las obtenidas con Lustre, no dejan de ser muy buenas.
|
|
|
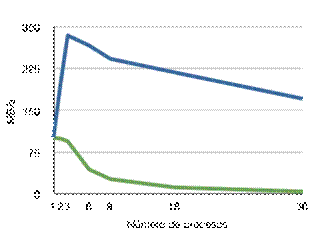
Figura 10.3: Throughput del filesystem GlusterFS en lecturas
De nuevo observamos una escalabilidad lineal con el n·mero de elementos que componen el filesystem. En este caso contamos con 3 AFRs, por lo que es con 3 lecturas concurrentes cuando obtenemos el throughput mßximo, cercano a los 300 MB/s.
Seg·n se incrementa el n·mero de procesos de lectura concurrentes el throughput del filesystem cae ligeramente, debido en parte al mayor estrķs de los dĒscos fĒsicos de cada AFR, y en parte tambiķn a la saturaci¾n en los nodos clientes, que deben procesar mßs instancias de nuestro benchmark, que requiere de cierta capacidad de proceso.
Ademßs como hemos comentado previamente, con AFR los datos se envĒan dos veces por la red, una copia para cada nodo de la pareja. Este hecho limita la cantidad de informaci¾n que puede enviar un nodo cliente a la mitad.
Las pruebas de escritura arrojan los siguientes resultados:
|
Concurrencia |
Tiempo |
Throughput agregado (MB/s) |
MB/s por proceso |
|
1 |
|
33.1 |
33.1 |
|
2 |
|
58.0 |
29.0 |
|
3 |
|
76.7 |
25.5 |
|
6 |
|
70.2 |
11.7 |
|
9 |
|
66.5 |
7.3 |
|
18 |
|
60.1 |
3.3 |
|
36 |
|
56.3 |
1.56 |
En esta ocasi¾n los resultados obtenidos son netamente superiores a los del filesystem Lustre, lastrado por el sistema de replicaci¾n DRBD. Nuevamente el throughput agregado se mantiene bastante estable a lo largo de todas las pruebas.
|
|
|
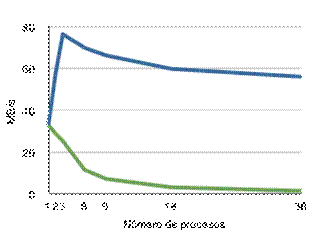
Figura 10.4: Throughput del filesystem GlusterFS en escrituras
10.4.3. Pruebas de usabilidad
Por ·ltimo las pruebas de usabilidad sirvieron para medir el grado de interactividad del usuario con la zona de disco compartido mientras el sistema estaba sometido a distintos niveles de carga de trabajo.
En esta ocasi¾n y al contrario de lo que sucedĒa con el modelo de cluster versi¾n 1.1, todas las pruebas de usabilidad resultaron un ķxito. Incluso a niveles de carga altĒsimos el tiempo de respuesta apreciado por los distintos beta testers fue similar al de un filesystem local.
El ķxito de esta prueba junto con el de la prueba de estabilidad y los buenos resultados cosechados en las pruebas de rendimiento nos lleva a elegir este modelo.
11. Sun Grid Engine
11.1. Instalaci¾n
Obtenemos la ·ltima versi¾n[11] de Sun Grid Engine (en adelante Sun Grid) de la pßgina web de Sun. El software estß empaquetado en dos archivos, una parte com·n y otra con binarios y librerĒas dependiente de la arquitectura, lx24-x86 en nuestro caso. Las descargamos y descomprimimos los archivos en /usr/local/sge:
master-cluster1> tar xfz sge-6.1u2-common.tar.gz -C /usr/local/sge
master-cluster1> tar xfz sge-6.1u2-bin-lx24-x86.tar.gz -C /usr/local/sge
Como paso previo a la instalaci¾n es necesario definir los servicios de red que utiliza SunGrid. Los a±adimos a todas las mßquinas del cluster en el fichero /etc/services:
# Sun grid
ports
sge_qmasterĀĀĀĀ 536/tcp
sge_execdĀĀĀĀĀĀ 537/tcp
Tambiķn es necesario identificar los distintos roles que juegan los nodos de un sistema Sun Grid y asignarlos a nuestros nodos:
Ę Master host: controla el sistema Sun Grid. Este host ejecuta los daemons sge_master y sge_sched. El host que act·a como master debe ser estable, no estar excesivamente cargado con otros procesos y disponer de al menos 1 GB de memoria libre.
Ę Shadow master hosts: act·an como backup de la funcionalidad ofrecida por el master host en caso de que ķste falle. Los hosts que act·an como shadow master deben ejecutar el daemon sge_shadowd, encargado de monitorizar al master host y compartir el status y la configuraci¾n del master host, porĀ lo que la zona sge-root/cell/common debe ser una zona com·n.
Ę Administration hosts: son hosts desde los que se pueden llevar a cabo tareas administrativas como reconfigurar colas, a±adir usuarios, etc. Los hosts master lo son por defecto.
Ę Submit hosts: los trabajos s¾lo pueden ser enviados al sistema desde estos hosts. Por defecto el nodo master es submit host. En nuestro caso, los dos nodos master-cluster.
Ę Execution host: ejecutan los trabajos que los usuarios envĒan al sistema Sun Grid. Un nodo de ejecuci¾n debe estar configurado previamente como nodo administrativo.
En nuestro cluster contamos con dos tipos de nodos diferenciados: los nodos master y los nodos de c¾mputo. Los nodos master, desde el punto de vista del sistema Sun Grid serßn master hosts, administrative hosts y submit hosts. Los nodos de c¾mputo serßn execution hosts y administrative hosts.
Cabe destacar que pese a tener dos hosts que potencialmente pueden actuar como master hosts, no configuramos uno de ellos como shadow_master. En lugar de esto configuramos SunGrid como un servicio mßs de alta disponibilidad monitorizado por heartbeat (ver apartado [12]). De esta manera, cuando el nodo master que act·a como master host cae, heartbeat lo detecta y activa el servicio en el failnode.
11.1.1. Instalaci¾n del Master host
La instalaci¾n se hace de forma interactiva, ejecutando el script install_qmaster de /usr/local/sge.
Checking $SGE_ROOT directory
The Grid Engine root directory is not set!
Please enter a correct path for SGE_ROOT.
If this directory is not correct (e.g. it may contain
an automounter
prefix) enter the correct path to this directory or
hit <RETURN>
to use default [/usr/local/sge] >>
Grid Engine TCP/IP service >sge_qmaster<
Using the service
sge_qmaster
for communication with Grid Engine.
Hit <RETURN> to continue >>
A continuaci¾n configuramos
el nombre de nuestro cluster o cell, ·til en caso de contra con varias
instancias de cluster.
Grid Engine cells
Grid Engine supports multiple cells.
If you are not planning to run multiple Grid Engine
clusters or if you don't
know yet what is a Grid Engine cell it is safe to keep
the default cell name
default
If you want to install multiple cells you can enter a
cell name now.
The environment variable
ĀĀ
$SGE_CELL=<your_cell_name>
will be set for all further Grid Engine commands.
Enter cell name [default] >>
En la siguiente pantalla configuramos la localizaci¾n del
directorio spool.
Grid Engine qmaster spool directory
The qmaster spool directory is the place where the
qmaster daemon stores
the configuration and the state of the queuing system.
Your account on this host must have read/write access
to the qmaster spool directory.
If you will install shadow master hosts or if you want
to be able to start
the qmaster daemon on other hosts (see the
corresponding section in the
Grid Engine Installation and Administration Manual for
details) the account
on the shadow master hosts also needs read/write
access to this directory.
The following directory
[/tmp/sge/default/spool/qmaster]
will be used as qmaster spool directory by default!
Do you want to select another qmaster spool directory
(y/n) [n] >>n
Sun Grid permite la
ejecuci¾n de trabajos en mßquinas Windows. En nuestro caso no lo nenesitamos.
Windows Execution Host Support
Are you going to install Windows Execution Hosts?
(y/n) [n] >>n
Select default Grid Engine hostname resolving method
Are all hosts of your cluster in one DNS domain? If
this is
the case the hostnames
>hostA< and >hostA.foo.com<
would be treated as equal, because the DNS domain name
>foo.com<
is ignored when comparing hostnames.
Are all hosts of your cluster in a single DNS domain
(y/n) [y] >>y
Making directories
Hit <RETURN> to continue >>
La siguiente pantalla
permite configurar el modelo de base de datos utilizado para guardar la
informaci¾n de spool.
Setup spooling
Your SGE binaries are compiled to link the spooling libraries
during runtime (dynamically). So you can choose
between Berkeley DB
spooling and Classic spooling method.
Please choose a spooling method (berkeleydb|classic)
[berkeleydb] >>berkeleydb
The Berkeley DB spooling method provides two
configurations!
Local spooling:
The Berkeley DB spools into a local directory on this
host (qmaster host)
This setup is faster, but you can't setup a shadow
master host
If you want to setup a shadow master host, you need to
use
In this case you have to choose a host with a
configured RPC service.
The qmaster host connects via RPC to the Berkeley DB.
This setup is more
failsafe, but results in a clear potential security
hole. RPC communication
(as used by Berkeley DB) can be easily compromised.
Please only use this
alternative if your site is secure or if you are not
concerned about
security. Check the installation guide for further
advice on how to achieve
failsafety without compromising security.
Do you want to use a Berkeley DB Spooling Server?
(y/n) [n] >>n
Berkeley Database spooling parameters
Please enter the Database Directory now, even if you
want to spool locally,
it is necessary to enter this Database Directory.
Default: [/usr/local/sge/default/spool/spooldb]
>>
/usr/local/sge/default/spool/spooldb
Cada trabajo ejecutado
desde Sun Grid es un procso de sistema mßs. Como tal tendrßn un pid asociado.
En la siguiente pantalla se configura el rango de pids reservados para los
procesos de Sun Grid.
Grid Engine group id range
When jobs are started under the control of Grid Engine
an additional group id
is set on platforms which do not support jobs. This is
done to provide maximum
control for Grid Engine jobs.
This additional UNIX group id range must be unused
group id's in your system.
Each job will be assigned a unique id during the time
it is running.
Therefore you need to provide a range of id's which
will be assigned
dynamically for jobs.
The range must be big enough to provide enough numbers
for the maximum numberof Grid Engine jobs running at a single moment on a
single host. E.g. a rangelike >20000-20100< means, that Grid Engine will
use the group ids from20000-20100 and provides a range for 100 Grid Engine jobs
at the same timeon a single host.
You can change at any time the group id range in your
cluster configuration.
Please enter a range >>20000-25000
Seguidamente indicamos la
direcci¾n de correo del administrador del cluster, tras lo cual se crea una
primera configuraci¾n del sistema.
Grid Engine cluster configuration
Please give the basic configuration parameters of your
Grid Engine
installation:
<execd_spool_dir>
The pathname of the spool directory of the execution
hosts. User >ivanc<
must have the right to create this directory and to
write into it.
Default: [/usr/local/sge/default/spool] >>/usr/local/sge/default/spool
Grid Engine cluster configuration (continued)
<administrator_mail>
The email address of the administrator to whom problem
reports are sent.
It's is recommended to configure this parameter. You
may use >none<
if you do not wish to receive administrator mail.
Please enter an email address in the form
>user@foo.com<.
Default: [none] >>cluster@lsi.upc.edu
The following parameters for the cluster configuration
were configured:
execd_spool_dirĀĀĀĀĀĀĀ
/usr/local/sge/default/spool
administrator_mailĀĀĀĀ
cluster@lsi.upc.edu
Do you want to change the configuration parameters
(y/n) [n] >>n
Creating local configuration
Creating >act_qmaster< file
Adding default complex attributes
Reading in complex attributes.
Adding default parallel environments (PE)
Reading in parallel environments:
ĀĀĀĀĀĀĀ PE
"make".
PE "make.sge_pqs_api".
Adding SGE default usersets
Reading in usersets:
Userset "defaultdepartment".
Userset "deadlineusers".
Adding >sge_aliases< path aliases file
Adding >qtask< qtcsh sample default request file
Adding >sge_request< default submit options file
Creating >sgemaster< script
Creating >sgeexecd< script
Creating settings files for >.profile/.cshrc<
Hit <RETURN> to continue >>
Una vez configurado, el
sistema se inicia el servicio qmaster por primera vez, tras lo cual
introducimos la lista de los hosts de ejecuci¾n.
Grid Engine
qmaster and scheduler startup
Starting
qmaster and scheduler daemon. Please wait ...
starting
sge_qmaster
starting
sge_schedd
starting up GE
6.1u2 (lx24-x86)
Hit
<RETURN> to continue >>
Adding Grid
Engine hosts
Please now add
the list of hosts, where you will later install your execution
daemons. These
hosts will be also added as valid submit hosts.
Please enter a
blank separated list of your execution hosts. You may
press<RETURN>
if the line is getting too long. Once you are finished
simply press
<RETURN> without entering a name.
You also may
prepare a file with the hostnames of the machines where you plan
to install Grid
Engine. This may be convenient if you are installing Grid
Engine on many
hosts.
Do you want to
use a file which contains the list of hosts (y/n) [n] >>n
Adding admin and
submit hosts
Please enter a
blank seperated list of hosts.
Stop by
entering <RETURN>. You may repeat this step until you are
entering an
empty list. You will see messages from Grid Engine
when the hosts
are added.
Sun Grid permite tener una
configuraci¾n de alta disponibilidad del master host mediante el uso de un
shadow master host. Nosotros utilizaremos nuestra propia configuraci¾n HA, por
lo que no configuramos ning·n shadow master.
Host(s):
If you want to use a shadow host, it is recommended to
add this host
to the list of administrative hosts.
If you are not sure, it is also possible to add or
remove hosts after the
installation with <qconf -ah hostname> for
adding and <qconf -dh hostname>
for removing this host
Attention: This is not the shadow host
installationprocedure.
You still have to install the shadow host separately
Do you want to add your shadow host(s) now? (y/n) [y]
>>n
SGE_ROOT directory: /usr/local/sge
Cell name: default
Grid Engine qmaster spool directory:
/usr/local/sge/default/spool/qmaster
Windows Execution Host Support: no
Setup spooling: berkeleydb
Use
Berkeley Database spooling directory:
/usr/local/sge/default/spool/spooldb
Grid Engine group id range: 20000-25000
Grid Engine spool directory on execution hosts:
/usr/local/sge/default/spool
Administration email address: cluster@lsi.upc.edu
Tras
estos pasos se inician los daemons qmaster y schedd.
Grid Engine qmaster and scheduler startup
Starting qmaster and scheduler daemon. Please wait ...
starting sge_qmaster
starting sge_schedd
starting up GE 6.1u2 (lx24-x86)
Hit <RETURN> to continue >>
A continuaci¾n podemos
indicar al sistema quķ hosts seran nodos de ejecuci¾n.
Adding Grid Engine hosts
Please now add the list of hosts, where you will later
install your execution
daemons. These hosts will be also added as valid
submit hosts.
Please enter a blank separated list of your execution
hosts. You may
press<RETURN> if the line is getting too long.
Once you are finished
simply press <RETURN> without entering a name.
You also may prepare a file with the hostnames of the
machines where you plan
to install Grid Engine. This may be convenient if you
are installing Grid
Engine on many hosts.
Do you want to use a file which contains the list of
hosts (y/n) [n] >>n
En la siguiente pantalla se
configuran los hosts desde los que se enviarßn los trabajos y aquellos con
permisos administrativos.
Adding admin and submit hosts
Please enter a blank seperated list of hosts.
Stop by entering <RETURN>. You may repeat this
step until you are
entering an empty list. You will see messages from
Grid Engine
when the hosts are added.
Host(s):
If you want to use a shadow host, it is recommended to
add this host
to the list of administrative hosts.
If you are not sure, it is also possible to add or
remove hosts after the
installation with <qconf -ah hostname> for
adding and <qconf -dh hostname>
for removing this host
Attention: This is not the shadow host
installationprocedure.
You still have to install the shadow host separately
Do you want to add your shadow host(s) now? (y/n) [y]
>>n
Creating the default <all.q> queue and
<allhosts> hostgroup
root@master-cluster1 "@allhosts" to host
group list
root@master-cluster2 "all.q" to cluster
queue list
Hit <RETURN> to continue >>
En la siguiente pantalla
seleccionamos el nivel logs generado por el shceduler. Lo
dejamos en
Scheduler Tuning
The details on the different options are described in
the manual.
Configurations
1)
ĀĀĀĀĀĀĀĀĀ Fixed
interval scheduling, report scheduling information,
actual + assumed load
2) High
ĀĀĀĀĀĀĀĀĀ Fixed
interval scheduling, report limited scheduling information,
actual load
3) Max
ĀĀĀĀĀĀĀĀĀ
Immediate Scheduling, report no scheduling information,
actual load
Enter the number of your prefered configuration and
hit <RETURN>!
Default configuration is [1] >>1
We're configuring the scheduler with >
Do you agree? (y/n) [y] >>y
El master host ya estßĀ configurado. La sieguiente pantalla muestra
informaci¾n sobre la definici¾n de variables de entorno necesarias para que Sun
Grid funcione correctamente.
Using Grid Engine
You should now enter the command:
source /usr/local/sge/default/common/settings.csh
if you are a csh/tcsh user or
ĀĀ #
/usr/local/sge/default/common/settings.sh
if you are a sh/ksh user.
This will set or expand the following environment
variables:
ĀĀ -
$SGE_ROOTĀĀĀĀĀĀĀĀ (always necessary)
ĀĀ -
$SGE_CELLĀĀĀĀĀĀĀĀ (if you are using a
cell other than >default<)
ĀĀ -
$SGE_QMASTER_PORT (if you haven't added the service >sge_qmaster<)
ĀĀ - $SGE_EXECD_PORTĀĀ (if you haven't added the service
>sge_execd<)
ĀĀ -
$PATH/$pathĀĀĀĀĀĀ (to find the Grid
Engine binaries)
ĀĀ -
$MANPATHĀĀĀĀĀĀĀĀĀ (to access the manual
pages)
Hit <RETURN> to see where Grid Engine logs
messages >>
La siguiente pantalla informa de la localizaci¾n deĀ scripts de inicio.
Grid Engine messages
Grid Engine messages can be found at:
ĀĀ
/tmp/qmaster_messages (during qmaster startup)
ĀĀ
/tmp/execd_messagesĀĀ (during
execution daemon startup)
After startup the daemons log their messages in their
spool directories.
ĀĀ Qmaster:ĀĀĀĀ
/usr/local/sge/default/spool/qmaster/messages
ĀĀ Exec daemon:
<execd_spool_dir>/<hostname>/messages
Grid Engine startup scripts
Grid Engine startup scripts can be found at:
ĀĀ
/usr/local/sge/default/common/sgemaster (qmaster and scheduler)
ĀĀ
/usr/local/sge/default/common/sgeexecd (execd)
Do you want to see previous screen about using Grid
Engine again (y/n) [n] >>n
Finalmente se informa de la correcta instalaci¾n del
sistema Sun Grid.
Your Grid Engine qmaster installation is now completed
Please now login to all hosts where you want to run an
execution daemon
and start the execution host installation procedure.
If you want to run an execution daemon on this host,
please do not forget
to make the execution host installation in this host
as well.
All execution hosts must be administrative hosts
during the installation.
All hosts which you added to the list of
administrative hosts during this
installation procedure can now be installed.
You may verify your administrative hosts with the
command
ĀĀ # qconf -sh
and you may add new administrative hosts with the
command
ĀĀ # qconf -ah
<hostname>
Please hit
<RETURN>>>
11.1.2. Instalaci¾n de un Execution host
A continuaci¾n ejecutamos el script de instalaci¾n install_execd. Como requisito previo, es necesario que haya un master host con los servicios qmaster y qschedd corriendo.
Checking $SGE_ROOT directory
The Grid Engine root directory is:
ĀĀ $SGE_ROOT =
/usr/local/sge
If this directory is not correct (e.g. it may contain
an automounter
prefix) enter the correct path to this directory or
hit <RETURN>
to use default [/tmp/sge] >>
En primer lugar indicarmos
en quķ cell o cluster podrß ejecutar trabajos el execution host que estamos
configurando. En nuestro caso en el cell por defecto default.
Grid Engine cells
Please enter cell name which you used for the qmaster
installation or press <RETURN> to use [default]
>>
En la siguiente pantalla
configuramos la localizaci¾n del directorio de spool del execution host.
Local execd spool directory configuration
During the qmaster installation you've already entered
a global
execd spool directory. This is used, if no local spool
directory is configured.
Now you can configure a local spool directory for this
host.
ATTENTION: The local spool directory doesn't have to
be located on a local
drive. It is specific to the <local> host and
can be located on network drives,
too. But for performance reasons, spooling to a local
drive is recommended.
FOR WINDOWS USER: On Windows systems the local spool
directory MUST be set
to a local harddisk directory.
Installing an execd without local spool directory
makes the host unuseable.
Local spooling on local harddisk is mandatory for
Windows systems.
Do you want to configure a local spool directory
for this host (y/n) [n] >>y
Please enter the local spool directory now! >>/usr/local/sge/default/spool/node1
Por defecto todo sistema
Sun Grid dispone de una cola llamada all.q, que incluye todos los nodos de
ejecuci¾n.
Adding a queue for this host
We can now add a queue instance for this host:
ĀĀ - it is added
to the >allhosts< hostgroup
ĀĀ - the queue
provides 2 slot(s) for jobs in all queues
referencing the >allhosts< hostgroup
You do not need to add this host now, but before
running jobs on this host
it must be added to at least one queue.
Do you want to add a default queue instance for this
host (y/n) [y] >>y
node1 modified "@allhosts" in host group
list
node1 "all.q" in cluster queue list
Los servicios Sun Grid ya
estßn instalados correctamente en este host. La siguiente pantalla muestra
variables de entorno necesarias para el correcto funcionamiento de Sun Grid.
Using Grid Engine
You should now enter the command:
source /tmp/sge/default/common/settings.csh
if you are a csh/tcsh user or
# . /tmp/sge/default/common/settings.sh
if you are a sh/ksh user.
This will set or expand the following environment
variables:
ĀĀ -
$SGE_ROOTĀĀĀĀĀĀĀĀ (always necessary)
ĀĀ -
$SGE_CELLĀĀĀĀĀĀĀĀ (if you are using a
cell other than >default<)
ĀĀ -
$SGE_QMASTER_PORT (if you haven't added the service >sge_qmaster<)
ĀĀ - $SGE_EXECD_PORTĀĀ (if you haven't added the service
>sge_execd<)
ĀĀ -
$PATH/$pathĀĀĀĀĀĀ (to find the Grid
Engine binaries)
ĀĀ -
$MANPATHĀĀĀĀĀĀĀĀĀ (to access the manual
pages)
Hit <RETURN> to see where Grid Engine logs
messages >>
Por ultimo se indica la
localizaci¾n de los logs y los scripts necesarios para iniciar Sun Grid en los
execution hosts.
Grid Engine messages
Grid Engine messages can be found at:
ĀĀ
/tmp/qmaster_messages (during qmaster startup)
ĀĀ
/tmp/execd_messagesĀĀ (during
execution daemon startup)
After startup the daemons log their messages in their
spool directories.
ĀĀ Qmaster:ĀĀĀĀ /tmp/sge/default/spool/qmaster/messages
ĀĀ Exec daemon:
<execd_spool_dir>/<hostname>/messages
Grid Engine startup scripts
Grid Engine startup scripts can be found at:
ĀĀ
/tmp/sge/default/common/sgemaster (qmaster and scheduler)
ĀĀ
/tmp/sge/default/common/sgeexecd (execd)
Do you want to see previous screen about using Grid
Engine again (y/n) [n] >>n
Your execution daemon installation is now completed.
11.2. Configuraci¾n
Hemos instalado un master host y un execution host. Durante la instalaci¾n del master host se nos ha preguntado por diversos paths donde almacenar informaci¾n de configuraci¾n del cluster, scheduling de procesos, etc.
En los siguientes pasos aprovecharemos los conocimientos adquiridos en filesystems paralelos y HA para integrar este servicio en nuestro sistema de heartbeat y dotarlo deĀ alta disponibilidad.
Asumimos que partimos de la arquitectura versi¾n 2.0, con GlusterFS instalado.
11.2.1. Zona Spool de mater hosts
En el apartado de configuraci¾n del master host hemos indicado la ruta donde residirß el spool del nodo master (/usr/local/sge/default/spool/qmaster). Este directorio contiene la informaci¾n de scheduling de procesos que necesita el daemon sge_qmaster para funcionar. Si queremos tener un master host alternativo que tome el control del grid en caso de fallo del master host "primario", ambas mßquinas deben tener acceso a la zona referida.
Nuevamente, lo ideal serĒa disponer de un SAN conectado a los dos nodos master, pero no disponemos de estos recursos. En cambio, hemos visto una soluci¾n que ya utilizamos como sistema de replicaci¾n de bloques en el sistema de ficheros Lustre. DRBD permite crear un dispositivo de bloques virtual formado por los discos locales de dos mßquinas conectadas por red.
En la figura [11.1] se muestra un esquema con las zonas que albergan los nodos master-cluster, incluyendo la zona common de Sun Grid.
En un esquema DRBD los nodos que contienen los discos juegan los roles de primary y secondary. El nodo primary tiene pleno acceso al disco, mientras que el secondary se limita a recibir la replicaci¾n de datos desde primary. En el caso que nos toca, el nodo primary serß el nodo que estķ configurado como master host Sun Grid en ese momento, mientras que el otro nodo master serß el nodo secondary. En caso de fallo del nodo primary, el nodo configurado como secondary se darß cuenta y se configurarß como primary.
Para configurar esta zona DRBD, en primer lugar debemos crear dos particiones idķnticas en ambos nodos master. Como contamos con dos discos por mßquina, hacemos un RAID1:
master-cluster1>
mdadm --create /dev/md3 --level=1
--raid-devices=2 /dev/sda5 /dev/sdb5
La configuraci¾n DRBD serß la misma en ambas mßquinas. El fichero drbd.conf se encuentra en el apķndice [19.1.9].
En primer lugar es necesario incializar el dispositivo DRBD. Para ello se deben seguir los pasos detallados en el apartado [9.3.2]. N¾tese que la sincronizaci¾n se realiza por una conexi¾n dedicada entre ambos nodos master.
Ya disponemos de la zona DRBD funcional:
version: 8.2.6
(api:88/proto:86-88)
GIT-hash:
3e69822d3bb4920a8c1bfdf7d647169eba7d2eb4 build by root@master-cluster1,
Ā1: cs:Connected st:Primary/Secondary
ds:UpToDate/UpToDate C r---
ns:9710768 nr:0 dw:9465908 dr:819917 al:59 bm:39 lo:0 pe:0 ua:0 ap:0 oos:0
Paramos el daemon sge_qmaster y movemos el contenido del directorio spool a la zona DRBD:
master-cluster1>
/etc/init.d/sge_qmaster stop
master-cluster1>
mount /dev/drbd1 /mnt/sge/default/spool
master-cluster1>
cd /usr/local/sge/default/spool
master-cluster1>
tar cf - * | (cd
/mnt/sge/default/spool;tar xf - )
master-cluster1>
cd ..
master-cluster1>
rm -rf spool
master-cluster1>
ln -s /mnt/sge/default/spool spool
master-cluster1>
/etc/init.d/sge_qmaster start
11.2.2. Zona common
La zona common contiene informaci¾n acerca de la configuraci¾n del cluster, accounting, etc. De cara a nuestro objetivo de alta disponibilidad, nos resulta interesante el fichero act_qmaster, que contiene el hostname de la mßquina que act·a como master host en un momento dado. Todos los nodos del cluster se basan en la informaci¾n de este fichero para contactar con el master host.
En nuestra configuraci¾n, si el nodo que act·a como master host falla, hay otro nodo preparado para tomar el control. Para ello es necesario que previa ejecuci¾n del daemon sge_qmaster modifique el fichero act_qmaster escribiendo su hostname. S¾lo tras hacer esto le serß posible lanzar el daemon sge_qmaster.
Hemos comentado que todos los nodos del cluster saben quiķn es el master host gracias al fichero act_qmaster. Si hacemos cambios en este fichero, estos cambios deben ser visibles para los nodos del cluster de forma inmediata. Para ello alojaremos el directorio common en una nueva zona compartida. Ademßs de ser visible por todos los nodos del cluster, debe estar accesible a pesar de la caĒda de alguno de los nodos master. La soluci¾n adoptada consiste en crear una zona GlusterFS con un AFR formado por sendas particiones en los nodos de entrada al sistema (master-cluster1 y master-cluster2). De esta manera en caso de caer una de las dos mßquinas master, la otra seguirß teniendo acceso a la zona y ķsta en ning·n caso dejarß de ser visible por el resto de nodos.
En la figura [11.1] se muestran las distintas zonas que albergan los nodos master-cluster, entre ellas la zona common.
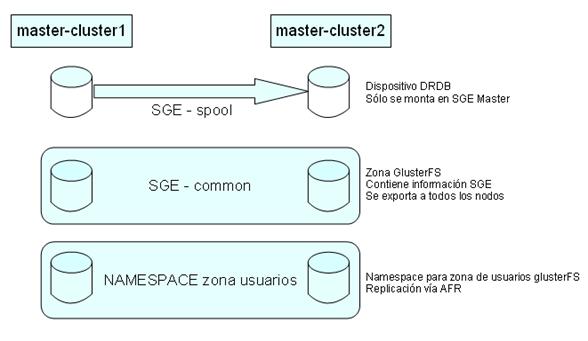
Ilustraci¾n
11.1: Esquema de las zonas albergadas en los nodos master-cluster
Nuevamente, habilitamos una partici¾n RAID en cada una de las mßquinas master:
master-cluster1>
mdadm --create /dev/md4 --level=1
--raid-devices=2 /dev/sda6 /dev/sdb6
master-cluster1>
mke2fs -j /dev/md4
master-cluster1>
mount /dev/md4 /mnt/glusterfs/sge-common
Configuramos
un nuevo servidor GlusterFS en ambas mßquinas master. El correspondiente
fichero de configuraci¾n glusterfs-server_sge-common.vol se encuentra en los apķndices [
Lanzamos el daemon GlusterFS:
master-cluster1> /sbin/glusterfsd -f
/etc/glusterfs/glusterfs-server_sge-common.vol
Creamos una
configuraci¾n cliente gluster para esta nueva zona. Esta configuraci¾n,
guardada en /etc/glusterfs/glusterfs-client-sge.vol (ver apķndices [
Montamos esta zona en todas las mßquinas del cluster en un directorio habilitado a tal efecto:
master-cluster1>
/sbin/glusterfs -f
/etc/glusterfs/glusterfs-client-sge.vol /mnt/sge/default/common
De la misma forma que hicimos con la zona spool, movemos el contenido de la zona common y paramos el daemon sge_execd en todas los execution host, en caso de estar corriendo:
node1> /etc/init.d/sge_execd stop
...
Movemos lo datos common a la nueva zona compartida:
master-cluster1>
/etc/init.d/sge_qmaster stop
master-cluster1>
cd /usr/local/sge/default/common
master-cluster1>
tar cf - * | (cd
/mnt/sge/default/common;tar xf -)
master-cluster1>
cd ..
master-cluster1>
rm -rf common
master-cluster1>
/etc/init.d/sge_qmaster start
Volvemos a lanzar el daemon sge_execd en todos los execution hosts:
node1> /etc/init.d/sge_execd start
...
Tras estos pasos el sistema Sun Grid es plenamente operativo con tolerancia a fallos en los nodos master. Queda pendiente la automatizaci¾n del proceso de inicio de servicios en nodo failover, que veremos el capĒtulo [12].
11.2.3. Colas
La antigua estructura con tres clusters separados tiene su correspondencia en el nuevo cluster en forma de colas. Definiremos tres colas: eixam, nozomi y tenada, que estarßn formadas por las mßquinas que conformaban los respectivos clusters mßs las mßquinas nuevas que estaban pendientes de instalaci¾n.
Cuando hablamos de colas en un entorno HTC se da un abuso de lenguaje que puede llevar a equĒvocos. Una cola Sun Grid realmente es una cola de ejecuci¾n, lo que no es mßs que un conjunto de mßquinas que ejecutan los procesos que les envĒa el planificador o scheduler. No se debe confundir con la cola de espera, que es el espacio ōvirtualö, donde los trabajos encolados por los usuarios esperan a ser enviados por el scheduler a alguna cola de ejecuci¾n.
La figura [11.2] muestra el esquema con las tres colas de ejecuci¾n de nuestro cluster y la cola de espera. N¾tese que hay una ·nica cola de espera en la que conviven los trabajos destinados a cualquiera de las tres colas de ejecuci¾n.

Figura 11.2: Esquema de cluster con colas de ejecuci¾n y de espera
Sun Grid permite definir tantas colas (de ejecuci¾n) como sean necesarias, pudiendo personalizar multitud de aspectos. En cambio, en un cluster, existe una ·nica cola de espera.
La idea es que, a pesar de existir un ·nico cluster, los usuarios de cada grupo ejecuten su trabajo en las mßquinas que les pertenecen. Las colas pueden crearse desde consola o mediante el frontend grßfico qmon , como muestra la figura [11.3].
Si bien inicialmente los usuarios de una cola no pueden utilizar los recursos de las otras, se abre la posibilidad a futuras colaboraciones mediante la creaci¾n de colas nice. Estas colas permiten el aprovechamiento de las mßquinas desocupadas por parte de los usuarios de los otros grupos. Este mecanismo ha sido probado con ķxito en el cluster de pruebas, pero permanecerß desactivado hasta que se produzca un acuerdo de colaboraci¾n entre los distintos grupos de investigaci¾n.
Figura11.3: Ventana de creaci¾n de colas desde qmon
Como hemos comentado antes existe una ·nica cola de espera. En esta cola conviven los trabajos de todos los usuarios ordenados en funci¾n de una prioridad que se explica en el apartado [11.2.4]. Como los usuarios de cada grupo trabajan solamente en la cola que tienen asignada, los trabajos de usuarios de distintos grupos no interferirßn entre sĒ a la hora de salir de la cola de espera. Por decirlo de alguna manera, en la cola de espera, los trabajos de un usuario dado s¾lo compiten con trabajos de usuarios de su mismo grupo.
11.2.3. Usuarios
Se procedi¾ a dar de alta a todos los usuarios del cluster como usuarios del sistema Sun Grid con el mismo username. Sun Grid permite la gesti¾n de usuarios, grupos, proyectos, etc.
Igualmente creamos tres grupos que se corresponden con los tres clusters antiguos y con las tres colas y se establecieron los permisos de acceso a cada una de las colas seg·n estos grupos, de tal forma que en la cola eixam s¾lo podrßn trabajar los usuarios del grupo eixam, en nozomi los del grupo nozomi, etc. La figura [11.4] muestra la ventana de administraci¾n de grupos de qmon.
A nivel administrativo los grupos facilitan la gesti¾n de los usuarios. Dado que los permisos de las colas se establecen por grupos, si damos de alta o de baja un usuario, no es necesario realizar ninguna modificaci¾n en el control de acceso de las colas; el cambio queda reflejado en su grupo y las colas son conscientes inmediatamente.
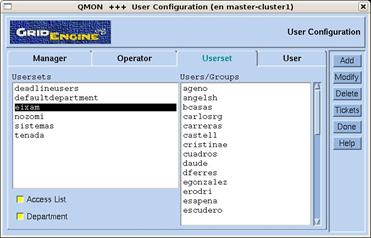
Figura 11.4: Ventana de administraci¾n de grupos en qmon
11.2.4. PolĒticas
Al hablar de la cola de espera, hemos hecho notar que los trabajos que contiene se ordenan atendiendo a un valor numķrico que expresa una prioridad. Junto con los responsables de los tres grupos que trabajan en el cluster, acordamos que, en principio, todos los usuarios contasen con el mismo peso en el sistema, es decir, que los trabajos de cada uno de ellos fuesen igual de prioritario que los del resto de usuarios.
Para llevar a cabo esta polĒtica ōigualitariaö, definimos lo que Sun Grid llama una polĒtica funcional. En dicha polĒtica a cada usuario se le da un porcentaje o share de los recursos, definidos en forma de tikets. A mayor share mayor prioridad.
Como queremos que todos los usuarios tengan el mismo peso, damos a todos los usuarios el mismo share. El resultado de esta polĒtica es que, los trabajos en cola de espera de los usuarios con menor n·mero de trabajos en ejecuci¾n tendrßn mayor prioridad que los trabajos de los usuarios con mßs trabajos ejecutßndose.
Para mantener un ratio ¾ptimo entre procesos de usuario y n·mero de CPUs, limitaremos el valor slots de las instancias de cada cola al n·mero de procesadores (o cores) fĒsico de cada nodo. AsĒ un nodo con 4 cores tendrß 4 slots disponibles, lo que limitarß el n·mero de trabajos en ejecuci¾n de forma simultßnea.
El planificador de Sun Grid repasa las colas a intervalos de tiempo preestablecidos y ordena los trabajos de usuario en funci¾n de sus prioridades. Esta tarea puede llegar a requerir una cantidad de cßlculo nada desde±able en el caso de contar con polĒticas de scheduling complejas y miles de procesos encolados.
Si bien nuestra polĒtica de scheduling es convencional, limitamos la ventana de trabajos que entran dentro de la planificaci¾n de la cola a 10.000. Igualmente limitamos a 500 el n·mero mßximo de trabajos encolados por un solo usuario con el fin de evitar que un solo usuario acapare toda la cola.
Finalmente limitamos el n·mero mßximo de trabajos en ejecuci¾n simultßneos de usuario a 25. El objetivo es evitar la inanici¾n de los trabajos encolados porque un usuario del mismo grupo haya ocupado la totalidad de su cola.
La figura [11.5] muestra la ventana que da acceso a las polĒticas del cluster. Permite variar aspectos como el numero mßximo de trabajos funcionales, de tickets, etc.
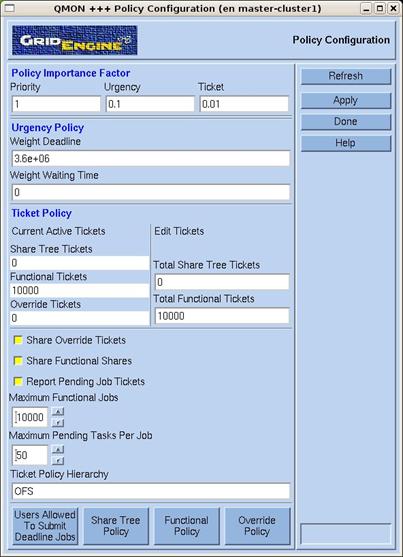
Figura 11.5: Ventana de control de polĒticas del cluster desde qmon
La figura [11.6]
muestra la ventana que permite variar la configuraci¾n funcional. Nuestra
configuraci¾n asigna el mismo n·mero de share
(100) a todos los usuarios,Ā para que de
esta forma los trabajos de todos los usuarios tengan, a igual n·mero de jobs en
el sistema, la misma prioridad.
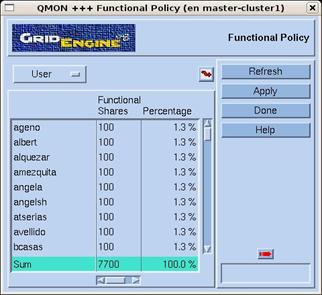
Figura 11.6: Ventana de gesti¾n de la polĒtica funcional desde qmon
12. Heartbeat
Utilizaremos Heartbeat para proporcionar alta disponibilidad a los principales servicios del cluster, que son Sun Grid y el sistema de ficheros paralelo.
12.1. Instalaci¾n
Heartbeat estß disponible dentro del repositorio de software de Debian, por lo que la instalaci¾n es la misma que la de cualquier otro programa:
master-cluster1>
apt-get install heartbeat
Los ficheros de configuraci¾n, asĒ como los scripts de gesti¾n de servicios que quedan en los directorios /etc/ha.d y en /etc/ha.d/resources.d respectivamente.
La instalaci¾n configura el arranque de heartbeat automßticamente al inicio del sistema.
12.2. Configuraci¾n
12.2.1. Cluster con GlusterFS (versi¾n 2.0)
Como vimos en el capĒtulo [10] cuando hablamos de la instalaci¾n y configuraci¾n de GlusterFS, el propio filesystem incorpora mecanismos de protecci¾n ante el fallo de un servidor de disco. El sistema de replicaci¾n de datos AFR se encarga de escribir los datos en varios servidores al mismo tiempo, por lo que no es necesario, al contrario de los que sucedĒa en los modelo con Lustre y DRBD (cluster versiones 1.0 y 1.1), el uso de un sistema de replicaci¾n de datos. AsĒ pues, el ·nico servicio que debemos configurar en HA es Sun Grid.
Tal y como expusimos en el apartado [11.2] al hablar de la configuraci¾n de Sun Grid, hay dos zonas con datos vitales para su correcto funcionamiento. Por una parte el directorio common, encargado de mantener la informaci¾n de la configuraci¾n del sistema, y por otro spool, con informaci¾n sobre el scheduling de procesos. El directorio common estß hospedado en la zona GlusterFS, por lo que queda salvaguardado ante posibles fallos. En cambio el directorio spool se encuentra en una zona DRBD compartida entre los dos nodos master.
El funcionamiento de DRBD se explica detalladamente en el apartado [9.1].
En caso de que se produzca un fallo hardware en la mßquina master, nuestro sistema de alta disponibilidad debe ser capaz de darse cuenta y realizar los pasos que acabamos de describir. En este escenario el nodo que ha fallado habrĒa quedado totalmente invalidado para continuar ofreciendo los servicios de Sun Grid master.
El siguiente paso es garantizar que, una vez el failnode tiene control sobre la zona common, se convierta en Sun Grid master. En primer lugar hay que cambiar la identidad de la mßquina master Sun Grid en la configuraci¾n del sistema de clustering para que todos los nodos sepan que tienen que tratar con una nueva mßquina. Despuķs de esto bastarß con iniciar los servicios de Sun Grid master.
Heartbeat se configura desde dos ficheros: ha.cf y haresources9. En ha.cf se define c¾mo y cada cußnto tiempo monitorizaremos el peer node, mientras que en haresources definiremos los procedimientos a seguir en caso de fallo del peer node.
En estos ficheros de configuraci¾n indicamos que el chequeo o heartbeat se realiza vĒa red (ethernet) unicast a la direcci¾n del interfaz eth0 del peer node. Asumimos que si la red de uno de los dos nodos no responde en 120 segundos, se puede considerar que el nodo ha fallado y debemos tomar las medidas oportunas.
Los procedimientos a seguir en caso de fallo se definen en haresources:
master-cluster1
Filesystem.drbd::/dev/drbd1::/mnt/sge/default/spool::ext3 sungrid MailTo::cluster@lsi.upc.edu
Este fichero es idķntico en ambos nodos. El primer campo indica el nodo que act·a como master normalmente, mientras que los siguientes dos nodos definen acciones concretas:
Filesystem::/dev/drbd1::/mnt/sge/default/spool::ext3
Ejecuta el script Filesystem, encargado de montar el dispositivo /dev/drbd1, que contiene la zona spool de Sun Grid en /mnt/sge/default/spool.
El cambio de rol secondary por primary necesario previo al montaje lo realiza el propio sistema DRBD.
Sungrid
Este script cambia la configuraci¾n del sistema SunGrid indicando el hostname de la nueva mßquina master. El script completo se encuentra en el apķndice [19.1.8].
Finalmente indicamos la direcci¾n de correo a la que llegarßn los avisos en caso de fallo y recuperaci¾n.
12.3. Split-Brain
Al hablar de sistemas de alta disponibilidad debemos tener en cuenta el fen¾meno llamado split-brain, que se produce cuando la comunicaci¾n entre los dos nodos se interrumpe y ambos intentan ser propietarios del mismo recurso.
De los dos recursos que tratamos, s¾lo la zona DRBD es susceptible de sufrir problemas por split-brain. Imaginemos que master-cluster1 es el nodo master y se queda sin conexi¾n de red (eth0) aunque sigue funcionando. Master-cluster2 lo detectarĒa por heartbeat, asumirĒa que ha fallado e intentarĒa montar el dispositivo DRBD, pero no podrĒa ya que no es un nodo primary. Master-cluster1 seguirĒa siendo primary porque la replicaci¾n DRBD se realiza vĒa un interfaz dedicado (eth1) que seguirĒa funcionando. AsĒ pues, en este escenario no nos verĒamos afectados por split-brain.
Supongamos ahora que falla la conexi¾n dedicada (eth1), pero no la conexi¾n de red (eth0). En este caso serĒa el sistema DRBD el que detectarĒa un fallo en los nodos e intentarĒa cambiar los roles. En este caso, muy poco probable, sĒ que podrĒa producirse split-brain, ya que podrĒamos tener ambos nodos master configurados como primary, si bien no llegarĒa a producirse corrupci¾n de datos porque el nodo configurado inicialmente como secondary nunca llegarĒa a montar el dispositivo DRBD (recordemos que como eth0 no ha fallado heartbeat no detecta fallo alguno).
Otro caso en el que se producirĒa split-brain serĒa aquel en el que ambas conexiones de red se interrumpieran pero los nodos siguiesen funcionando. En este caso en el nodo secondary el sistema DRBD dectarĒa el fallo en eth1 y se configurarĒa como primary. Algo mßs tarde (recordemos, 120 segundos) heartbeat montarĒa el dispositivo DRBD e intentarĒa configurarse como Sun Grid master, pero no lo conseguirĒa porque no hay conexi¾n de red.
AsĒ pues ambos nodos master tienen el control sobre la zona DRBD, pero s¾lo uno de ellos, en el que sigue ejecutßndose los daemons de Sun Grid master, es susceptible de escribir en la zona, evitando asĒ corrupci¾n de datos.
Al volver la conexi¾n de red DRBD detectarĒa la situaci¾n an¾mala con los dos nodos primary. Llegados a este punto DRBD cuenta con distintas estrategias de recuperaci¾n de split-brain, pero dado lo poco probable y delicado del tema preferimos ser avisados vĒa email y actuar manualmente.
13. Tivoli
Utilizaremos Tivoli como software de gesti¾n deĀ las imßgenes de sistema de los nodos del cluster. Este software nos permitirß instalar por red una imagen limpia del sistema cada vez que una mßquina arranca. Por otro lado el realizar nuevas versiones de la imagen o instalar nuevo software es trivial con este mecanismo.
Ademßs de la instalaci¾n del sistema en sĒ, Tivoli permite realizar operaciones previas sobre la mßquina utilizando un lenguaje de programaci¾n propio denominada Rembo-C. Gracias a ello, podremos a±adir nuevas mßquinas al cluster inicializando los discos y el sistema de forma desatendida.
13.1. Instalaci¾n
Uno de los
motivos de la elecci¾n de Tivoli como software de gesti¾n de imßgenes es,
ademßs de su potencia y versatilidad, la disponibilidad de licencia. El
software puede encontrarse en la intranet de distribuci¾n de software de
Desde la adquisici¾n de Rembo por parte de IBM en 2006, parte de las funcionalidades que nos interesan (scripts en Rembo-C) han dejado de estar disponibles. Para poder trabajar con Tivoli en modo Rembo es necesario instalar un parche. Descargamos Tivoli de la distribuci¾n de software y el parche de la web de IBM.
Descomprimimos en /usr/local los paquetes con Tivoli y el parche:
master-cluster1>
cd /usr/local
master-cluster1>
tar xfzĀ
TPMfOSd-Full-5.1.1.0-build-051.39-linux.tar.gz
master-cluster1>
tar xfzĀ
TPMfOSd-TKIT-Fix-5.1.1.0-build-053.11-
linux.tar.gz
master-cluster1>
cd /usr/local
master-cluster1>
tar xfz
TPMfOSd-Full-5.1.1.0-build-051.39-linux.tar.gz
master-cluster1>
apt-get install mysql-server
Ejecutamos el programa de instalaci¾n:
master-cluster1>
cd /usr/local/tpmfos
master-cluster1>
./setup
ĀĀĀĀĀ 1. Enter the
installation directory [/usr/local/tpmfos]:
ĀĀĀĀĀĀĀĀĀĀĀĀĀ This
software requires a large amount of disk space to store client images.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Please
enter the directory where to store these data.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Data
directory [/usr/local/tpmfos/files]:
ĀĀĀĀĀĀ 2. This
software can be managed from a web-based console.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ You
can choose to use a secure link (HTTPS) to the server console.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ You
can also change the default ports. You must also choose the administrator name
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Do
you want to use SSL to access the Web interface? [y/n (default y)]:
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Enter
the HTTP console port [8080]:
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Enter
the HTTPS console port [443]:
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Enter
the administrator name [admin]:
Configuramos
el entorno web de gesti¾n de Tivoli.
ĀĀĀĀĀĀ 3. ln: creando el enlace
simb¾lico ½mysql.jar╗ a ½mysql-connector-java-*/mysql-connector-java-*-bin.jar╗
ĀĀĀĀĀĀ
El enlace lo hemos creado con
anterioridad y apunta a nuestro conector mysql ubicado en
/usr/java/j2sdk1.4.2_18/jre/lib/ext/mysql-connector-java-
ĀĀĀĀĀĀ 4. This software requires a third party database to store deployment
objects.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Can
you provide a MySQL database? [y/n (default y)]:
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Enter
the IP address of your MySQL server [127.0.0.1]:
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Enter
the port used by your MySQL server on 127.0.0.1 [3306]:
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Enter
the name of an existing (empty) database [AutoDeploy]:
ĀĀĀĀĀĀĀĀĀĀĀĀĀ If the
database AutoDeploy on server 127.0.0.1 does not exist, please create it now!
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Press
return to continue...
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Enter
the user name to access the database [root]:
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Enter
the password to access the database:
Debemos crear una bbdd con el nombre
AutoDeploy, aunque en otra versi¾n se llama tpmfosddb.
ĀĀĀĀĀĀ 5.
The installation program will now create the configuration file and initialize
the server.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Please
wait...
ĀĀĀĀĀĀĀĀĀĀĀĀĀ IBM
Tivoli Provisioning Manager for OS Deployment server v.5.1 (000.32)
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Licensed
Materials - Property of IBM. L-DDAC-6RLW3E
ĀĀĀĀĀĀĀĀĀĀĀĀĀ (C)
Copyright IBM Corporation 1998, 2006.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ All
Rights Reserved. IBM, the IBM logo, and
ĀĀĀĀĀĀĀĀĀĀĀĀĀ of
IBM Corporation in the
ĀĀĀĀĀĀĀĀĀĀĀĀĀ **
Rembo server has successfully stopped
ĀĀĀĀĀĀĀĀĀĀĀĀĀ OS
deployment server initialized successfully.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ File
/opt/tpmfos-5.1/files/global/rad/radb.ini created successfully.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ URL
to access database:
mysql://127.0.0.1:3306/AutoDeploy?useUnicode=true&characterEncoding=UTF-8
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Username
to access the database: root
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Password
to access the database: hidden
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Do
you want to create startup scripts? [y/n (default y)]:
Se
crean los scripts de inicio.
ĀĀĀĀĀ
ĀĀĀĀĀĀ 6. ĀĀĀ File /home/tpmfos/files/global/rad/radb.ini
created successfully.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ URL
to access database:
mysql://127.0.0.1:3306/AutoDeploy?useUnicode=true&characterEncoding=UTF-8
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Username
to access the database: root
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Password
to access the database: hidden
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Do
you want to create startup scripts? [y/n (default y)]:
ĀĀĀĀĀĀĀĀĀĀĀĀĀ ln: creando el
enlace simb¾lico ½/etc/rc2.d/S91rembo╗ a ½/etc/init.d/rembo╗: El fichero existe
ĀĀĀĀĀĀĀĀĀĀĀĀĀ ln: creando el
enlace simb¾lico ½/etc/rc2.d/S92rbagent╗ a ½/etc/init.d/rbagent╗: El fichero
existe
ĀĀĀĀĀĀĀĀĀĀĀĀĀ ln: el destĒ
½/etc/rc2.d/S90dbgw╗ no ķs un directori
ĀĀĀĀĀĀĀĀĀĀĀĀĀ ln: creando el enlace
simb¾lico ½/etc/rc5.d/S91rembo╗ a ½/etc/init.d/rembo╗: El fichero existe
ĀĀĀĀĀĀĀĀĀĀĀĀĀ ln: creando el
enlace simb¾lico ½/etc/rc5.d/S92rbagent╗ a ½/etc/init.d/rbagent╗: El fichero
existe
ĀĀĀĀĀĀĀĀĀĀĀĀĀ ln: creando el
enlace simb¾lico ½/etc/rc5.d/S90dbgw╗ a ½/etc/init.d/dbgw╗: El fichero existe
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Startup scripts (rembo, dbgw, rbagent) have been created in /etc/init.d.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Do
you want to start all the services ? [y/n (default y)]:
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Starting
Rembo JDBC to ODBC gateway: dbgw.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Starting
IBM Tivoli Provisioning Manager for OS Deployment server: remboStarting IBM
Tivoli Provisioning ĀĀĀĀĀĀĀĀĀĀĀĀĀ Manager
for OS Deployment Web interface extension: rbagentIBM Tivoli Provisioning
Manager for OS Deployment ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ Web
interface extension v.5.1 (000.32)
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Licensed
Materials - Property of IBM. L-DDAC-6RLW3E
ĀĀĀĀĀĀĀĀĀĀĀĀĀ (C)
Copyright IBM Corporation 1998, 2006.
ĀĀĀĀĀĀĀĀĀĀĀĀĀ All
Rights Reserved. IBM, the IBM logo, and
ĀĀĀĀĀĀĀĀĀĀĀĀĀ of
IBM Corporation in the
ĀĀĀĀĀĀĀĀĀĀĀĀĀ .
ĀĀĀĀĀĀĀĀĀĀĀĀĀ Goodbye!
Tras responder estas preguntas Tivoli queda instalado con una
configuraci¾n preliminar.
Copiamos el script de inicio en /etc/init.d/ y hacemos que el servicio Tivoli se inicie al arrancar el sistema:
master-cluster1>
cp
/usr/local/tmpfos/scripts/linux/redhat/rembo /etc/init.d/tivoli
master-cluster1> ln -s /etc/init.d/tivoli /etc/rc2.d/S91tivoli
Tivoli instala un servidor web que corre en el puerto 8080. En adelante toda interacci¾n con el sistema de imßgenes se realizarß vĒa web:
http://master-cluster1.lsi.upc.edu:8080
Tivoli utiliza el protocolo PXE (Preboot eXecution Environment) para arrancar e instalar los sistemas de las mßquinas que gestiona. Este sistema funciona conjuntamente con el protocolo de red DHCP. En las mßquinas master contamos con sendos servidores DHCP (ver apartado [16.1]) que se encargan de asignar las direcciones IP a cada una de las mßquinas del cluster.
Para que Tivoli funcione correctamente con nuestros servidores DHCP es necesario indicar lo siguiente en su fichero de configuraci¾n (/etc/dhcp3/dhcpd.conf):
option vendor-class-identifier "PXEClient";
13.2. Configuraci¾n
Agruparemos las mßquinas por "clusters/colas", creandoĀ 3 grupos administrativos, eixam, nozomi y tenada, mßs un grupo con las mßquinas servidoras de disco denominado storage. Cada una de las mßquinas del cluster debe darse de alta en Tivoli en alguno de estos grupos. Posteriormente podremos personalizar el proceso de instalaci¾n de imßgenes por grupos si es necesario.
El alta de una mßquina se hace desde el men· Toolkit«Toolkit Hosts«Register new hosts.
Los datos solicitados son la direcci¾n IP y la direcci¾n MAC de la tarjeta de red. Es necesario dar de alta previamente cada mßquina en el servidor DHCP con los mismos datos.
Una vez dada
de alta, se debe configurar la mßquina para arrancar por red vĒa PXE. Esta
funcionalidad se configura en
Tras estos pasos, la mßquina estß lista para arrancar vĒa PXE. Durante el arranque de Tivoli, en primer lugar el nodo obtiene una direcci¾n IP por DHCP y posteriormente se establece comunicaci¾n entre el nodo y el servidor Tivoli. La figura [13.1] muestra este proceso.
Figura
13.1: Pantalla de nodo arrancando por PXE
Por defecto todas las mßquinas dadas de alta en Tivoli ejecutan el interfaz de administraci¾n, que cuenta con una consola que nos permitirß crear imßgenes del sistema en el servidor. En la figura [13.2] se muestra la pantalla con el interfaz de administraci¾n de Tivoli.
La idea es
configurar una mßquina tipo paraĀ una vez
que sea estable y cuente con todos los servicios necesarios, arrancar vĒa PXE
el interfaz de administrador y crear una imagen de sistema. Posteriormente esta
imagen de sistema se instalarß por red en todas las mßquinas del cluster en el
momento de arrancar. Tras finalizar el proceso de copia del sistema, la mßquina
arrancarß y personalizarß el sistema en funci¾n de su rol dentro del cluster,
como se detalla en el apartado [13.4].
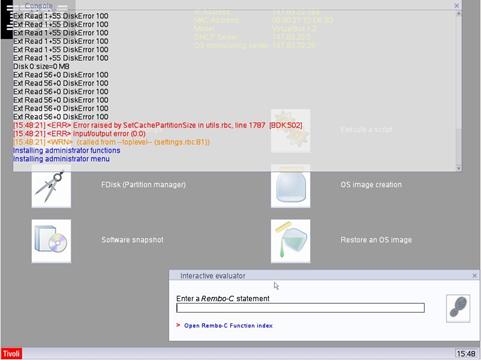
Figura 13.2: Interfaz de administraci¾n de Tivoli
Este mecanismo nos permite actualizar el sistema de los nodos de computaci¾n simplemente reinicißndolos cuando no tengan trabajos asignados. Los nodos servidores de disco tambiķn se actualizan reinicißndolos, teniendo la precauci¾n de no reiniciar al mismo tiempo los dos nodos de un mismo AFR, lo cual provocarĒa la pķrdida de acceso a la parte de datos que sirviesen. Una estrategia vßlida podrĒa ser rebotar en primer lugar los nodos servidores de disco pares (disc2, disc4Ā y disc6) y una vez ķstos hubiesen arrancado con el nuevo sistema reiniciar los impares (disc1, disc3 y disc5).
13.3. Creaci¾n de una imagen
Desde la consola en el interfaz de administraci¾n de Tivoli en la mßquina de referencia copiamos en el servidor una copia de la partici¾n que incluye el sistema operativo y dos ficheros, el kernel y el initial ramdisk, que nos permitirßn arrancar la mßquina una vez finalice el volcado del sistema:
BuildDiskImage(0,1,"net://global/hdimages/node.img");
CopyFile("disk://0:1/boot/vmlinuz-
CopyFile("disk://0:1:/boot/initrd.img-
Tivoli cuenta
con un potente lenguaje de programaci¾n que permite realizar muchas mßs
operaciones ademßs de crear y volcar imßgenes. Utilizaremos Rembo-C para
particionar de forma inteligente las mßquinas antes de volcar el sistema. Estos
scripts se guardan en el servidor y son invocados en lugar del interfaz de
administrador cuando se indica explĒcitamente. Pueden consultarse en los
apķndices [
13.4. Personalizaci¾n de imßgenes
En los capĒtulos anteriores hemos explicado c¾mo instalar y configurar los servicios necesarios para el correcto funcionamiento del cluster. En este apartado veremos los mecanismos necesarios para automatizar el proceso de configuraci¾n de nodos.
El script de arranque de Tivoli detecta el n·mero de discos, si bien utilizamos como mßximo 2 de ellos (en RAID) y comprueba si se trata de discos inicializados. Una mßquina con discos inicializados es una mßquina que ya forma parte del cluster y en la que no hay que tocar el particionamiento pues se podrĒan perder datos.
Tivoli, al detectar una mßquina nueva (ning·n disco inicializado), particiona sus discos de la siguiente manera:
partici¾n 1: EXT2ĀĀĀĀĀĀ 20 GB
partici¾n 2: SWAPĀĀĀĀĀĀĀ 4 GB
particion 3: RAIDĀĀĀĀĀĀ TAMAčO TOTAL -
TAMAčO particion1 - TAMAčO
particion2 - 1MB
Se crean un total de 3 particiones. Al arrancar el sistema operativo, el script de personalizaci¾n de imagen post_boot.sh crearß una cuarta en cada uno de sus discos que los marcarß como "inicializados". En posteriores arranques, la existencia de esta cuarta partici¾n harß que Tivoli se limite a restaurar la imagen de sistema sin mßs.
La casuĒstica que se contempla a la hora de restaurar la imagen en una mßquina es la siguiente:
1. Nodo nuevo (ning·n disco inicializado)
Ā1.1. Con 1 disco
ĀĀĀĀĀ * InicializarDisco(0)
Ā1.2. Con > 1 disco
ĀĀĀ 1.2.1. Discos de mismo tama±o
ĀĀĀĀĀĀĀĀĀĀ * InicializarDisco(0)
ĀĀĀĀĀĀĀĀĀĀ * InicializarDisco(1)
ĀĀĀĀĀĀĀĀĀĀ * RestaurarSistema
ĀĀĀĀĀĀĀĀĀĀ * ArrancarLinux
ĀĀĀ 1.2.2. Discos de distinto tama±o
ĀĀĀĀĀĀĀĀĀĀ * ObtenerDiscoDeMenorTama±o
ĀĀĀĀĀĀĀĀĀĀ // inicializamos los discos con el particionamiento del disco
ĀĀĀĀĀĀĀĀĀĀ // de menor tama±o
ĀĀĀĀĀĀĀĀĀĀ * InicializarDisco(0)
ĀĀĀĀĀĀĀĀĀĀ * InizializarDisco(1)
Ā ĀĀĀĀĀĀĀĀĀ* RestaurarSistema
ĀĀĀĀĀĀĀĀĀĀ * ArrancarLinux
2. Nodo del cluster (alg·n disco inicializado)
Ā2.1. Con 1 disco
ĀĀĀĀ ĀĀĀĀĀ* RestaurarSistema
ĀĀĀĀĀĀĀĀĀĀ * ArrancarLinux
Ā2.2. Con > 1 disco
ĀĀ 2.2.1. Dos discos inicializados
ĀĀĀĀĀĀĀĀĀĀ * RestaurarSistema
ĀĀĀĀĀĀĀĀĀĀ * ArrancarLinux
ĀĀ 2.2.2. Un disco no inicizaliado
ĀĀĀĀ 2.2.2.1. Tama±o(disco no inicializado) < Tama±o(disco inicializado)
ĀĀĀĀĀĀĀĀĀĀĀĀĀ * ERROR, el disco nuevo debe ser mayor o igual que el disco inicializado
ĀĀĀĀ 2.2.2.2. Tama±o(disco no inicializado) >= Tama±o(disco inicializado)
ĀĀĀĀĀĀĀĀĀĀĀĀĀ * InicializarDisco(disco no inicializado)
InicializarDisco(IdDisco) {
Ā * ObtenerTama±odiscoMenor
Ā * ParticionarDisco(IdDisco)
}
DiscoInicializado?(IdDisco) retorna BOOL {
Ā si (NumParticiones(IdDisco)<4)
ĀĀĀĀ retorna FALSO;
Ā sino
ĀĀĀĀ si (TipoPartition(IdDisco,4) == "f0")
ĀĀĀĀĀĀĀĀ retorna TRUE;
ĀĀĀĀ sino
ĀĀĀĀĀĀĀĀ retorna FALSE;
ĀĀĀĀ fsi
Āfsi
}
El script
rembo que controla la instalaci¾n de imßgenes en los nodos bootnode-gluster.shtml
se encuentra en los apķndices [
Una vez el sistema operativo se restaura en un nodo y ķste arranca, se lleva a cabo la personalizaci¾n del sistema en funci¾n de la identidad del nodo y su rol dentro del cluster, que llevarß a cabo el script /etc/init.d/post_boot.sh. Para ello se basarß en la informaci¾n almacenada en fichero /root/files/nodes/nodes de los nodos master, que es una peque±a base de datos con la informaci¾n de todos los nodos dados de alta.
Este formato del fichero de nodos es el siguiente:
# Listado de nodos
#
# Indica, para cada nodo, si forma parte de un OST y, en tal caso, si
se
# trata de un nodo (P)rimario o (S)ecundario y quiķn es su pareja.
#
# Atenci¾n: Dar de alta primero a nodo primario y, posteriormente, una
vez
# exporten el OST, a su secundario
#
#
# HOSTNAMEĀĀ
OST?ĀĀ (P)ri/(S)ecĀĀ PAIRNODEĀĀĀĀĀĀĀ CLUSTERĀĀĀĀ MCAST_CHANNEL
# --------ĀĀ
----ĀĀ -----------ĀĀ --------ĀĀĀĀĀĀĀ -------ĀĀĀĀ -------------
disc1ĀĀĀĀĀ
SIĀĀĀĀĀĀĀĀĀ PĀĀĀĀĀĀĀĀ disc2ĀĀĀĀĀĀĀĀĀ storageĀĀĀĀĀ 239.
disc2ĀĀĀĀĀ
SIĀĀĀĀĀĀĀĀĀ SĀĀĀĀĀĀĀĀ disc1ĀĀĀĀĀĀĀĀĀ storageĀĀĀĀĀ 239.
disc3 ĀĀĀĀĀSIĀĀĀĀĀĀĀĀĀ
PĀĀĀĀĀĀĀĀ disc4ĀĀĀĀĀĀĀĀĀ storageĀĀĀĀĀ 239.
disc4ĀĀĀĀĀ
SIĀĀĀĀĀĀĀĀĀ SĀĀĀĀĀĀĀĀ disc3ĀĀĀĀĀĀĀĀĀ storageĀĀĀĀĀ 239.
disc5ĀĀĀĀĀ
SIĀĀĀĀĀĀĀĀĀ PĀĀĀĀĀĀĀĀ disc6ĀĀĀĀĀĀĀĀĀ storageĀĀĀĀ Ā239.
disc6ĀĀĀĀĀ
SIĀĀĀĀĀĀĀĀĀ SĀĀĀĀĀĀĀĀ disc5ĀĀĀĀĀĀĀĀĀ storageĀĀĀĀĀ 239.
node200ĀĀĀ NOĀĀĀĀĀĀĀĀĀ -ĀĀĀĀĀĀĀĀ -ĀĀĀĀĀĀĀĀĀĀĀĀĀ tenadaĀĀĀĀĀĀ 239.
node102ĀĀĀ NOĀĀĀĀĀĀĀĀĀ -ĀĀĀĀĀĀĀĀ -ĀĀĀĀĀĀĀĀĀĀĀĀĀ eixamĀĀĀĀĀĀĀ 239.
node301ĀĀĀ NOĀĀĀĀĀĀĀĀĀ -ĀĀĀĀĀĀĀĀ -ĀĀĀĀĀĀĀĀĀĀĀĀĀ nozomiĀĀĀĀĀĀ 239.
node303ĀĀĀ NOĀĀĀĀĀĀĀĀĀ -ĀĀĀĀĀĀĀĀ -ĀĀĀĀĀĀĀĀĀĀĀĀĀ nozomiĀĀĀĀĀĀ 239.
node104ĀĀĀ NOĀĀĀĀĀĀĀĀĀ -ĀĀĀĀĀĀĀĀ -ĀĀĀĀĀĀĀĀĀĀĀĀĀ eixamĀĀĀĀĀĀĀ 239.
node105ĀĀĀ NOĀĀĀĀĀĀĀĀĀ -ĀĀĀĀĀĀĀĀ -ĀĀĀĀĀĀĀĀĀĀĀĀĀ eixamĀĀĀĀĀĀĀ 239.
Tras el hostname, el campo OST? indica si el nodo en cuesti¾n es servidor de disco. De ser "SI" el siguiente campo indicarß si es un nodo primario o secundario. El siguiente campo indica quķ nodo es su pairnode, es decir, el nodo con el que mantiene sus datos replicados.
Los dos ·ltimos campos sirven al sistema de monitorizaci¾n Ganglia para incluir el nodo en uno de los grupos y para establecer el canal multicast de comunicaci¾n con el resto de sus compa±eros.
El script post_boot.sh copia informaci¾n actualizada de los nodos master (fichero nodos, configuraci¾n de GlusterFS, usuarios, ganglia, crons, etc) y personaliza el sistema en funci¾n de la informaci¾n almacenada el el fichero nodes. La casuĒstica es la siguiente:
1. Ning·n disco inicializado.
ĀĀĀ 1.1. Dos discos no inicializados
ĀĀĀĀĀĀĀĀĀĀ 1.1.1. Nodo no es servidor de disco
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ // nodo es cliente glusterFS
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ * Montamos zona common de SunGrid
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ * Montamos HOME glusterFS
ĀĀĀĀĀĀĀĀĀĀ 1.1.2. Nodo es servidor de disco
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ // nodo es servidor glusterFS
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ * Creamos array HOME
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ * Marcamos los discos como inicializados
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ * Montamos zona common de SunGrid
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ * Montamos HOME glusterFS
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ * Lanzamos daemon glustrerFS
ĀĀĀ 1.2. Nodo con un disco
ĀĀĀĀĀĀĀĀĀ // nodo es cliente glusterFS
ĀĀĀĀĀĀĀĀĀ * Montamos zona common de SunGrid
ĀĀĀĀĀĀĀĀĀ * Montamos HOME glusterFS
ĀĀĀ 1.3. Nodo sin discos
ĀĀĀĀĀĀĀĀĀĀ * ERROR
2. Dos discos inicializados
ĀĀĀĀ 2.1. Nodo no es servidor de disco
ĀĀĀĀĀĀĀĀĀĀĀ // nodo es cliente glusterFS
ĀĀĀĀĀĀĀĀĀĀ * Montamos zona common de SunGrid
ĀĀĀĀĀĀĀĀĀĀ * Montamos HOME glusterFS
ĀĀĀĀ 2.2. Nodo es servidor de disco
ĀĀĀĀĀĀĀĀĀĀĀ // nodo es servidor glusterFS
ĀĀĀĀĀĀĀĀĀĀĀ * Lanzamos daemon glusterFS
Por ·ltimo, en
caso de tratarse de un nodo nuevo, el script lo a±ade a la cola correspondiente
en Sun Grid con tantos slots como cores tenga la mßquina. El script post_boot.sh se encuentra en los apķndices [
14. Ganglia
Ganglia es un sistema de monitorizaci¾n de clusters vĒa web. Utiliza tecnologĒas como XML para la representaci¾n de los datos, XDR para compactar y mover los datos y RRDTool para el almacenamiento y la visualizaci¾n. Como estß pensado para trabajar con clusters formados por una gran cantidad de nodos, utiliza algoritmos y estructuras de datos que generan overheads muy peque±os entre nodos y proporcionan una alta concurrencia. Ganglia es altamente escalable, siendo capaz de monitorizar sin problemas clusters con miles de nodos.
Estß formado por 5 componentes:
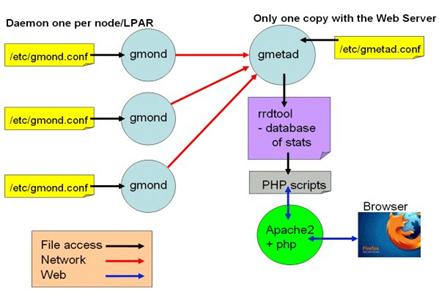
Figura 14.1: Daemons y flujo de datos en un sistema Ganglia
Ę gmond: Es el demonio de monitorizaci¾n. Se trata de un servicio ligero que se instala en todas las mßquinas que queremos monitorizar. Este demonio utiliza el protocolo XDR para recoger informaci¾n del estado y enviarla vĒa XML sobre TCP.
Ę gmetad: Este daemon es el encargado de recolectar informaci¾n servida por otros gmetad y gmond y almacena su estado en bases de datos indexadas de tipo round-robin (rrd). Gmetad provee un mecanismo sencillo para disponer de informaci¾n hist¾rica de un conjunto de mßquinas.
Ę
gmetric:
Ę gstat: Es una aplicaci¾n que permite interactuar con Ganglia directamente y obtener informaci¾n sobre las mķtricas almacenadas.
Ę web: El frontend web expresa la informaci¾n almacenada por gmetad en un interfaz web grßfico usando PHP.
La figura [14.1] muestra los daemons anteriormente descritos asĒ como otros subsistemas involucrados y el flujo de datos entre ellos.
14.1. Instalaci¾n
Ganglia estß disponible como paquete de software del repositorio oficial de Debian. En la distribuci¾n el software Ganglia viene separado en dos partes: ganglia-monitor, que incluye el n·cleo de monitorizaci¾n y el daemon encargado de recolectar de forma local los datos en cada nodo,Ā y gmetad, el daemon que comunica los distintos nodos.
Los instalamos del repositorio oficial Debian:
master-cluster1>
apt-get install ganglia-monitor gmetad
Ganglia utiliza la web como medio para mostrar la informaci¾n del estatus del cluster, por lo que es necesario contar con un servidor web. Instalamos el servidor web Apache[12], por ser el servidor web de uso mßs com·n en entornos UNIX y la preferencia en el Laboratorio de Cßlculo.
Instalamos apache y los paquetes adicionales necesarios:
master-cluster1>
apt-get install apache2
libapache2-mod-php5
La instalaci¾n de apache deja un servidor web operativo corriendo en el puerto 80, con los ficheros de configuraci¾n en /etc/apache2 y el repositorio web en /var/www.
Hacemos visible ganglia para nuestro servidor web. Para ello creamos el fichero /etc/apache2/sites-available/ganglia:
DocumentRoot /var/www/
<Directory /var/www/ganglia>
Options
FollowSymLinks MultiViews
ĀĀĀĀĀĀ AllowOverride None
ĀĀĀĀĀĀ Order allow,deny
allow from all
</Directory>
Y creamos el link simb¾lico desde /etc/apache2/sites-enabled/ganglia. Por ·ltimo hacemos un reload del servidor para que lea la nueva configuraci¾n:
master-cluster1> /etc/init.d/apache2 reload
14.2. Configuraci¾n
Hay dos daemons que controlan la recogida y almacenamiento de datos generados por los nodos del cluster: gmond y gmetad. Como hemos explicado, gmond es el encargado de recolectar la informaci¾n local del host y compartirla vĒa TCP, mientras que gmetad recoge la informaci¾n exportada por otros hosts y la almacena en una base de datos rrd.
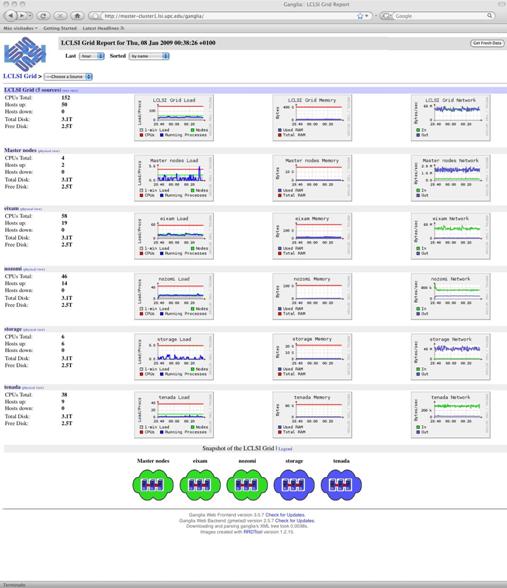
Figura 14.2: Pantalla principal deĀ la web Ganglia
Configuramos las distintas colas, los nodos de almacenamiento y los nodos master como grupos segregados que se monitorizan de forma independiente. Cada uno de estos grupos comparte la informaci¾n generada por gmond con el resto de mßquinas de su grupo y con los nodos master. La comunicaci¾n de cada grupo se realiza por canales multicast, lo que garantiza un menor overhead de trßfico de red.
En los nodos de entrada master-cluster1 y master-cluster2, hay sendos demonios gmetad que recogen informaci¾n de cada grupo. Igualmente, cada grupo cuenta con dos daemons gmetad que recogen la informaci¾n de los nodos de su grupo. Instalamos el gmetad en dos mßquinas para poder disponer de la informaci¾n del grupo si uno de los dos nodos con gmetad caen.
La siguiente tabla muestra los distintos grupos multicast con sus direcciones de red:
Master nodesĀĀĀĀĀĀĀĀĀĀĀ 239.
eixamĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 239.
nozomiĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 239.
tenadaĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 239.
storageĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 239.
Los ficheros gmond.conf y gmetad.conf que controlan los daemons gmond y gmetad respectivamente se
encuentran en los apķndices [19.1.4] y [
14.3. Personalizaci¾n
La informaci¾n que proporciona Ganglia por defecto es enorme, pero echamos en falta informaci¾n especĒfica del sistema de colas. Por ello crearemos algunas mķtricas que mediante shellscripts permitan conocer el estatus del cluster: trabajos en ejecuci¾n y trabajos encolados.
Una mķtrica de Ganglia no es mßs que un valor numķrico con una etiqueta enviado por TCP a una canal multicast mediante el comando gmetric. Este valor es recogido por el daemon gmetad y almacenado en una base de datos rrd. Posteriormente el motor Ganglia transformarß los valores numķricos almacenados en informaci¾n grßfica, si asĒ lo configuramos.
14.3.1. Trabajos en ejecuci¾n:
Obtenemos el
n·mero de trabajos en ejecuci¾n en cada nodo mediante el script jobs_run.sh, que puede consultarse en los apķndices [
Incorporaremos el comando gmetric a un cron de root que irß enviando la informaci¾n a intervalos regulares de 1 minuto:
# JOBS en cola
prioritaria
* * * * *ĀĀĀĀĀĀ /usr/bin/gmetric --name sge_jobs_run
--value `/root/scripts/jobs_run.sh 2> /dev/null` -tint16 --units=procs
--mcast_channel=239.
En cada
cluster habrß que cambiar el canal muticast por el que corresponda. Ademßs de
monitorizar los trabajos en ejecuci¾n, monitorizamos los trabajos que se
ejecutan en colas "nice", que obtenemos con el script jobs_run-slave.sh, disponible en los apķndices [
Asimismo a±adimos un cron que envĒe el n·mero de trabajos en el nodo cada minuto:
# JOBS en cola
subordinada
* * * * *ĀĀĀĀĀĀ /usr/bin/gmetric --name
sge_jobs_run-slave --value `/root/scripts/jobs_run-slave.sh 2> /dev/null`
-tint16 --units=procs --mcast_channel=239.
El resultado es el que se
muestra en la figura [ 14.3].
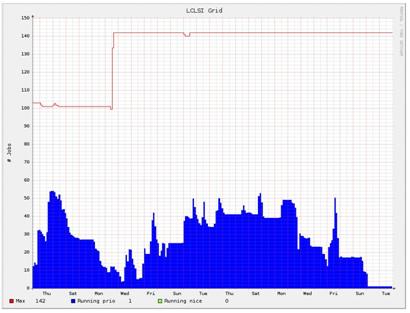
Figura
14.3:Grßfica de la mķtrica jobs_running
14.3.2. Trabajos encolados
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
Otra mķtrica
interesante asociada al sistema de colas es el n·mero de trabajos encolados.
Este valor lo calcularemos en los nodos master mediante el script jobs_queued.sh. Puede encontrarse en los apķndices [
De la misma forma que hacĒamos con los trabajos en ejecuci¾n, creamos una entrada en el cron de root que envĒe el n·mero de trabajos en colados al gmetad cada minuto:
* * * * *ĀĀĀĀĀĀ /usr/bin/gmetric --name jobs_queued --value
`/root/scripts/jobs_queued.sh` -tint16 --units=procs
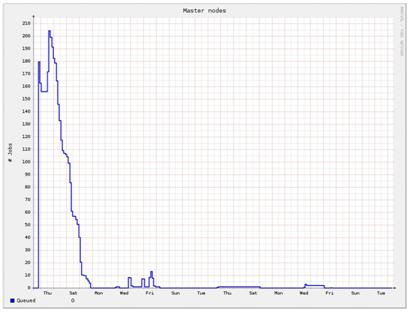
Figura
14.4: Grßfica de la mķtrica jobs_queued
14.3.3. Sensor de temperatura
La temperatura
de
Creamos una
nueva mķtrica con el valor de la temperatura de
A tal efecto
creamos el script temp_max.sh que devuelve la temperatura del core con el valor mßs alto. Su
contenido puede consultarse en los apķndices [
Figura 14.5: Gßfica de la mķtrica temperature_max
El siguiente paso es a±adir el valor obtenido por esta mķtrica a la base de datos rrd. Como con el resto de mķtricas personalizadas lo hacemos utilizando el comando gmetric a intervalos de 1 minuto mediante la programaci¾n de un cron:
# Sensors
* * * * *ĀĀĀĀĀĀ /usr/bin/gmetric --name temperature_max
--value `/root/scripts/temp_max.sh 2> /dev/null` -tint16 --units=degrees
--mcast_channel=239.
Como resultado tendremos una nueva mķtrica llamada temperature_max dentro de la web ganglia disponible para cada nodo del cluster.
14.3.4. Personalizaci¾n web
El siguiente paso es procesar y mostrar en la web de Ganglia la informaci¾n de las mķtricas que hemos creado y que se encuentran almacenadas en las bases de datos rrd. El frontend de Ganglia estß programado en PHP y es fßcilmente modificable.
En el directorio /var/www/ganglia estß el c¾digo PHP con las funciones de procesamiento y visualizaci¾n de los datos y en /var/www/ganglia/template los perfiles que dan forma a la web.
En primer lugar creamos un nuevo perfil "LSI" basado en el perfil por defecto, a±adiendo la informaci¾n extra que queremos mostrar. El perfil estß formado por ficheros HTML con la disposici¾n de los distintos elementos que aparecen en cada una de las pßginas web de Ganglia. Modificamos los siguientes ficheros:
Ę cluster_extra.tpl: A±adimos c¾digo que invoca a la funci¾n php que muestra el n·mero de trabajos en ejecuci¾n del grupo en el caso de colas y el n·mero de trabajos encolados en el caso del grupo Master nodes.
Ę meta_view.tpl: A±adimos informaci¾n acerca del volumen GlusterFS en la pßgina principal.
El contenido
Ēntegro de ambos ficheros estß en los apķndices [
La funci¾n php
que dibuja en pantalla las grßficas se encuentra en el archivo graph.php. A±adimos el c¾digo necesario para dibujar en pantalla las
grßficas que representan los datos generados por nuestras mķtricas. El fichero graph.php se encuentra en los apķndices [
La figura [14.6] muestra la vista general del cluster, con una fila para cada grupo de mßquinas: nodos master, colas eixam, nozomi y tenada y servidores de disco. La fila superior es un sumatorio de los recursos de todos los grupos.
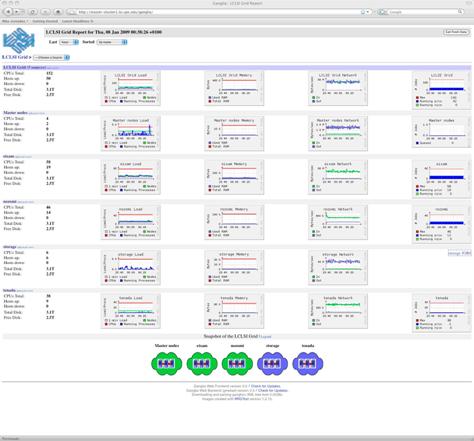
Figura
14.6: Vista general del cluster
Las cuatro columnas de grßficasĀ muestran diferentes recursos de las colas: la carga de CPU, la utilizaci¾n de la memoria, el trßfico de red e informaci¾n acerca de los trabajos del sistema de colas.
Para cada cola se muestra el n·mero de trabajos en ejecuci¾nĀ (color azul) y en ejecuci¾n en modo nice (color verde). La lĒnea roja marca el n·mero mßximo de slots disponibles y por tanto el n·mero mßximo de trabajos concurrentes en ejecuci¾n.
El grupo de nodos master en el campo dedicado al sistema de colas muestra el n·mero de trabajos en la cola de espera.
Adicionalmente, se muestra, en la fila correspondiente a cada cola, el espacio total y el espacio libre de la zona de disco compartida.
Ā
La figura [14.7] muestra el estado de una cola, con un resumen de los principales recursos: carga del sistema, uso de CPU, utilizaci¾n de memoria y de red en la parte superior y el estado de los diferentes nodos que componen el cluster a continuaci¾n.
Cada nodo aparece coloreado seg·n su carga. De esta forma podemos advertir estados altos de carga (color rojo) rßpidamente, sin entrar a comprobar el valor numķrico concreto.
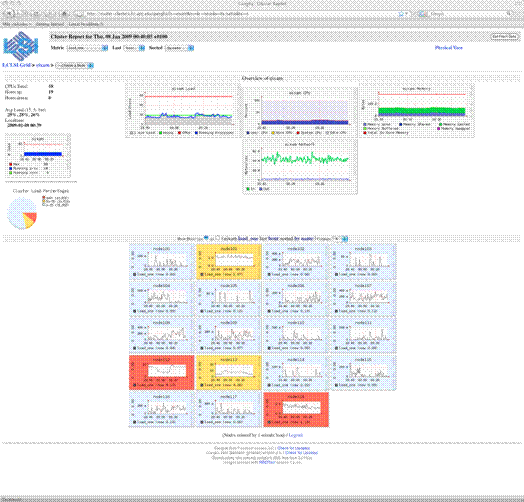
Figura 14.7: Vista de una cola
La grßfica de cada nodo muestra una mķtrica seleccionable desde el men· Metric de la cabecera. Por defecto se muestra la carga del sistema, pero pueden seleccionarse multitud de otras mķtricas, entre ellas las que hemos creado ad-hoc, como sge_jobs_run, sge_jobs_run-slave o temperature_max.
En la parte izquierda aparece la grßfica de trabajos en ejecuci¾n, asĒ como informaci¾n porcentual de la carga del sistema.
La figura [14.8] muestra la informaci¾n de tallada de un nodo, con un resumen textual y las consabidas grßficas de carga, uso de CPU, uso de memoria y trßfico de red en la parte derecha.
En la parte inferior se despliegan las grßficas de todas las mķtricas.
Ā
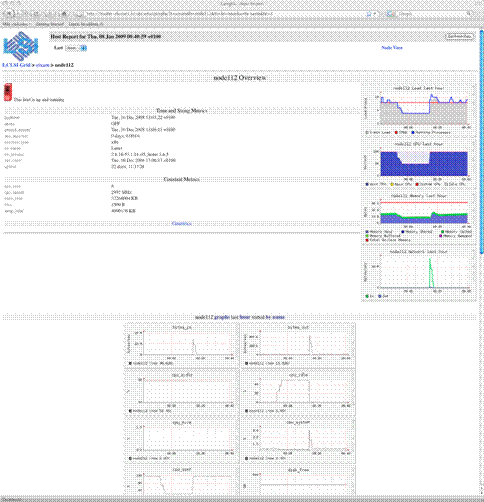
Figura 14.8: Vista de un nodo
15. Nagios
Nagios es un sistema de monitorizaci¾n de redes para entornos UNIX. Examina peri¾dicamente hosts y servicios, avisßndonos cuando se produce alg·n comportamiento inesperado y volviendo a avisarnos cuando el servicio vuelve a la normalidad. Estß especialmente indicado en la monitorizaci¾n de redes con gran cantidad de componentes.
Nagios es la herramienta que utiliza el Laboratorio de Cßlculo de LSI para monitorizar todos sus servidores y servicios.
En los clientes Nagios el daemon nrpe recoge las peticiones enviadas desde el servidor e invoca el plugin apropiado para obtener el valor asociado al estatus del recurso monitorizado. Cuando se produce un fallo en alguno de los servicios monitorizados el sistema nagios envĒa un aviso al administrador.
15.1. Instalaci¾n
Es necesario instalar el cliente nagios en cada uno de los hosts que queremos monitorizar. En nuestro caso lo instalamos en las dos mßquinas master-cluster. De esta manera si se produce el fallo de una de las dos mßquinas seguiremos pudiendo monitorizar el cluster.
Master-cluster1> apt-get
install nagios-nrpe-server
15.2. Configuraci¾n
Monitorizaremos por una parte el estatus del servicio Sun Grid en las mßquinas master (sge_master) y en los nodos de c¾mputo (sge_execd) y por otra la conectividad de red de los nodos servidores de disco. Esto ·ltimo se hace mediante el plugin nrpe_ping, que forma parte del paquete nagios.
15.2.1. Configuraci¾n en cliente
En primer lugar es necesario configurar el cliente nagios indicando la direcci¾n IP del servidor. Ademßs, dado que utilizaremos un plugin que acepta parßmetros, debemos indicar que queremos aceptar este tipo de plugins.Tambiķn configuramos un nuevo comando que nos permitirß conocer el estatus del servicio Sun Grid mediante el script check_sge.sh.
Monitorizamos
el servicio Sun Grid mediante el plugin check_sge.sh. Puede consultarse en los apķndices [
Los plugins nagios son scripts que deben acabar con uno de los siguientes exit status:
Ę 0: El servicio funciona correctamente.
Ę 1: Warning. El servicio presenta alg·n tipo de anomalĒa.
Ę 2: Error. El servicio no funciona.
La salida estßndar puede ser utilizada como un medio para obtener informaci¾n extra sobre el estatus del servicio, por ejemplo el motivo del fallo.
El plugin check_sge.sh acepta como parßmetro el hostname del nodo que queremos chequear.
En funci¾n del hostname comprobaremos si el servicio sge_master o el servicio sge_execd estß corriendo.
15.2.2. Configuraci¾n en servidor
La configuraci¾n del servidor nagios estß formada por una serie de ficheros donde se definen los recursos a monitorizar, los comandos que se utilizarßn para ello y los administradores responsables de los servicios a los que se avisarß en caso de fallo.
El servidor Nagios departamental es la mßquina karpov.lsi.upc.edu. Se trata de una mßquina con sistema Linux Debian en la que se ha instalado el software nagios de Debian. AsĒ pues, encontramos los ficheros de configuraci¾n en /etc/nagios.
En primer lugar definimos el cluster como un servicio a monitorizar. Para ello a±adimos la informaci¾n de las dos mßquinas master-cluster a los ficheros hostgroup.cfg y hosts.cfg:
hostgroup.cfg:
define
hostgroup{
hostgroup_nameĀ cluster
aliasĀĀĀĀĀĀĀĀĀĀ Cluster Servers
membersĀĀĀĀĀĀĀĀ master-cluster1,master-cluster2
contact_groupsĀ admins,cluster-admins
ĀĀĀĀĀĀĀ }
hosts.cfg:
define host{
useĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ generic-host
host_nameĀĀĀĀĀĀĀĀĀĀĀĀĀĀ master-cluster1
aliasĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ master-cluster1
addressĀĀĀĀĀĀĀĀ ĀĀĀĀĀĀĀĀ147.83.20.221
check_commandĀĀĀĀĀĀĀĀĀĀ check-host-alive
max_check_attemptsĀĀĀĀĀ 10
notification_intervalĀĀ 120
notification_periodĀĀĀĀ 24x7
notification_optionsĀĀĀ d,r
ĀĀĀĀĀĀĀ }
define host{
useĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ generic-host
host_nameĀĀĀĀĀĀĀĀĀĀĀĀĀĀ master-cluster2
aliasĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ master-cluster2
addressĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 147.83.20.222
check_commandĀĀĀĀĀĀĀĀĀĀ check-host-alive
max_check_attemptsĀĀĀĀĀ 10
notification_intervalĀĀ 120
notification_periodĀĀĀĀ 24x7
notification_optionsĀĀĀ d,r
}
Monitorizamos
el estado de cada uno de los nodos de computaci¾n del cluster y de los propios
nodos master mediante el comando check_sge. Para
ello creamos tantos servicios como nodos hay en el cluster. Lo hacemos en el fichero services.cfg:
define service{
useĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
generic-serviceĀĀĀĀĀĀĀĀ ; Name of
service template to use
host_nameĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
master-cluster1,master-cluster2
service_descriptionĀĀĀĀĀĀĀĀĀĀĀĀ node100
is_volatileĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0
check_periodĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 24x7
max_check_attemptsĀĀĀĀĀĀĀĀĀĀĀĀĀ 4
normal_check_intervalĀĀĀĀĀĀĀĀĀĀ 5
retry_check_intervalĀĀĀĀĀĀĀĀĀĀĀ 1
contact_groupsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ admins,cluster-admins
notification_intervalĀĀĀĀĀĀĀĀĀĀ 960
notification_periodĀĀĀĀĀĀĀĀĀĀĀĀ 24x7
check_commandĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
check_nrpe_param2!check_sge!node100
}
Repetimos esta configuraci¾n para todos los nodos de computaci¾n del cluster. A destacar que el comando de chequeo tiene dos parßmetros: el nombre del plugin y el parßmetro de ķste que indica el nodo que se estß examinando. Debemos definir un nuevo comando de chequeo que acepte dos parßmetros, ya que por defecto nagios no lo incluye. Lo definimos en el fichero de configuraci¾n checkcommands.cfg:
define command{
command_nameĀĀĀ check_nrpe_param2
command_lineĀĀĀ $USER1$/check_nrpe -H $HOSTADDRESS$ -c
$ARG1$ -a $ARG2$ $ARG3$ $ARG4$
}
Para los nodos de disco creamos un servicio de monitorizaci¾n de conectividad mediante el plugin check_ping:
define service{
useĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
generic-serviceĀĀĀĀĀĀĀĀ ; Name of
service template to use
host_nameĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
master-cluster1,master-cluster2
service_descriptionĀĀĀĀĀĀĀĀĀĀĀĀ Disc1
is_volatileĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0
check_period ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ24x7
max_check_attemptsĀĀĀĀĀĀĀĀĀĀĀĀĀ 4
normal_check_intervalĀĀĀĀĀĀĀĀĀĀ 5
retry_check_intervalĀĀĀĀĀĀĀĀĀĀĀ 1
contact_groupsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ admins,cluster-admins
notification_intervalĀĀĀĀĀĀĀĀĀĀ 960
notification_periodĀĀĀĀĀĀĀĀĀĀĀĀ 24x7
check_commandĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
check_nrpe_param2!check_ping!disc2!99,99%!100,100%
}
Repetimos esta configuraci¾n para todos los nodos servidores de disco del cluster.
El Laboratorio de Cßlculo dispone del un frontend web, que permite una fßcil gesti¾n de la informaci¾n generada por nagios. Tambiķn permite gestionar los avisos, deshabilitar chequeos, etc. Todos los servicios configurados en nagios quedan reflejados automßticamente en la web, accesible desde http://karpov.lsi.upc.edu/nagios.
La figura [15.1] muestra el estatus de los servicios del cluster en la web Nagios.
Ā
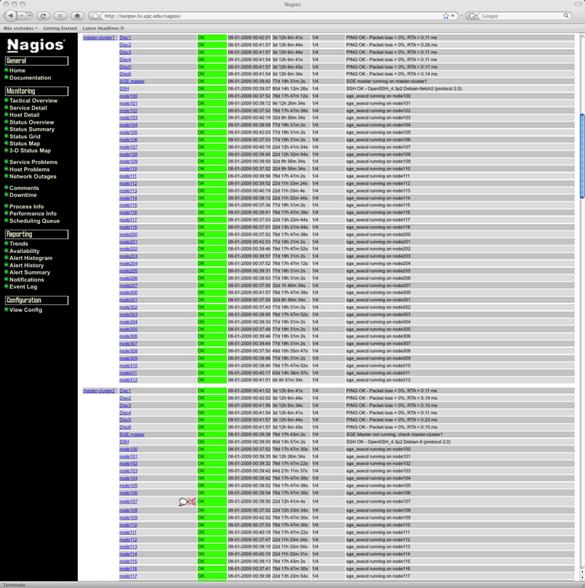
Figura 15.1: Vista de la web Nagios
16. Servicios auxiliares
Una vez vistos los servicios propios del cluster, vamos a tratar una serie servicios auxiliares necesarios para su correcto funcionamiento.
Queda fuera del objetivo de este proyecto tratar en profundidad la configuraci¾n de estos servicios, con los que se asume cierta familiaridad como administrador de sistemas, por lo que nos limitaremos a concretar las particularidades de nuestra configuraci¾n.
16.1. DHCP
DHCP (Dynamic Host Configuration Protocol) es un protocolo de red que permite a las mßquinas de una red obtener la configuraci¾n de red automßticamente.
En el cluster los nodos se identifican por su direcci¾n IP, que determina el rol que juegan, servidor de disco o nodo de computaci¾n. La direcci¾n IP de un nodo es siempre la misma desde el momento en que se fija al darlo de alta. Por ello utilizamos asignaci¾n de IPs manual (o estßtica), que asigna la siempre la misma direcci¾n IP en funci¾n de la direcci¾n MAC de la tarjeta de red.
16.1.1. Instalaci¾n
Instalamos el servidor DHCP en las mßquinas master-cluster y el clienteĀ en el resto de nodos:
master-cluster1>
apt-get install dhcp3-server
node100> apt-get installl dhcp-client
16.1.2. Configuraci¾n del servidor
La configuraci¾n del servidor DHCP[13] reside en /etc/dhcp3/dhcpd.conf. A±adimos la informaci¾n acerca del rango de IPs que vamos a servir y creamos un nuevo grupo en el que fijamos la direcci¾n IP de cada nodo a su direcci¾n MAC.
Para que Tivoli funcione correctamente en conjunci¾n con el servidor DHCP es necesario a±adir la directiva PXEclient.
El fichero de
configuraci¾n dhcpd.conf se encuentra en los
apķndices [
La adici¾n de nuevos nodos supone, en primer lugar, la asignaci¾n de una direcci¾n IP. Esta tarea se lleva a cabo desde el script de alta de nodo, que se trata el apartado dedicado a tareas administrativas [17.1].
Utilizamos cuatro rangos de IPs, uno para las mßquinas master-cluster y servidores de disco y otro para las mßquinas de cada cola (eixam. nozomi y tenada):
HostnameĀĀĀĀĀĀĀĀĀ Funci¾nĀĀĀĀĀĀĀĀĀĀ @IP
master-cluster1ĀĀ masterĀĀĀĀĀĀĀĀĀĀĀ 192.168.0.201
master-cluster2ĀĀ masterĀĀĀĀĀĀĀĀĀĀĀ 192.168.0.202
disc1ĀĀĀĀĀĀĀĀĀĀĀĀ discoĀĀĀĀĀĀĀĀĀĀĀĀ 192.168.0.101
...
Disc199ĀĀĀĀĀĀĀĀĀĀ discoĀĀĀĀĀĀĀĀĀĀĀĀ 192.168.0.199
node100ĀĀĀĀĀĀĀĀĀĀ eixamĀĀĀĀĀĀĀĀĀĀĀĀ 192.168.1.100
...
node199ĀĀĀĀĀĀĀĀĀĀ eixamĀĀĀĀĀĀĀĀĀĀĀĀ 192.168.1.199
node200ĀĀĀĀĀĀĀĀĀĀ tenadaĀĀĀĀĀĀĀĀĀĀĀ 192.168.2.100
...
node299ĀĀĀĀĀĀĀĀĀĀ tenadaĀĀĀĀĀĀĀĀĀĀĀ 192.168.2.199
node300ĀĀĀĀĀĀĀĀĀĀ nozomiĀĀĀĀĀĀĀĀĀĀĀ 192.168.3.100
...
node399ĀĀĀĀĀĀĀĀĀĀ nozomiĀĀĀĀĀĀĀĀĀĀĀ 192.168.3.199
16.1.3. Configuraci¾n de los clientes
En el archivo de configuraci¾n de red /etc/network/interfaces indicamos que la configuraci¾n del interfaz eth0 se hace mediante dhcp:
# This file
describes the network interfaces available on your system
# and how to
activate them. For more information, see interfaces(5).
# The loopback
network interface
auto lo
iface lo inet
loopback
# The primary
network interface
auto eth0
iface eth0 inet
dhcp
De esta forma al arrancar el nodo, la red quedarß configurada automßticamente:
node100> /sbin/ifconfig
eth0ĀĀĀĀĀ Link encap:EthernetĀ HWaddr 00:1C:23:E3:0C:58
ĀĀĀĀĀĀĀĀĀ inet addr:192.168.1.100Ā Bcast:192.168.255.255Ā Mask:255.255.0.0
ĀĀĀĀĀĀĀĀĀ inet6 addr:
fe80::21c:23ff:fee3:c58/64 Scope:Link
ĀĀĀĀĀĀĀĀĀ UP BROADCAST RUNNING MULTICASTĀ MTU:1500Ā
Metric:1
ĀĀĀĀĀĀĀĀĀ RX packets:853664758 errors:0
dropped:82 overruns:0 frame:17
ĀĀĀĀĀĀĀĀĀ TX packets:917038883 errors:0
dropped:0 overruns:0 carrier:0
ĀĀĀĀĀĀĀĀĀ collisions:0 txqueuelen:1000
ĀĀĀĀĀĀĀĀĀ RX bytes:2029030137 (1.8 GiB)Ā TX bytes:2386219895 (2.2 GiB)
ĀĀĀĀĀĀĀĀĀ Interrupt:169
16.2. Exim
Exim es un MTA (Mail Transfer Agent) desarrollado
por
Brevemente, el funcionamiento del sistema de correo electr¾nico es el siguiente: una aplicaci¾n de usuario (MUA) envĒa un mensaje de correo electr¾nico que recibe el MSA (Mail Submission Agent) y lo envĒa al MTA (Mail Transfer Agent). El MTA es la parte mßs importante del sistema de correo. Se encarga de hacer llegar el mensaje del dominio origen al servidor de correo (MTA) del dominio destino. Finalmente el MDS (Mail Delivery Agent) deja el mensaje de correo en el mailbox apropiado.
La misi¾n de Exim dentro del cluster serß gestionar el envio de correos y avisos administrativos generados en cada nodo.
16.2.1. Instalaci¾n
Instalamos Exim[14] en todas las mßquinas del cluster:
master-cluster1>
apt-get install exim4 exim4-config
El paquete exim4-config incluye un frontend que facilita la configuraci¾n de Exim como MTA y como MSA en casos sencillos como el que nos ocupa.
16.2.2. Configuraci¾n
Exim es capaz de funcionar como MTA y como MSA. Las mßquinas master-cluster1 y master-cluster2 funcionarßn como relay de correo para el resto de nodos, reenviando el correo el correo que generado en la intranet al servidor de correo departamental.
En los nodos de computaci¾n y los servidores de disco configuramos Exim como MSA, haciendo que se reenvĒe su correo a cualquiera de los nodos master-cluster.
La configuraci¾n puede hacerse mediante el frontend ejecutando el comando dpkg-reconfigure exim4-config o editando el fichero /etc/exim4/update.exim4.conf.
La
configuraci¾n del sistema de correo de los nodos master y del resto de nodos se
encuentra en los apķndices [
16.3. NTP
La sincronizaci¾n del tiempo es un tema de vital importancia cuando tenemos un conjunto de mßquinas que queremos que se comporten como una sola. Ademßs, el hecho de contar con un sistema de ficheros distribuido obliga a mantener el tiempo de los nodos perfectamente sincronizados.
La sincronizaci¾n de los relojes de las mßquinas del cluster se lleva a cabo mediante el protocolo NTP (Network Time Protocol). En nuestro cluster las mßquinas master-cluster actuarßn como servidoras de tiempo para los nodos. Las propias mßquinas master-cluster sincronizarßn su tiempo, a su vez con el servidor de tiempo departamental.
El hecho de contar con servidores de tiempo propios permite al cluster mantener la hora sincronizada permanentemente independientemente de cualquier fallo externo.
16.3.1. Instalaci¾n
El daemon NTP y las utilidades de gesti¾n asociadas estßn incluidas en el paquete ntp. Lo instalamos en todas las mßquinas del cluster:
master-cluster1> apt-get install ntp
El servicio NTP queda configurado para iniciarse al arrancar la mßquina.
16.3.2. Configuraci¾n
La instalaci¾n deja la configuraci¾n en el fichero /etc/ntp.conf.
Las mßquinas
master-cluster sincronizan su hora con el servidor de tiempo de lsi ntp.lsi.upc.edu y con alguno mßs en caso de fallo de ķste. Ademßs como act·an de
servidor de hora para los nodos del cluster, se debe activar broadcast a la red privada del cluster.
El fichero de configuraci¾n /etc/ntp.conf que controla
el servicio de tiempo en los nodos master-cluster se encuentra en el apķndice [
Los nodos
obtienen el tiempo de los nodos master-cluster y su ntp act·a s¾lo como cliente.
Nuevamente el fichero de configuraci¾n puede encontrarse en el apķndice [
16.4. Dsh
Dsh (distributed shell o dancer's shell) es una utilidad que permite ejecutar comandos en varias mßquinas remotas a la vez, lo que en la prßctica serĒa un bucle de ejecuciones remotas.
Lo utilizaremos desde las mßquinas master-cluster para realizar tareas administrativas en grupos de mßquinas o en la totalidad del cluster.
16.4.1. Instalaci¾n
Instalamos dsh desde el repositorio de software de Debian en las dos mßquinas master-cluster:
master-cluster1>
apt-get install dsh
La instalaci¾n deja la configuraci¾n en /etc/dsh.
16.4.2. Configuraci¾n
dsh por defecto ejecuta los comandos remotos mediante rsh, si bien es posible hacer que utilice ssh. Lo cambiamos en el fichero de configuraci¾n /etc/dsh/dsh.conf:
#default
configuration file for dsh.
# suppled as
part of dancer's shell
verbose = 0
remoteshell =ssh
showmachinenames
= 1
waitshell=1Ā # whether to wait for execution
#remoteshellopt=...
# default
config file end.
La configuraci¾n de dsh incluye un directorio groups en el que podemos crear ficheros de texto con hostnames de grupos de mßquinas. En nuestro caso creamos un grupo para cada cola, uno mßs para las mßquinas servidoras de disco, y un ·ltimo grupo para las mßquinas master-cluster:
master-cluster1:/etc/dsh/groups>Ā ls -la
total 32
drwxr-xr-x 2
root root 4096
drwxr-xr-x 3
root root 4096
lrwxrwxrwx 1
root rootĀĀ 16
-rw-r--r-- 1
root rootĀ 153
-rw-r--r-- 1
root rootĀĀ 32
-rw-r--r-- 1
root rootĀ 104
-rw-r--r-- 1
root rootĀĀ 36
-rw-r--r-- 1
root rootĀĀ 64
El fichero machines.list incluye las mßquinas de todos los grupos y es ·til cuando queremos ejecutar comandos en todas las mßquinas.
El funcionamiento de dsh es sencillo:
master-cluster1> dsh -a comando
Ejecuta el comando indicado en todas las mßquinas del cluster.
master-cluster1> dsh -g nombre_grupo comando
Ejecuta el comando indicado en las mßquinas de un grupo concreto.
La ejecuci¾n de los comandos en cada una de las mßquinas se realiza con conexiones ssh secuenciales. Es posible realizarlas todas de forma concurrente mediante la opci¾n -c.
16.5. Backup
El Laboratorio de Cßlculo de LSI cuenta con un sistema de backups departamental como respaldo de datos de usuario y sistemas de losĀ servidores. Los backupsĀ permiten disponer de una copia mßs o menos reciente de la informaci¾n en caso de fallo en los sistemas de almacenamiento o de borrado accidental.
Durante el mes de enero de 2009 incorporaremos el cluster al servicio de backups, realizando copia de los sistemas de las mßquinas master-cluster y de la zona de disco distribuido. Para ello se ha comprado un robot SUN StorageTek SL24 Tape Autoloader que contendrß tambiķn copias de los servidores de proyecto.
16.5.1. Instalaci¾n
El software utilizado para la realizaci¾n de los backups es Sun StorageTek Enterprise Backup Sogftware v7.3., disponible en un CD de instalaci¾n para m·ltiples plataformas. Para su instalaci¾n basta con descomprimir el fichero tar correspondiente a nuestra plataforma. Lo instalamos las dos mßquinas master-cluster:
master-cluster1> cd /
master-cluster1>
tar xfz
/root/files/lgtoclnt-7.4-1.i686.tgz
16.5.2. Configuraci¾n
En este apartado abordaremos la parte cliente de la configuraci¾n, ya que la configuraci¾n deĀ la parte servidor queda fuera del ßmbito de administraci¾n del cluster.
El cliente de backup se configura como un daemon que se ejecuta al arrancar la mßquina y permanece en ejecuci¾n atendiendo las peticiones del servidor. Hacemos que el cliente se inicie al arrancar la mßquina master-cluster2 incluyendo el inicio del servicio de backup enĀ el script /etc/init.d/rc.sistemes:
/usr/sbin/nsrexecd
-s nsrhost -s nsrserverhost -s nemesis -s davinci
En las pruebas realizadas comprobamos que la tasa de transferencia al realizar el backup de la zona de disco compartida era muy baja, lo que suponĒa una demora de mßs de un dĒa para realizar el backup de unos 500 GB. Esto se debe, sin lugar a dudas, a alguna incompatibilidad entre el software de backup y el sistema de ficheros GlusterFS.
Como soluci¾n decidimos realizar el backup de cada uno de los discos que conforman la zona GlusterFS de forma independiente. Recordemos que la zona GlusterFS estß formada por grupos de dos servidores con datos replicados. Estos discos cuentan con un sistema de ficheros ext3 y son accesibles desde el propio servidor de discos, si bien la modificaci¾n directa supondrĒa la corrupci¾n de los datos.
Exportamos por
NFS el disco de una de las mßquinas de cada AFR de la zona GlusterFS a master-cluster2. En la actualidad la
zona GlusterFS cuenta con 6 servidores (disc1,
disc2, disc3, disc4, disc5 y disc6)
organizados en 3 AFRs. Configuramos la exportaci¾n del disco de los nodos disc2, disc4 y disc6 mediante el fichero /etc/exports, que puede consultarse en los apķndices [
La exportaci¾n se hace como s¾lo lectura para que no exista posibilidad alguna de escritura en esta zona fuera del control del sistema GlusterFS.
En master-cluster2 montamos las tres zonas exportadas. Para que estas zonas se monten de forma automßtica, a±adimos las siguientes lĒneas al fichero /etc/fstab:
disc2:/mnt/glusterfs/homeĀĀĀĀ /mnt/backup/disc2 nfsĀĀ defaultsĀĀĀ 0ĀĀĀĀ 0
disc4:/mnt/glusterfs/homeĀĀĀĀ /mnt/backup/disc4 nfsĀĀ defaultsĀĀĀ 0ĀĀĀĀ 0
disc6:/mnt/glusterfs/homeĀĀĀĀ /mnt/backup/disc6 nfsĀĀ defaultsĀĀĀ 0ĀĀĀĀ 0
El backup de la zona GlusterFS se completa con la copia de la partici¾n conĀ el namespace /mnt/glusterfs/home-ns.
Tambiķn guardamos backup de la partici¾n raĒz de master-cluster2, con lo que tendremos copia del sistema operativo y de todo el software instalado, asĒ como de Tivoli y las imßgenes de disco de los nodos.
Por ·ltimo guardamos backup de la partici¾n common con la configuraci¾n de Sun Grid.
Resumiendo, hacemos backup de los directorios siguientes:
/
/mnt/backup/disc2
/mnt/backup/disc4
/mnt/backup/disc6
/mnt/glusterfs/home-ns
/mnt/glusterfs/sge-common
16.6.
EstadĒsticas web
El cluster cuenta con un servidor web que permite acceder al servicio de monitorizaci¾n ganglia y la descarga de manuales, documentaci¾n y presentaciones.
El software awstats se encarga de la generaci¾n de estadĒsticas en acceso a servidores web en base a la informaci¾n almacenada en sus logs. Proporciona un informe pormenorizado de las pßginas web mßs visitadas asĒ como las direcciones que la consultan, browsers utilizados, etc.
16.6.1. Instalaci¾n
Instalamos el paquete de software awstats en las dos mßquinas master-cluster:
master-cluster1>
apt-get install awstats
16.6.2. Configuraci¾n
awstats utiliza un programa en perl para extraer del servidor web informaci¾n con la que generar estadĒsticas accesibles vĒa web.
La
configuraci¾n estß en el fichero /etc/awstats/awstats.conf, donde indicamos el origen de los logs (servidor web), el tipo de
servidor web (apache) y el dominio.
El fichero awstats.conf puede consultarse en los apķndices [
Las estadĒsticas se generan con la invocaci¾n del script awstats.pl. Creamos un cron que llame a este script una vez al dĒa:
# awstats
0 0 * * *ĀĀĀĀĀĀ /var/www/awstats/cgi-bin/awstats.pl
-update ¢config = master-cluster1.lsi.upc.edu
Por ·ltimo s¾lo queda hacer que las informaci¾n generada por awstats sea visible en nuestra web. Para ello creamos la configuraci¾n pertinente en el servidor apache de los nodos master-cluster, a±adiendo las siguientes lĒneas al fichero /etc/apache2/apache2.conf o creando el fichero /etc/apache2/sites-available/awstats:
#
# Directives to
allow use of AWStats as a CGI
#
Alias
/awstatsclasses "/var/www/awstats/classes/"
Alias
/awstatscss "/var/www/awstats/css/"
Alias
/awstatsicons "/var/www/awstats/icon/"
ScriptAlias
/awstats/ "/var/www/awstats/cgi-bin/"
#
# This is to
permit URL access to scripts/files in AWStats directory.
#
<Directory
"/var/www/awstats/">
ĀĀĀ Options None
ĀĀĀ AllowOverride All
ĀĀĀ Order allow,deny
ĀĀĀ Allow from all
</Directory>
<Directory
"/var/www/awstats/cgi-bin/">
ĀĀĀ Options None
ĀĀĀ AllowOverride All
ĀĀĀ Order allow,deny
ĀĀĀ Allow from all
</Directory>
Las estadĒsticas serßn visibles en la url:
http://master-cluster1.lsi.upc.edu/awstats/awstats.pl?config=master-cluster1.lsi.upc.edu.
Las figuras [16.1] y [16.2] muestran
parte del contenido de las estadĒsticas generadas por awstats.
Figura 16.1: Web awstats (1)
Figura 16.2: Web awstats (2)
Restringiremos el acceso a las estadĒsticas a los administradores del cluster, ya que que esta informaci¾n no es relevante para los usuarios, mediante un fichero .htaccess en el directorio /var/www/awstats/cgi-bin, en el que se encuentra el programa awstats.pl.
El fichero de
control de acceso a la web de estadĒsticas .htaccess se encuentra en los apķndices [
16.7. Wake on LAN
Wake on LAN o WOL es un servicio que permite el arranque remoto de mßquinas apagadas dentro de una red local. Mediante un paquete especial (MagicPacket) enviado a la direcci¾n MAC de la tarjeta de red de la mßquina que deseemos iniciar remotamente, que previamente se ha configurada para aceptar este tipo de paquetes.
Para que el
proceso de WOL tenga ķxito ķste debe estar soportado por
La utilidad ethtool permite configurar diversos aspectos de las tarjetas de red. En nuestro caso queremos que las mßquinas se enciendan al recibir un MagicPacket, por lo que deberemos ejecutamos el comando:
node100> ethtool ¢s eth0 wol g
Incorporamos este comando al script /etc/initr.d/rc.sistemes para que se ejecute cada vez que la mßquina arranque. AsĒ su tarjeta de red quedarß preparada para WOL.
Estando apagada, el siguiente comando inducirß el arranque de la mßquina con la direcci¾n MAC especificada :
master-cluster1>
/usr/bin/etherwake ¢i eth0 @MAC
Utilizaremos
este el procedimiento de arranque remoto desde los nodos master-cluster.
Disponemos de un par de scripts que permiten arrancar y apagar las mßquinas, ya
sea individualmente o por grupos. Los scripts wakeup-cluster.sh y halt-cluster.sh pueden encontrarse en
los apķndices [
16.8. NAT
Las mßquinas del cluster conforman una red privada que las aĒsla del exterior. Master-cluster1 y master-cluster2 estßn conectadas a la red del cluster y a la red de LSI y son el punto de entrada al cluster de los usuarios.
Los motivos que nos llevan a incluir las mßquinas del cluster en una red privada son los siguientes:
Ę No se utilizan direcciones IP p·blicas, un recurso limitado actualmente.
Ę Las mßquinas del cluster se aĒslan del trßfico de la red de LSI. En un cluster de computaci¾n es de vital importancia disponer de una red con el mayor ancho de banda posible. La uso red privada evita que el trßfico broadcast generado por servicios ajenos al cluster entre en ella.
Ę Seguridad. Las mßquinas con direcciones IP p·blicas son universalmente accesibles y se necesitan servicios adicionales de securizaci¾n como filtros y firewalls para protegerlas. Dado que el acceso directo no es necesario, el uso de IPs privadas proporciona un grado adicional de seguridad.
Con este esquema de red, el trßfico desde fuera del cluster estß cerrado, pero tambiķn lo estß el trßfico desde el cluster hacia el exterior. Esto puede representar un problema para cierto software que necesita acceder al exterior.
Es el caso de
software como Matlab o Maple, que hacen uso de licencias
alojadas en servidores de licencias flotantes.
En nuestro cluster los programas se ejecutan en mßquinas que se encuentran dentro de una red privada, sin acceso al exterior. Para que el software con licencias flotantes pueda ejecutarse es necesario que se permita la conexi¾n con el exterior.
NAT (Network Address Translator) es un mecanismo utilizado en routers IP que permite intercambiar paquetes entre dos redes enmascarando la direcci¾n origen mediante la conversi¾n en tiempo real de las direcciones utilizadas en los paquetes.
Bßsicamente lo que haremos serß configurar el router de la red del cluster, las mßquinas master-cluster, para que modifiquen el campo de direcci¾n origen de los paquetes generados por las mßquinas de computaci¾n. La direcci¾n original, privada, se cambiarß por una direcci¾n del rango de LSI, en este caso la direcci¾n de la mßquina que act·e como router.
A efectos
prßcticos, todas las peticiones de licencia desde el cluster llegarßn al
servidor de licencias flotantes de
La activaci¾n del NAT en las mßquinas master-cluster requiere la activaci¾n de las opciones de routing correspondientes en el kernel:
Ę Networking options
o Network Packet Filtering
¦ IP: Netfilter Configuration
Ę
Connection
Tracking (required for masq/NAT) [M]
Ę Full NATĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ Ā [M]
Las mßquinas master-cluster, que actuarßn como gateway, deben aceptar el reenvĒo de paquetes provenientes de la red del cluster. Para ello activamos la opci¾n ip_forwarding:
master-cluster1> echo 1 > /proc/sys/net/ipv4/ip_forward
Asimismo es necesario que en todas las mßquinas de computaci¾n se a±ada una ruta estßtica a la tabla de routing indicando que el Gateway por defecto es una mßquina master-cluster:
node100> route add default gw 192.168.0.201
A±adimos este comando al script /etc/init.d/rc.sistemas para que estos cambios se realicen al arrancar el nodo.
17. Tareas administrativas
Los scripts de administraci¾n estßn en el directorio /root/scripts de las dos mßquinas master-cluster y pueden ejecutarse indistintamente desde cualquiera de ellas.
17.1. Alta de nodo
El proceso de alta de nuevos nodos estß casi totalmente automatizado. La utilizaci¾n de Tivoli (capĒtulo [13]) como sistema de instalaci¾n de imßgenes y la posterior personalizaci¾n del sistema operativo mediante shellscripts, explicado en el apartado [13.3], permiten que el nuevo nodo estķ operativo con una intervenci¾n mĒnima por parte del administrador.
El alta de usuario se hace mediante el script alta_nodo.sh. Se trata de un script interactivo que guarda la informaci¾n del nodo y lo da de alta en los diferentes servicios del cluster. Concretamente, pregunta los siguientes datos:
1. Grupo al que pertenece el nodo (eixam, nozomi, tenada, servidor de disco).
2. Direcci¾n MAC
3. Direcci¾n IP
4. En caso de tratarse de un servidor de disco, el rol que juega, Primario o Secundario, y su pairnode.
Con estos datos, configura los siguientes servicios:
1.
Dar de alta al nuevo nodo en
el DHCP, asociando
2. A±ade entrada en el fichero /etc/hosts.
3. A±ade nueva entrada a fichero /root/files/nodes/nodes con informaci¾n del nodo, su rol y la cola a la que pertenece.
4. Incorpora el nuevo nodo a las listas de dsh.
5. Da de alta el nodo con permisos administrativos en Sun Grid.
6. Copia la versi¾n actualizada de los ficheros hosts y nodes a todos los nodos del cluster.
7. EnvĒa mail al administrador del cluster informando del alta del nuevo nodo.
El script alta_nodo.sh puede
encontrarse en los apķndices [
Tras ejecutar
el script tan s¾lo resta dar de alta el nodo en el servidor de imßgenes. Para
ello seguimos los pasos indicados en el apartado [13.2]. Una vez dado de alta
en Tivoli y previa configuraci¾n en
Tan solo quedarß dar de alta el nodo en el sistema de monitorizaci¾n nagios como indicamos en el apartado [15.2.1].
Sustituci¾n de un nodo
Cuando se sustituye un nodo por otro nuevo no se sigue el procedimiento de alta de nodo, sino que se modifica la configuraci¾n del servidor DHCP y del Tivoli, sustituyendo la direcci¾n MAC de la mßquina antigua por la de la nueva. Una vez hechos estos cambios basta con conectar el nuevo nodo a la red y encenderlo. Tras unos minutos la imagen de sistema quedarß instalada y el nodo estarß operativo.
17.2. Alta de usuario
Los usuarios del cluster son usuarios locales, independientes del resto de sistemas del Departamento, siguiendo la polĒtica de autonomĒa del cluster. Ahora bien, todo usuario del cluster debe ser usuario de LSI. De hecho, tanto el username como el password se obtienen del servicio de NIS departamental. Esto es necesario porque permite a los usuarios utilizar su username y password de LSI para acceder al cluster, evitando tener que recordar un nuevo username y password.
El alta de nuevos usuarios se realiza mediante el script alta_usuario.sh, que tiene como parßmetros el username y el grupo o cola al que pertenece el nuevo usuario. El username pertenecer a LSI. Con el username y el password cifrado obtenido de las NIS, se realizan las siguientes acciones:
1. Se a±ade informaci¾n del usaurio a los ficheros passwd, shadow y group.
2. Se crea el home del nuevo usuario en el filesystem distribuido.
3. Se a±ade entrada con username y grupo a fichero /etc/allowed_users.
4. Propaga la informaci¾n (passwd, shadow, group y allowed_users) a todos los nodos del cluster.
5. Por ·ltimo a±ade el usuario a la lista de acceso de la cola correspondiente en Sun Grid.
El script alta_usuario.sh y los scripts auxiliares build_homes.sh
y build_users.sh puede encontrarse en los apķndices [
Una vez el alta ha sido realizada s¾lo queda enviar mail informando al usuario y a su profesor responsable.
18. Conclusiones
18.1. Objetivos y requisitos cumplidos
Al iniciar este proyecto planteamos dos objetivos:
Ę
La implantaci¾n de un nuevo sistema de clustering para el
Departamento de LSI.
Ę
La creaci¾n de una documentaci¾n que sirviese como
referencia para el Laboratorio de Cßlculo de LSI
El nuevo
cluster ha sido implementado en el plazo previsto y estß en producci¾n desde el
Para estos dos objetivos nos habĒamos fijado una serie de requisitos. Veamos c¾mo los hemos cumplido.
18.1.1. El nuevo cluster
El nuevo cluster debĒa tener una serie de componentes que proporcionasen el servicio de calidad esperado:
Ę
Un software de clustering: el sistema de gesti¾n de colas Sun Grid.
Ę
Un espacio de disco compartido de usuario: el filesystem
distribuido paralelo GlusterFS.
Ę
Alta disponibilidad: Heartbeat.
Ę
Un sistema de gesti¾n de imßgenes: el software Tivoli.
Ę
Un sistema de monitorizaci¾n: Ganglia juntamente con el servicio de monitorizaci¾n departamental Nagios.
Ę
Amķn de otros servicios bßsicos como correo, sincronizaci¾n
de tiempo, etc.
Todos estos servicios han sido integrados en lo que es el nuevo cluster del Departamento de LSI.
Las dos piedras angulares a la hora de plantear la arquitectura del nuevo cluster eran, por una parte un software de clustering robusto y eficiente y por otra un sistema de ficheros paralelo, estable y escalable. Tras el largo perĒodo de pruebas y la experiencia acumulada durante el tiempo que lleva en producci¾n el nuevo cluster podemos asegurar que estos objetivos se han cubierto con creces.
La capacidad de proceso de Sun Grid, utilizado actualmente en los mayores clusters del mundo, queda patente en nuestras pruebas con centenares de usuarios y miles de procesos concurrentes.
Por otra parte con GlusterFS hemos encontrado el sistema de ficheros que es capaz de sacar el mayor partido al hardware del que disponemos sin renunciar a nuestros requerimientos de estabilidad, rendimiento y flexibilidad. Su rendimiento es muy bueno si lo comparamos con sistemas NFS convencionales y, lo que es mßs importante, se ha mostrado como un producto muy estable.
La cuidada elecci¾n de cada uno de los componentes del cluster junto con la aplicaci¾n allß donde fuere necesario de productos especĒficos como heartbeat, proporcionan alta disponibilidad en todas las partes del cluster.
Durante la fase de pruebas la estabilidad de nuestra soluci¾n qued¾ demostrada ante fallos hardware simulados de distintos componentes, desconexiones de red y shutdowns de los distintos tipos de nodos. El tiempo mßximo de recuperaci¾n ante el fallo mßs grave posible, el fallo de un nodo master, no supera los dos minutos, lo que es poco para un sistema de la complejidad del nuestro.
18.1.2. La documentaci¾n
La documentaci¾n tambiķn debĒa cumplir una serie de requisitos. DebĒa ser una documentaci¾n clara, concisa y no debĒa omitir informaci¾n bßsica para el entendimiento de los conceptos mßs tķcnicos. Al fin y al cabo se trata de un documentaci¾n que deberĒa servir como referencia al Laboratorio de Cßlculo de LSI, formado por administradores de sistemas con experiencia pero que podrĒan no estar familiarizados con los clusters de computaci¾n.
Si bien se ha intentado escribir este documento con estos requisitos en mente, serß el uso que se haga del mismo el que nos dirß si los objetivos se han cumplido. Fuere como fuere, se trata de un documento vivo, abierto a crĒticas y sugerencias, que pretende servir como base a la documentaci¾n de futuras mejoras que se implementen en el Cluster.
18.2. Planificaci¾n y estudios de costes
La realizaci¾n
de este proyecto ha tenido un coste temporal y econ¾mico. A continuaci¾n
haremos el desglose de estos costes.
18.2.1. Planificaci¾n temporalĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
La
planificaci¾n temporal contempla el tiempo de desarrollo de los dos objetivos
que nos marcamos al comenzar este proyecto:
Ę
Implementaci¾n
del nuevo cluster: del 2 de Enero al
Ę
Documentaci¾n
del sistema y del proyecto: a partir del 15 de Octubre (2 meses).
Evidentemente
una parte importante de la documentaci¾n se realiz¾ durante la fase de
implementaci¾n, de la misma forma que durante el tiempo que se escribĒa la
documentaci¾n se realizaron ajustes en el sistema.
A continuaci¾n
vamos a detallar en el tiempo el trabajo realizado en cada una de las dos fases:
Fase
de implementaci¾n
Como hemos
comentado durante la fase de implementaci¾n tambiķn se llev¾ a cabo parte de la
documentaci¾n. Concretamente se document¾:
Ę
La parte correspondiente al anßlisis
preliminar, con la descripci¾n de los objetivos y requerimientos del proyecto.
Ę
Todas las instrucciones de instalaci¾n
y configuraci¾n asĒ como los ficheros de configuraci¾n y scripts asociados a
los distintos componentes del cluster.
Durante gran
parte del tiempo que dur¾ la implementaci¾n del nuevo cluster, los tres
clusters antiguos siguieron prestando servicio. Todas las pruebas se llevaron a
cabo en nodos nuevos que se habĒan comprado pero que no se habĒan a±adido a sus
respectivos clusters. S¾lo durante las dos semanas (1 al 15 de Septiembre) que
dur¾ la fase de integraci¾n del nuevo sistema y previo acuerdo con los
usuarios, paramos los clusters antiguos.
Dado que mi
trabajo en el Laboratorio de Cßlculo no se reduce a la administraci¾n de
clusters, mi dedicaci¾n no pudo ser total. Fui descargado de parte de mis
obligaciones con el fin de avanzar el desarrollo lo mßximo posible, quedando mi
dedicaci¾n al proyecto finalmente en unas 5 horas diarias de lunes a viernes.
La siguiente
tabla muestra la planificaci¾n durante la fase de implementaci¾n:
|
FASE
DEL PROYECTO |
ESTIMACION INICIAL |
PLANIFICACIėN REAL |
DESVIACIėN (ACUMULADA) |
|
Estudio
del cluster antiguo |
|||
|
Fecha
inicio Fecha
fin Tiempo |
02/01 04/01 15
horas |
02/01 04/01 15
horas |
0 |
|
Estudio
de sistemas de clustering |
|||
|
Fecha
inicio Fecha
fin Tiempo |
07/01 14/01 30
horas |
07/01 11/01 25
horas |
-5
(-5) |
|
Estudio de sistemas de ficheros
paralelos |
|||
|
Fecha
inicio Fecha
fin Tiempo |
15/01 22/01 30
horas |
14/01 22/01 35
horas |
+5
(0) |
|
Creaci¾n
de infraestructura de pruebas |
|||
|
Fecha inicio Fecha fin Tiempo |
23/01 25/01 15
horas |
23/01 25/01 15
horas |
0
(0) |
|
Dise±o
del nuevo cluster (v1.0) |
|||
|
Fecha inicio Fecha fin Tiempo |
28/01 31/01 20
horas |
28/01 31/01 20
horas |
0
(0) |
|
Sun
Grid: estudio, configuraci¾n y pruebas |
|||
|
Fecha inicio Fecha fin Tiempo |
01/02 15/02 55
horas |
04/02 13/02 40
horas |
-15
(-15) |
|
Lustre
(v1.0): estudio, configuraci¾n y pruebas |
|||
|
Fecha inicio Fecha fin Tiempo |
18/02 03/03 55
horas |
14/02 10/03 95
horas |
+40
(+25) |
|
Revisi¾n
del dise±o (v1.1) |
|||
|
Fecha inicio Fecha fin Tiempo |
04/03 06/03 15
horas |
11/03 13/03 15
horas |
+0
(+25) |
|
Lustre
(v1.1): configuraci¾n y pruebas |
|||
|
Fecha inicio Fecha fin Tiempo |
07/03 27/03 55
horas |
11/03 07/04 80
horas |
+25
(+50) |
|
Revisi¾n
del dise±o (v2.0) |
|||
|
Fecha inicio Fecha fin Tiempo |
28/03 02/04 20
horas |
08/04 10/04 15
horas |
-5
(+45) |
|
GlusterFS
(v2.0): estudio, configuraci¾n y pruebas |
|||
|
Fecha inicio Fecha fin Tiempo |
03/04 17/04 55
horas |
11/04 02/05 75
horas |
+20
(+65) |
|
Heartbeat:
estudio, configuraci¾n y pruebas |
|||
|
Fecha inicio Fecha fin Tiempo |
18/04 02/05 55
horas |
05/05 23/05 75
horas |
+20
(+85) |
|
Ganglia: estudio, configuraci¾n y pruebas |
|||
|
Fecha inicio Fecha fin Tiempo |
05/05 16/05 50
horas |
26/05 11/06 65
horas |
+15
(+100) |
|
Tivoli: estudio, configuraci¾n y
pruebas |
|||
|
Fecha inicio Fecha fin Tiempo |
19/05 30/05 50
horas |
12/06 25/06 50
horas |
+0
(+100) |
|
Automatizaci¾n de procedimientos |
|||
|
Fecha inicio Fecha fin Tiempo |
02/06 13/06 50
horas |
26/06 21/07 90 |
+40
(+140) |
|
Pruebas del sistema completo (de
pruebas) y planificaci¾n de la implantaci¾n |
|||
|
Fecha inicio Fecha fin Tiempo |
16/06 27/06 35
horas |
22/07 31/07 30
horas |
-5
(+135) |
|
Implantaci¾n del nuevo sistema |
|||
|
Fecha inicio Fecha fin Tiempo |
30/07 11/07 20
horas |
01/09 12/09 20
horas |
+30
(+135) |
|
Traspaso de datos |
|||
|
Fecha inicio Fecha fin Tiempo |
14/07 17/07 20
horas |
15/09 17/09 20
horas |
+0
(+135) |
|
Pruebas de estabilidad y benchmarking
del sistema final |
|||
|
Fecha inicio Fecha fin Tiempo |
18/07 25/07 30
horas |
12/09 14/09 15
horas* |
-15
(+120) |
La siguiente
tabla muestra, a modo de resumen, las fechas y horas que se planificaron
inicialmente y las que se dedicaron en realidad:
|
FASE
DEL PROYECTO |
ESTIMACIėN INICIAL |
PLANIFICACIėN FINAL |
DESVIACIėN (ACUMULADA) |
|
Implementaci¾n |
|||
|
Fecha inicio Fecha fin Tiempo |
02/01 17/07 675
horas |
02/01 17/09 795
horas |
+120
horas |
Los datos
muestran una desviaci¾n de casi dos meses de trabajo respecto a la estimaci¾n
inicial.Ā Los problemas encontrados en la
puesta a punto del filesystem paralelo tienen gran parte de la culpa.
A mediados del
mes de mayo, viendo que acumulßbamos un retraso considerable, decidimos
retrasar la fecha de puesta en marcha del nuevo cluster hasta el dĒa 15 de
Septiembre. Finalmente el cluster fue puesto en marcha el dĒa previsto y los
usuarios pudieron comenzar a utilizarlo mientras realizßbamos la migraci¾n de
datos de los clusters antiguos.
Documentaci¾n
La
documentaci¾n debĒa realizarse una vez finalizado el proyecto, siendo el ·nico
lĒmite la fecha de presentaci¾n de este proyecto de final de carrera en Enero
de 2009.
Dado que
durante la fase de implementaci¾n se habĒan documentado todos los
procedimientos de forma exhaustiva, sabĒamos que una buena parte de la
documentaci¾n estaba ya hecha. Con esto en mente, pensamos que el plazo de dos
meses serĒa mßs que suficiente para llevarla a cabo.
La siguiente
tabla muestra de forma aproximada el tiempo estimado y el tiempo dedicado
realmente a realizar la documentaci¾n:
|
FASE
DEL PROYECTO |
ESTIMACIėN INICIAL |
PLANIFICACIėN FINAL |
DESVIACIėN (ACUMULADA) |
|
Documentaci¾n |
|||
|
Fecha inicio Fecha fin Tiempo |
220
horas |
230
horas |
+10
horas |
La desviaci¾n total sobre el tiempo estimado inicialmente ha
sido de 130 horas.
18.2.2. Coste econ¾micoĀĀĀĀĀ
El coste econ¾mico de este proyecto se divide en tres partes:
Ę Hardware: el coste de los nodos y resto de componentes fĒsicos del cluster.
Ę Software: el coste de los programas necesarios para el funcionamiento del cluster.
Ę Personal: el coste de la mano de obra utilizada durante la implementaci¾n.
Hardware
La siguiente tabla enumera cada uno de los componentes fĒsicos del cluster junto con su precio:
|
Cantidad |
Componente |
Precio
(Ć) |
|
12 |
Nodos del antiguo cluster |
24.840 |
|
32 |
Nodos nuevos (Dell) |
111.360 |
|
6 |
Nodos servidores de disco |
10.440 |
|
1 |
Switch 3Com gigabit de 48
puertos |
1.850 |
|
1 |
Switch 3Com gigabit de 16
puertos |
1.044 |
|
2 |
Switch
Cisco gigabit estacable a 36 Gb/s |
17.400 |
|
3 |
Rack
(cableado+alimentaci¾n elķctrica) |
24.012 |
|
50 |
Cable UTP categorĒa 6 |
5.220 |
|
2 |
Multiplexador de consolas
Dell |
3.944 |
|
50 |
Cable para multiplexador
de consolas Dell |
5.220 |
|
|
||
|
Total |
205.330 |
|
El coste de todo el hardware que compone el cluster es de 205.330 Ć.
Software
Todo el software utilizado para la realizaci¾n de este proyecto, a excepci¾n del software de gesti¾n de imßgenes Tivoli, es software open source, cuyo c¾digo es abierto y gratuito.
En cuanto a
Tivoli si bien es de pago,
El coste de la licencia del software de backup queda imputado al Departamento, por lo que tampoco lo hemos tenido en cuenta.
Personal
La complejidad
del proyecto hacĒa necesaria la participaci¾n de mßs de una persona.
Concretamente el equipo de trabajo que ha dise±ado e implementado este proyecto
estß formado por:
Ę
Un
jefe de proyecto: encargado de realizar la
planificaci¾n y dirigir el desarrollo del proyecto para obtener los objetivos
planteados minimizando las posibles desviaciones. Su dedicaci¾n al proyecto es
de 7 horas semanales.
Ę
Un
administrador senior de sistemas: que se encarga de recolectar,
presentar y evaluar las distintas alternativas asĒ como de implementar la
soluci¾n consensuada con el jefe de proyecto. Su dedicaci¾n es de 25 horas
semanales.
Ā
Ę
Un
administrador junior de sistemas:Ā realiza tareas rutinarias de apoyo, con una dedicaci¾n
es de 20 horas semanales.
La siguiente tabla muestra el coste humano del proyecto:
|
Componente |
Horas
trabajadas |
Coste/hora
(Ć) |
Coste
total (Ć) |
|
Jefe de proyecto |
185 |
70 |
12.950 |
|
Administrador senior |
795 |
45 |
35.775 |
|
Administrador junior |
278 |
20 |
5.560 |
|
|
|||
|
Total |
54.825 |
||
Coste total del proyecto
El coste total del proyecto, despuķs de sumar el coste del hardware, software y mano de obra es de aproximadamente 259.615 Ć.
18.3. Mejoras y ampliaciones del sistema
Este proyecto nos ha permitido construir un cluster completo que cumple todos los objetivos que nos planteamos. Ahora bien, siempre es posible mejorar la calidad del servicio mediante combinaciones de software y hardware que, por diversos motivos (tiempo, dinero,ģ) Āno se han podido utilizar en el momento de la implementaci¾n.
El nuevo cluster es un sistema complejo, formado por la combinaci¾n de distintos componentes cuya configuraci¾n puede afinarse para cambiar su comportamiento o mejorar su rendimiento bajo determinadas circunstancias.
A continuaci¾n comentaremos algunas mejoras que se han dejado en el tintero y que esperamos incluir en futuras actualizaciones del sistema.
18.3.1. Infraestructura de red
El hardware que sustenta la red del cluster es el hardware heredado de los tres clusters antiguos. Se trata de:
Ę
1 switch 3Com gigabit de 48 puertos
Ę
2 switch 3Com gigabit de 16 puertos
En el momento de la puesta en marcha del cluster, contamos con 50 mßquinas, lo que sobrepasa la capacidad del switch de 48 puertos. Esto nos obliga a conectar uno de los switches de 16 bocas a uno de sus puertos.
La merma de rendimiento de red en las dos mßquinas conectadas actualmente al switch peque±o y, lo que es mßs importante, de futuros nodos que se incorporen al cluster, es un tema a tener muy en cuenta.
Recientemente el Laboratorio de Cßlculo de LSI ha adquirido un par de switches Cisco C37506-48TS-S apliables de 48 bocas. El stacking entre ambos switches se realiza mediante una conexi¾n dedicada de 36 Gigabits.
Gracias a los nuevos switches el cluster puede crecer en efectivos sin que el rendimiento de red se vea afectado. La sustituci¾n de los switches viejos por los nuevos estß prevista para el primer trimestre de 2009.
18.3.2. IP bonding
Durante la fase de pruebas de los filesystems paralelos nos percatamos de que el ancho de banda de red acaba siendo un factor limitante a poco que crezca el n·mero de nodos de almacenamiento. En estos filesystems las lecturas y escrituras se hacen en paralelo en varios vol·menes al mismo tiempo, aportando una mejora sustancial de rendimiento si lo comparamos con el acceso a un sistema de almacenamiento ·nico.
La tecnologĒa gigabit ethernet proporciona un ancho de banda te¾rico deĀ 125 MBytes/s. En nuestra configuraci¾n actual los datos se obtienen de tres grupos de servidores de disco, cada uno de los cuales cuenta con dos discos SATA en configuraci¾n RAID0. Cada uno de estos nodos puede ofrecer datos a una velocidad de mßs de 100 MBytes/s, con lo que la suma de tres subsistemas sirviendo datos supera con creces el ancho de banda de la red.
Link aggregation o IEEE 802.3ad es una tecnologĒa de red que permite incrementar la velocidad de una conexi¾n ethernet agregando el ancho de banda de varias conexiones fĒsicas.
En la prßctica podrĒamos utilizar esta tecnologĒa para que las mßquinas servidoras de disco sirviesen disco a una mayor velocidad. Todas las mßquinas del cluster cuentan con varias tarjetas de red, 2 en el caso de los servidores de disco, que utilizadas conjuntamente podrĒan ofrecer un ancho de banda te¾rico de 250 MBytes/s.
Durante la
fase final de las pruebas del filesystem paralelo probamos esta configuraci¾n,
pero no obtuvimos los resultados esperados, limitados por
Cuando tuvimos que replantear la arquitectura del cluster en el apartado [9.5], viendo que era imposible aprovechar el espacio de disco de todas las mßquinas, nos vimos obligados a utilizar nodos dedicados a servir disco. Dado que no disponĒamos de mßquinas nuevas, utilizamos a tal efecto mßquinas viejas que iban a retirarse. Se trata de mßquinas con unos 5 a±os de antig³edad, con CPUs muy poco potentes para los cßnones actuales pero que cumplen correctamente el cometido como servidoras de disco.
La
configuraci¾n de las dos tarjetas de red de estas mßquinas en modo link
aggregation, produjo un overhead de
cßlculo que lleg¾ a saturar
Por ello aparcamos la idea de utilizar link aggregation hasta que dispongamos de mßquinas servidoras de disco con CPUs mßs potentes.
18.3.3. Sistema de almacenamiento
El ķxito de nuestra implementaci¾n del filesystem estß fuera de toda duda. La zona compartida nos ha permitido:
Ę
Aumentar el espacio disponible en caliente.
Ę
Eliminar el problema con la fragmentaci¾n de zonas.
Ę
Un mayor rendimiento.
Ę
Alta disponiblidad de datos.
Ę
Sistema altamente escalable.
Recordemos que los elementos que componen la zona de disco compartida son mßquinas corrientes con discos convencionales. La configuraci¾n actual funciona correctamente, y los beneficios respecto al modelo original son mßs que evidentes, pero es posible dar un salto de calidad hacia una configuraci¾n mßs profesional.
En este sentido, la utilizaci¾n de hardware especĒfico como un SAN nos permitirĒa alcanzar cotas mayores de rendimiento, fiabilidad (tolerancia a fallos) y escalabilidad, eso sĒ, a cambio de un precio que de momento, no podemos asumir.
El esquema mostrado en la figura [18.1] muestra una posible futura implementaci¾n de nuestro cluster utilizando un SAN. Esta configuraci¾n necesita del siguiente hardware extra:
Ę
Un SAN, como el Dell
PowerVault MD3000.
Ę
Dos servidores de disco dedicados con controladoras SAS
duales
El array de discos Dell PowerVault MD3000 dispone de espacio para hasta 45 discos SAS o SATA de hasta 1 TByte. Asimismo dispone de dos controladoras SAS duales que permiten configuraci¾n en modo tolerancia de fallos.
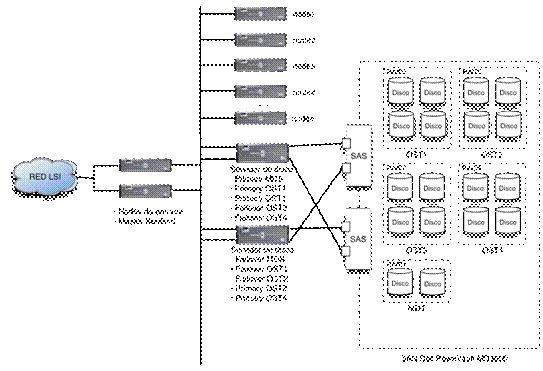
Figura 18.1: Esquema del cluster con SAN y Lustre
Los servidores de disco disponen de una controladora SAS dual, lo que les permite conectarse a cada una de las dos controladoras del array de discos.
Una posible organizaci¾n interna del array de discos, que optimiza el uso de Lustre como filesystem podrĒa ser la siguiente:
Ę
4 OSTS formados por 4 discos en configuraci¾n RAID5, lo que
da un espacio de almacenamiento efectivo de 3 TBytes por OST.
Ę
1 MDT formado por dos discos de 1 TByte en RAID1 (mirror).
Ę
El espacio total del filesystem es de 4 OST x 3 TBytes = 12
TBytes
Cada servidor de discos es primary de dos OSTs y failover de otros dos. Esta configuraci¾n conocida como primary/primary permite, gracias a las conexionesĀ SAS redundantes, soportar la caĒda de uno de los dos servidores sin pķrdida del servicio.
El rendimiento del sistema estß asegurado gracias a:
Ę
La velocidad de cada uno de los discos del array: hasta SAS
15K rpm.
Ę
La agrupaci¾n de discos en RAID5.
Ę
Con 4 OSTs se puede considerar hacer strip de 3 OSTs, por lo
que cada lectura/escritura se harĒa en 3 grupos de discos simultßneamente.
Ę
La velocidad de conexi¾n entre el array y los servidores de
disco: conexi¾n SAS de 3 Gb/s en cada servidor de disco, lo que da un
throughput mßximo de 6 Gb/s.
Ę
La conexi¾n de los servidores
a la red interna del cluster utilizando link aggregattion de 2 conexiones
gigabit ethernet, lo que permite a cada servidor de disco servir datos a una
velocidad mßxima de 2 Gb/s. Dados que los datos se obtienen de los dos
servidores a la vez, la tasa mßxima de datos servida podrĒa llegar a los 4 Gb/s
(500 MBytes/s).Ā
18.3.4. Tunning de Sun Grid
Sun Grid Engine es un sistema de colas que permite unos niveles de personalizaci¾n altĒsimos. Nuestra configuraci¾n actual debe verse como una adaptaci¾n del modelo original con tres clusters independientes.
El nuevo
cluster cuenta con tres colas, cuyo hardware y los usuarios que trabajan sobre
ellas se corresponden con los tres clusters originales. La unidad de asignaci¾n
de recursos o slots en los nodos de
computaci¾n es
La asignaci¾n 1 trabajo - 1 CPU puede no ser la mßs ¾ptima (de hecho, en muchos casos no lo serß), ya que un nodo con tantos procesos en ejecuci¾n como slots disponibles no aceptarß mßs trabajos independientemente del uso que se estķ haciendo de sus recursos (CPU y memoria).
Una polĒtica
mßs acertada podrĒa ser establecer el umbral de carga de las colas por el uso
real de
Como sistema vivo que es, el cluster cambiarß o no en funci¾n de las necesidades de los usuarios. Gracias a la flexibilidad que nos brinda Sun Grid estos cambios son posibles con un mĒnimo impacto.
18.3.5. Checkpointing (transparente) de procesos
Sun Grid prevķ la posibilidad de utilizar distintos tipos de librerĒas de checkpointing. Estas librerĒas permiten guardar en disco el estado de un proceso en ejecuci¾n para por ejemplo, mover un proceso de un nodo a otro o para continuar la ejecuci¾n de un proceso queĀ acab¾ su ejecuci¾n de forma inesperada por un fallo hardware.
Hay que destacar que Sun Grid no proporciona ning·n mecanismo de checkpointing, sino un interfaz para la utilizaci¾n de sistemas de terceros.
Durante el desarrollo de este proyecto tuvimos la ocasi¾n de probar algunas soluciones de checkpointing "transparente" como BLCR (Berkeley LabCheckpoint/Restart). Encontramos que las limitaciones eran demasiado importantes como para incluirlos en un sistema en producci¾n como el nuestro, donde el tipo de procesos es de lo mßs variado, desde scripts en perl hasta programas comerciales como Matlab.
Concretamente encontramos problemas al hacer checkpoint de procesos que hacen uso de file descriptors o pipes, algo bßsico para los procesos que se suelen ejecutar en el cluster.
Por otra parte, los usuarios del cluster que ejecutan procesos de larga duraci¾n (meses) ya implementan mecanismos de checkpoint que les permiten perder el mĒnimo tiempo de proceso en caso de fallo. Por otra parte, el scheduling actual del sistema de colas independientes no prevķ la posibilidad de reubicar procesos, lo cual serĒa de utilidad en caso de disponer de un sistema jerßrquico de colas.
18.3.6. Nuevos nodos
La potencia de cßlculo del cluster es el sumatorio de la potencia de cßlculo de los elementos que lo componen, por lo que la compra de nuevos nodos contribuye de forma inmediata a incrementar el throughput del cluster.
El Laboratorio de Cßlculo de LSI cuenta con 4 racks[15] para mßquinas del cluster. Cada uno de estos racks dispone de 24 conexiones elķctricas y de red, lo que nos permitirĒa llegar a tener hasta 96 nodos.
Dado que el espacio es finito intentaremos, en la medida de lo posible, sustituir nodos con mßs de 4 a±os de antig³edad, por los nodos nuevos.
19. Apķndices
19.1. Ficheros de configuraci¾n y scripts
19.1.1.
Fichero menu.lst
defaultĀĀĀĀĀĀĀĀ 0
timeoutĀĀĀĀĀĀĀĀ 5
titleĀĀĀĀĀĀĀĀĀĀ Lustre-kernel, kernel
rootĀĀĀĀĀĀĀĀĀĀĀ (hd0,0)
kernelĀĀĀĀĀĀĀĀĀ /boot/vmlinuz-2.6.18-1.6.5.1 root=/dev/md0
ro
initrdĀĀĀĀĀĀĀĀĀ /boot/initrd.img-2.6.18-1.6.5.1
19.1.2.
Fichero drbd.conf
global {
ĀĀĀ usage-count yes;
}
common {
Ā syncer {
ĀĀĀ rate 125M;
ĀĀĀ al-extents 1024;
Ā }
Ā protocol C;
}
resource r0 {
Ā startup {
ĀĀĀ wfc-timeout 30;
Ā }
Ā disk {
ĀĀĀĀ on-io-error detach;
Ā }
Ā net {
Ā }
Ā on node1 {
ĀĀĀ deviceĀĀĀĀ
/dev/drbd0;
ĀĀĀ diskĀĀĀĀĀĀ
/dev/md2;
ĀĀĀ addressĀĀĀ
10.1.1.1:7790;
ĀĀĀ meta-disk internal;
Ā }
Ā on node2 {
ĀĀĀ deviceĀĀĀ
/dev/drbd0;
ĀĀĀ diskĀĀĀĀĀ
/dev/md2;
ĀĀĀ addressĀĀ
10.1.1.2:7790;
ĀĀĀ meta-disk internal;
Ā }
}
19.1.3.
Fichero glusterfs-server.vol
volume brick
Ā ĀĀĀ type
storage/posix
ĀĀĀ Ā option
directory /mnt/glusterfs/home
end-volume
volume
posix-locks
ĀĀĀĀ type
features/posix-locks
ĀĀĀ Ā option
mandatory on
ĀĀĀ Ā subvolumes
brick
end-volume
volume
iothreads
ĀĀ ĀĀ type
performance/io-threads
ĀĀĀ Ā option
thread-count 2
ĀĀĀ Ā option
cache-size 64MB
ĀĀĀĀ subvolumes
posix-locks
end-volume
volume wb
ĀĀĀĀĀ type
performance/write-behind
subvolumes iothreads
end-volume
volume ra
ĀĀĀĀĀ type
performance/read-ahead
ĀĀĀĀĀ subvolumes
wb
end-volume
volume server
ĀĀĀĀĀ type
protocol/server
ĀĀĀĀ subvolumes
ra
ĀĀĀĀ option
transport-type tcp/server
ĀĀĀĀ option
auth.ip.ra.allow *
end-volume
19.1.4.
Fichero glusterfs-client.vol
volume
client0-ns
Ātype protocol/client
Āoption transport-type tcp/client
Āoption remote-host 192.168.0.201
Āoption remote-subvolume brick-ns
Āoption transport-timeout 180
end-volume
volume
client1-ns
type protocol/client
option transport-type tcp/client
ĀĀĀĀĀ option
remote-host 192.168.0.202
ĀĀĀĀĀ option
remote-subvolume brick-ns
ĀĀĀĀĀ option
transport-timeout 180
end-volume
#### CLIENTES
####
volume client1
type protocol/client
Ā ĀĀĀ option
transport-type tcp/client
Ā ĀĀĀ option
remote-host 192.168.0.101
Ā ĀĀĀ option
remote-subvolume ra
Ā ĀĀĀ option
transport-timeout 180
end-volume
volume client2
Ā ĀĀĀ type
protocol/client
Ā ĀĀĀ option
transport-type tcp/client
Ā ĀĀĀ option
remote-host 192.168.0.102
Ā ĀĀĀ option
remote-subvolume ra
Ā ĀĀĀ option
transport-timeout 180
end-volume
volume client3
type protocol/client
option transport-type tcp/client
option remote-host 192.168.0.103
Ā ĀĀĀ option
remote-subvolume ra
Ā ĀĀĀ option
transport-timeout 180
end-volume
volume client4
Ā ĀĀĀ type
protocol/client
Ā ĀĀĀ option
transport-type tcp/client
Ā ĀĀĀ option
remote-host 192.168.0.104
Ā ĀĀĀ option
remote-subvolume ra
Ā ĀĀĀ option
transport-timeout 180
end-volume
volume client5
Ā ĀĀĀ type
protocol/client
Ā ĀĀĀ option
transport-type tcp/client
Ā ĀĀĀ option
remote-host 192.168.0.105
Ā ĀĀĀ option
remote-subvolume ra
Ā ĀĀĀ option
transport-timeout 180
end-volume
volume client6
Ā ĀĀĀ type
protocol/client
Ā ĀĀĀ option
transport-type tcp/client
Ā ĀĀĀ option
remote-host 192.168.0.106
Ā ĀĀĀ option
remote-subvolume ra
Ā ĀĀĀ option
transport-timeout 180
end-volume
volume afr-ns
Ā ĀĀĀ type
cluster/afr
Ā ĀĀĀ subvolumes
client0-ns client1-ns
end-volume
volume afr1
Ā ĀĀĀ type
cluster/afr
Ā ĀĀĀ subvolumes
client1 client2
end-volume
volume afr2
Ā ĀĀĀ type
cluster/afr
Ā ĀĀĀ subvolumes
client3 client4
end-volume
volume afr3
Ā ĀĀĀ type
cluster/afr
Ā ĀĀĀ subvolumes
client5 client6
end-volume
volume unify
Ā ĀĀĀ type
cluster/unify
Ā ĀĀĀ subvolumes
afr1 afr2 afr3
Ā ĀĀĀ option
scheduler rr
Ā ĀĀĀ option
rr.limits.min-free-disk 1%
Ā ĀĀĀ option
readdir-force-success on
Ā ĀĀĀ option
namespace afr-ns
end-volume
volume wb
ĀĀĀĀĀ type
performance/write-behind
ĀĀĀ Ā option
aggregate-size 128KB
ĀĀ ĀĀ option
flush-behind on
ĀĀĀĀĀ subvolumes
unify
end-volume
19.1.5.
Fichero ha.cf de master-cluster1
debugfile /var/log/ha-debug
logfile /var/log/ha-log
logfacility
local0
auto_failback
on
ucast eth0
192.168.0.202
warntime 30
deadtime 120
initdead 180
keepalive 5
node
master-cluster1
node master-cluster2
19.1.6. Fichero ha.cf de master-cluster2
debugfile /var/log/ha-debug
logfile /var/log/ha-log
logfacility
local0
auto_failback
on
ucast eth0
192.168.0.201
warntime 30
deadtime 120
initdead 180
keepalive 5
node
master-cluster1
node
master-cluster2
19.1.7.
Fichero haresources
master-cluster1
Filesystem.drbd::/dev/drbd1::/mnt/sge/default/spool::ext3 sungrid MailTo::cluster@lsi.upc.edu
19.1.8.
Script sungrid de heartbeat
#!/bin/bash
#
ACT_QMASTER="/usr/local/sge/default/common/act_qmaster"
SGESCRIPT="/etc/init.d/sgemaster"
HOSTNAME=`uname
-n`
case
"$1" in
ĀĀĀ start)
ĀĀĀĀĀ SHARED_ZONES=`mount | grep -e drbd1 -e
drbd0 | wc -l`
ĀĀĀĀĀ #while [ $SHARED_ZONES != 2Ā && ! -f $ACT_QMASTER ]; do
ĀĀĀĀĀ while [ ! -f $ACT_QMASTER ]; do
ĀĀĀĀĀ ĀĀ echo "[LCLSI] Zonas lustre aun no montadas, esperamos 30\" m?s..."
ĀĀĀĀĀ ĀĀ sleep 30
ĀĀĀĀĀ ĀĀ
SHARED_ZONES=`mount | grep -e drbd1 -e drbd0 | wc -l`
ĀĀĀĀĀ done
ĀĀĀĀĀ ACT_QMASTER="/usr/local/sge/default/common/act_qmaster"
ĀĀĀĀĀ echo $HOSTNAME > $ACT_QMASTER
ĀĀĀĀĀ # try several times, in case heartbeat
deadtime
ĀĀĀĀĀ # was smaller than drbd ping time
ĀĀĀĀĀ try=6
ĀĀĀĀĀ while true; do
ĀĀĀĀ ĀĀĀĀĀĀ sleep
10
ĀĀĀĀĀĀĀĀĀĀĀ $SGESCRIPT start && break
ĀĀĀĀĀĀĀĀĀĀĀ let "--try" || exit 1 #
LSB generic error
ĀĀĀĀĀĀĀĀĀĀĀ sleep 1
ĀĀĀĀĀ done
ĀĀĀĀĀ ;;
ĀĀĀ stop)
ĀĀĀĀĀ $SGESCRIPT stop
ĀĀĀĀĀ #ex=$?
ĀĀĀĀĀ ;;
ĀĀĀ status)
ĀĀĀĀĀ #Status: Si hostname = act_qmaster =>
master
ĀĀĀĀĀ #ĀĀĀĀ
Si hostname <> act_qmaster => shadow
ĀĀĀĀĀĀĀ HOSTNAME=`uname -n`
ĀĀĀĀĀ if [ -f $ACT_QMASTER ]; then
ĀĀĀĀĀ ĀĀ
QMASTER_ACTUAL=`cat /usr/local/sge/default/common/act_qmaster`
ĀĀ ĀĀĀĀĀĀĀĀif [ $HOSTNAME == $QMASTER_ACTUAL ];
then
ĀĀĀĀĀĀĀĀĀĀĀĀĀ STATE=Master
ĀĀĀĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀĀĀĀ STATE=Shadow
ĀĀĀĀĀĀĀĀĀĀ fi
ĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀ STATE=Unconfigured
ĀĀĀĀĀĀĀ fi
ĀĀĀĀĀ case $STATE in
ĀĀĀĀĀĀĀĀĀĀĀ Master)
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ MASTER_RUNNING=`ps waux|grep
sge_qmaster|grep -v grep|wc -l`
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ if [ $MASTER_RUNNING == 1 ];
then
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ĀĀ echo "running (Primary)"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ĀĀ exit 0 # LSB status "service is
OK"
ĀĀĀĀĀĀĀĀĀĀĀ ĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ĀĀ echo "stopped (Primary)"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ fiĀĀĀ
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ;;
ĀĀĀĀĀĀĀĀĀĀĀ Shadow|Unconfigured)
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "stopped
($STATE)" ;;
ĀĀĀĀĀĀĀĀĀĀĀ "")
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "stopped" ;;
ĀĀĀĀĀĀĀĀĀĀĀ *)
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # unexpected. whatever...
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "stopped ($ST)"
;;
ĀĀĀĀĀ esac
ĀĀĀĀĀ exit 3 # LSB status "service is not
running"
ĀĀĀĀĀ ;;
ĀĀĀ *)
ĀĀĀĀĀ echo "Usage: sungrid
{start|stop|status}"
ĀĀĀĀĀ exit 1
ĀĀĀĀĀ ;;
esac
exit 0
19.1.9. Fichero drbd.conf de zona spool
global {
ĀĀĀ usage-count yes;
}
common {
Ā syncer {
ĀĀĀ rate 125M;
ĀĀĀ al-extents 1024;
Ā }
Ā protocol C;
}
resource r1 {
Ā startup {
ĀĀĀ wfc-timeout 30;
Ā }
Ā disk {
ĀĀĀĀ on-io-error detach;
Ā }
Ā net {
Ā }
Ā on master-cluster1 {
ĀĀĀ deviceĀĀĀĀ
/dev/drbd1;
ĀĀĀ diskĀĀĀĀĀĀ
/dev/md3;
ĀĀĀ addressĀĀĀ
10.1.1.1:7790;
ĀĀĀ meta-disk internal;
Ā }
Ā on master-cluster2 {
ĀĀĀ deviceĀĀĀ
/dev/drbd1;
ĀĀĀ diskĀĀĀĀĀ
/dev/md3;
ĀĀĀ addressĀĀ
10.1.1.2:7790;
ĀĀĀ meta-disk internal;
Ā }
}
19.1.10. Fichero glusterfs-server_sge-common.vol
volume
brick-sge
ĀĀĀ Ā type
storage/posix
ĀĀĀĀ option
directory /mnt/glusterfs/sge-common
end-volume
volume server
ĀĀ ĀĀ type
protocol/server
ĀĀĀ Ā subvolumes
brick-sge
ĀĀĀĀ option
transport-type tcp/server
ĀĀĀĀ option
auth.ip.brick-sge.allow *
end-volume
19.1.11. Fichero glusterfs-client-sge.vol
volume
client1-sge
ĀĀĀĀĀ type
protocol/client
ĀĀĀĀĀ option
transport-type tcp/client
ĀĀĀĀĀ option
remote-host 192.168.0.201
ĀĀĀĀĀ option
remote-subvolume brick-sge
ĀĀĀĀĀ option
transport-timeout 180
end-volume
volume
client2-sge
type protocol/client
ĀĀĀĀĀ option
transport-type tcp/client
ĀĀĀĀĀ option
remote-host 192.168.0.202
ĀĀĀĀĀ option
remote-subvolume brick-sge
ĀĀĀĀĀ option
transport-timeout 180
end-volume
volume afr
Ā ĀĀĀ type
cluster/afr
Ā ĀĀĀ subvolumes
client1-sge client2-sge
end-volume
19.1.2.
Fichero bootnode-gluster.shtml
<script
type="text/rembo-c">
ShowConsole();
int NumDisks =
sizeof(SystemInfo.Disks);
// Devuelve el id del disco de menor tama±o
int
GetSmallerDisk (void) {
Ā int SmallerDiskSize = SystemInfo.Disks[0];
Ā int SmallerDisk = 0;
Ā for (int i=1;i<NumDisks;i++) {
ĀĀĀĀ if (SystemInfo.Disks[i] <
SmallerDiskSize) {
ĀĀĀĀĀĀ SmallerDisk = i;
ĀĀĀĀ }
Ā }
Ā Log(Strf("DISCO DE MENOR TAMAčO:
%u<br><br>",SmallerDisk));
Ā return SmallerDisk;
}
// Trabajamos con el disco de menor tama±o
int MaxDisks =
2;
int IdDisk =
GetSmallerDisk();
int DiskSize =
SystemInfo.Disks[IdDisk];
int RootSize =
20000000;
int SwapSize =
4000000;
int HomeSize =
(DiskSize - RootSize - SwapSize-50000);
int
NumPartitions = 0;
str Partitions
= Strf("EXT2:%u LINUX-SWAP:%u 253:%u", RootSize, SwapSize, HomeSize);
str p =
GetPrimaryPartitions(IdDisk);
var pa =
ParsePartitions(p);
int min (int
num1, int num2) {
Ā if (num1 < num2)
ĀĀĀĀ return num1;
Ā else return num2;
}
// Devuelve TRUE si Disco Inicializado
bool
DiscoInicializado (int IdDisk) {
Ā str p = GetPrimaryPartitions(IdDisk);
Ā var pa = ParsePartitions(p);
Ā int NumPartitions = sizeof(pa);
Ā if (NumPartitions < 4)
ĀĀĀĀ return false;
Ā else
ĀĀĀĀ if (StrCompare(pa[3].type,"240")
== 0)
ĀĀĀĀĀĀĀ return true;
ĀĀĀĀ else
ĀĀĀĀĀĀĀ return false;
}
// Comrprobar que tamaŲo(disco_no_inicializado)>= tamaŲo(disco_inicializado)
if (NumDisks >1) {
Ā // 2 o mas discos
Ā if (DiscoInicializado(0) && !DiscoInicializado(1)) {
ĀĀĀĀĀ if (SystemInfo.Disks[1] <
SystemInfo.Disks[0]) {
ĀĀĀĀ ĀĀĀĀLog(Strf("ERROR: Disco sin inicializar (1) es de menor tama±o
que el ya inicializado. <br>"));
ĀĀĀĀĀĀĀĀ exit (1);
ĀĀĀĀĀ }
Ā else {
ĀĀĀĀ if (!DiscoInicializado(0) &&
DiscoInicializado(1)) {
ĀĀĀĀĀ if (SystemInfo.Disks[0] <
SystemInfo.Disks[1]) {
ĀĀĀĀĀĀĀ ĀLog(Strf("ERROR: Disco sin inicializar (0) es de menor tama±o que el ya inicializado. <br>"));
ĀĀĀĀĀĀĀĀ exit (1);
ĀĀĀĀĀĀ }
ĀĀĀĀ }
Ā }
}
}
//Particionamos los discos no particionados (sin MARCA)
for (int i=0;i<min(NumDisks,MaxDisks);i++) {
Ā if (!DiscoInicializado(i)){
ĀĀĀĀ Log(Strf("Inicializando disco %u. Tabla de particiones:<br>",i));
ĀĀĀĀ SetPrimaryPartitions(i,Partitions);
ĀĀĀĀ Log(GetPrimaryPartitions(i) +
"<br>");
Ā }
}
Ā SetBootablePartition(0,1);
Log(Strf("Restauramos
imagen...<br>"));
RestoreDiskImage(0,1,"net://global/hdimages/node_gluster_v3.img");
HDClean(0,2);
LXBoot("net://global/hdimages/vmlinuz-
</script>
19.1.13. Script post_boot.sh
#!/bin/bash
# Decidimos quķ
host es master
masters="master-cluster1
master-cluster2"
for node in
`echo $masters`; do
ĀĀ if [ "`ping -c 3 -W 1 -i 1 $node | grep
"bytes from" | wc -l`" -ne 0 ]; then
ĀĀĀĀĀ NodoMaster=$node
ĀĀĀĀĀ break
ĀĀ fi
done
echo
"[LCLSI] Nodo Master: $NodoMaster"
echo
""
SrcFiles=/root/files/nodes
GlusterPath=/
GlusterDaemon=$GlusterPath/sbin/glusterfs
GlusterClientCfg=$GlusterPath/etc/glusterfs/glusterfs-client.vol
GlusterClientSgeCfg=$GlusterPath/etc/glusterfs/glusterfs-client-sge.vol
GlusterServerCfg=$GlusterPath/etc/glusterfs/glusterfs-server.vol
# Sincronizamos hora
/usr/sbin/rdate -s $NodoMaster
# Damos nombre al nodo
scp
$NodoMaster:/etc/hosts /etc/hosts
Ip=`ifconfig
eth0|grep inet|awk '{print $2}'|cut -f2 -d:`
Nombre=`grep -w
$Ip /etc/hosts |awk '{print $2}'`
# Damos nombre segun @IP asignada
echo $Nombre > /etc/hostname
hostname $Nombre
# Restauramos usuarios
/usr/bin/scp $NodoMaster:/etc/passwd.nodes /etc/passwd
/usr/bin/scp $NodoMaster:/etc/shadow /etc/shadow
chmod 640 /etc/shadow
/usr/bin/scp
$NodoMaster:/etc/group /etc/group
# Copiamos Configuracion GlusterFS
/usr/bin/scp $NodoMaster:$SrcFiles/glusterfs-client.vol /etc/glusterfs/
/usr/bin/scp
$NodoMaster:$SrcFiles/glusterfs-server.vol /etc/glusterfs/
/usr/bin/scp
$NodoMaster:$SrcFiles/glusterfs-client-sge.vol /etc/glusterfs/
# Copiamos fstab
/usr/bin/scp $NodoMaster:$SrcFiles/fstab /etc/
# Copiamos listado de nodos
/usr/bin/scp $NodoMaster:$SrcFiles/nodes /etc/
# Copiamos ficheros de configuracion de heartbeat
/usr/bin/scp
$NodoMaster:$SrcFiles/ha.cf /etc/ha.d/
/usr/bin/scp
$NodoMaster:$SrcFiles/haresources /etc/ha.d/
# Copiamos ficheros de configuracion de GANGLIA
/usr/bin/scp $NodoMaster:$SrcFiles/gmetad.conf /etc/
/usr/bin/scp $NodoMaster:$SrcFiles/gmond.conf /etc/
# Detectar n·mero de discos (1 o 2)
ExisteSda=`cat
/proc/partitions | grep sda3|wc -l`
ExisteSdb=`cat
/proc/partitions | grep sdb3|wc -l`
# NumDiscosIni: numero de discos inicializados
NumDiscosIni=`fdisk -l /dev/sda /dev/sdb | grep PA-RISC | wc -l`
# Obtenemos datos del nodo
if [ `grep $Nombre /etc/nodes|wc -l` -eq 0 ]; then
ĀĀ echo "[LCLSI] ERROR. Nodo no encontrado en lista de nodos (/etc/nodes)"
ĀĀ echo "ĀĀĀĀĀĀĀ Comprobar alta en master-cluster"
ĀĀ exit 1
fi
HaNode=`grep -w ^$Nombre /etc/nodes|awk '{print $2}'`
RolNode=`grep -w ^$Nombre /etc/nodes|awk '{print $3}'`
PairNode=`grep -w ^$Nombre /etc/nodes|awk '{print $4}'`
echo
"HaNode: $HaNode, RolNode: $RolNode, PairNode: $PairNode"
echo "NumDiscosIni: $NumDiscosIni"
case $NumDiscosIni in
ĀĀ 0)
ĀĀĀĀĀĀĀ # Ning·n disco inicializado
ĀĀĀĀĀĀĀ echo "[LCLSI] Nodo nuevo"
ĀĀĀĀĀĀĀ if [ $ExisteSda -eq 1 ] && [ $ExisteSdb -eq 1 ]; then
ĀĀĀĀĀĀĀĀĀĀ # Hay dos discos no inicializados
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Nodo con discos sda y sdb no inicializados"
ĀĀĀĀĀĀĀĀĀĀ if [ $HaNode == "NO" ]; then
ĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Nodo $Nombre es CLIENTE glusterfs"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ echo ""
ĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Montamos /home (zona glusterfs)"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ
echo
"$GlusterDaemon -f $GlusterClientCfg /home"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ $GlusterDaemon -f $GlusterClientCfg /home
ĀĀĀĀĀĀĀĀĀĀĀĀĀ # Formateamos y montamos zona TMP
ĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Formateamos y montamos zona TMP"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ
TmpRaid=`cat
/proc/mdstat|grep md2|wc -l`
ĀĀĀĀĀĀĀĀĀĀĀĀĀ if [ $TmpRaid -eq 0 ]; then
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
TmpDevice="/dev/sda3"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ TmpDevice="/dev/md2"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ fi
ĀĀĀĀĀĀĀĀĀĀĀĀĀ /sbin/mke2fs -j $TmpDevice
ĀĀĀĀĀĀĀĀĀĀĀĀĀ /bin/mount $TmpDevice /tmp
ĀĀĀĀĀĀĀĀĀĀĀĀĀ /bin/chmod 777 /tmp
ĀĀĀĀĀĀĀĀĀĀĀĀĀ /bin/chmod a+t /tmp
ĀĀĀĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀĀĀĀ # El Nodo tiene una pareja OST/DRBD
ĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Nodo $Nombre es SERVIDOR glusterfs"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ
echo
"[LCLSI] Creamos array HOME"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ mdadm --create /dev/md2 -R
--level=0 --raid-devices=2 /dev/sda3 /dev/sdb3
ĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] INFO: Nodo $Nombre forma un AFR con $PairNode"
ĀĀĀĀĀĀĀĀĀĀĀĀ # Marcamos discos como inicializados
ĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Marcamos discos como inicializados"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ
PrimerByteLibre=`/sbin/parted
/dev/sdb unit b print free|grep "Free Space"|awk '{print $1}'|cut -f1
-dB`
ĀĀĀĀĀĀĀĀĀĀĀĀĀ SegundoByteLibre=`expr
$PrimerByteLibre + 1`
ĀĀĀĀĀĀĀĀĀĀĀĀĀ /sbin/parted /dev/sda unit b
mkpart primary ext2 $PrimerByteLibre $SegundoByteLibre set 4 palo on
ĀĀĀĀĀĀĀĀĀĀĀĀĀ /sbin/parted /dev/sdb unit b
mkpart primary ext2 $PrimerByteLibre $SegundoByteLibre set 4 palo on
ĀĀĀĀĀĀĀĀĀĀĀĀĀ sleep 5
ĀĀĀĀĀĀĀĀĀĀĀĀĀ # Formateamos zona gluster
ĀĀĀĀĀĀĀĀĀĀĀĀĀ /sbin/mke2fs -j /dev/md2
ĀĀĀĀĀĀĀĀĀĀĀĀĀ # Montamos zona gluster (server)
ĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Montamos zona gluster"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ
mount -t ext3
/dev/md2 /mnt/glusterfs/home
ĀĀĀĀĀĀĀĀĀĀĀĀĀ # Lanzamos Daemon gluster
ĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Lanzamos Daemon gluster"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ
$GlusterDaemon
-f $GlusterServerCfg
ĀĀĀĀĀĀĀĀ fi
ĀĀĀĀĀĀĀ elif [ $ExisteSda -eq 1 ] && [
$ExisteSdb -eq 0 ]; then
ĀĀĀĀĀĀĀĀĀĀ # Nodo con un disco (sda)
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Nodo con un solo disco (sda). NO lo incializamos"
ĀĀĀĀĀĀĀĀĀĀ echo ""
ĀĀĀĀĀĀĀĀĀĀ # Formateamos y montamos zona TMP
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Formateamos y montamos zona TMP"
ĀĀĀĀĀĀĀĀĀĀ
TmpRaid=`cat
/proc/mdstat|grep md2|wc -l`
ĀĀĀĀĀĀĀĀĀĀ if [ $TmpRaid -eq 0 ]; then
ĀĀĀĀĀĀĀĀĀĀĀĀĀ TmpDevice="/dev/sda3"
ĀĀĀĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀĀĀĀ TmpDevice="/dev/md2"
ĀĀĀĀĀĀĀĀĀĀ fi
ĀĀĀĀĀĀĀĀĀĀ /sbin/mke2fs -j $TmpDevice
ĀĀĀĀĀĀĀĀĀĀ /bin/mount $TmpDevice /tmp
ĀĀ ĀĀĀĀĀĀĀĀ/bin/chmod 777 /tmp
ĀĀĀĀĀĀĀ /bin/chmod a+t /tmp
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Montamos zona common (sge)"
ĀĀĀĀĀĀĀĀĀĀ
$GlusterDaemon
-f $GlusterClientSgeCfg /mnt/sge/default/common
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Montamos /home (zona glusterfs)"
ĀĀĀĀĀĀĀĀĀĀ
echo
"$GlusterDaemon -f $GlusterClientCfg /home"
ĀĀĀĀĀĀĀĀĀĀ $GlusterDaemon -f $GlusterClientCfg
/home
ĀĀĀĀĀĀĀ elif [ $ExisteSda -eq 0 ] && [
$ExisteSdb -eq 1 ]; then
ĀĀĀĀĀĀĀ # Nodo con un disco (sdb) ---> RARO...
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Nodo con un solo disco (sdb). NO lo incializamos"
ĀĀĀĀĀĀĀĀĀĀ echo ""
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Montamos zona common (sge)"
ĀĀĀĀĀĀĀĀĀĀ
$GlusterDaemon
-f $GlusterClientSgeCfg /mnt/sge/default/common
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Montamos /home (zona glusterfs)"
ĀĀĀĀĀĀĀĀĀĀ
$GlusterDaemon
-f $GlusterClientCfg /home
ĀĀĀĀĀĀĀ elif [ $ExisteSda -eq 0 ] && [
$ExisteSdb -eq 0 ]; then
ĀĀĀĀĀĀĀĀĀĀ # No existe ningun disco. ERROR: discos mal particionados por REMBO
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] ERROR: No se han detectado discos con particionamiento correcto"
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Verificar REMBO"
ĀĀĀĀĀĀĀĀĀĀ exit 1
ĀĀĀĀĀĀĀ fi
ĀĀĀĀĀĀĀ # Enviamos mail
ĀĀĀĀĀĀĀ echo ""|mail -s "[CLUSTER] Alta de nodo $Nombre" cluster@lsi.upc.edu
ĀĀĀĀĀĀĀ ;;
ĀĀ 2)
ĀĀĀĀĀĀĀ # Dos discos inicializados
ĀĀĀĀĀĀĀ echo "[LCLSI] Detectado sistema con dos discos ya inicializados"
ĀĀĀĀĀĀĀ
if [
"$HaNode" == "NO" ]; then
ĀĀĀĀĀĀĀĀĀĀ echo ""
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Nodo $Nombre es CLIENTE glusterfs"
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Montamos zona common (sge)"
ĀĀĀĀĀĀĀĀĀĀ
$GlusterDaemon
-f $GlusterClientSgeCfg /mnt/sge/default/common
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Montamos /home (zona glusterfs)"
ĀĀĀĀĀĀĀĀĀĀ $GlusterDaemon -f $GlusterClientCfg /home
ĀĀĀĀĀĀĀĀĀĀ # Formateamos y montamos zona TMP
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Formateamos y montamos zona TMP"
ĀĀĀĀĀĀĀĀĀĀ
/sbin/mke2fs -j
/dev/sda3
ĀĀĀĀĀĀĀĀĀĀ /bin/mount /dev/sda3 /tmp
ĀĀĀĀĀĀĀĀĀĀ /bin/chmod 777 /tmp
ĀĀĀĀĀĀĀĀĀĀ /bin/chmod a+t /tmp
ĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Nodo $Nombre es SERVIDOR glusterfs"
ĀĀĀĀĀĀĀĀĀĀ # Montamos zona gluster (server)
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Montamos zona gluster"
ĀĀĀĀĀĀĀĀĀĀ
mount -t ext3
/dev/md2 /mnt/glusterfs/home
ĀĀĀĀĀĀĀĀĀĀ # Lanzamos Daemon gluster
ĀĀĀĀĀĀĀĀĀĀ echo "[LCLSI] Lanzamos Daemon gluster"
ĀĀĀĀĀĀĀĀĀĀ $GlusterDaemon -f $GlusterServerCfg
ĀĀĀĀĀĀĀ fi
ĀĀĀĀĀĀĀ ;;
ĀĀ *)Ā echo "ERROR: Numero de discos marcados > 2 ┐┐??"
ĀĀĀĀĀĀ echo "NumDiscosRemboIni: $NumDiscosRemboIni"
;;
esac
# copiamos crontab (root)
if [ $HaNode ==
"SI" ]; then
ĀĀ /usr/bin/scp $NodoMaster:$SrcFiles/crontab_root_storage
/tmp/.crontab_root
else
ĀĀ /usr/bin/scp
$NodoMaster:$SrcFiles/crontab_root /tmp/.crontab_root
fi
# Personalizaci¾n ficheros GANGLIA
HOSTNAME=`hostname`
MY_CLUSTER=`grep
-w ^$HOSTNAME /etc/nodes | awk '{print $5}'`
MY_MCAST_CHANNEL=`grep
-w ^$HOSTNAME /etc/nodes | awk '{print $6}'`
sed
s/"CLUSTER_NAME"/$MY_CLUSTER/ /etc/gmetad.conf > /tmp/.gmetad.conf
cp
/tmp/.gmetad.conf /etc/gmetad.conf
rm
/tmp/.gmetad.conf
sed
s/"CLUSTER_NAME"/$MY_CLUSTER/ /etc/gmond.conf > /tmp/.gmond.conf
sed
s/"MCAST_CHANNEL"/$MY_MCAST_CHANNEL/ /tmp/.gmond.conf >
/etc/gmond.conf
rm
/tmp/.gmond.conf
sed
s/"MCAST_CHANNEL"/$MY_MCAST_CHANNEL/ /tmp/.crontab_root >
/var/spool/cron/crontabs/root
rm /tmp/.crontab_root
# Todos los discos inicializados
if [ "$RolNode"
== "-" ]; then
# SunGrid
NUM_CORES=`grep
processor /proc/cpuinfo|wc -l`
export
SGE_ROOT=/usr/local/sge
SGE_MOUNT=`mount|grep
"/mnt/sge/default/common"|wc -l`
if ! [
$SGE_MOUNT -ne 1 ]; then
ĀĀ echo "[LCLSI] ERROR: Zona SGE no
accesible"
ĀĀ exit 1
fi
if ! [ -L
/usr/local/sge/default/common ]; then
ĀĀĀĀ ln -s /mnt/sge/default/common
/usr/local/sge/default/common
fi
if ! [ -d
/mnt/sge/default/spool/$HOSTNAME ]; then
ĀĀĀĀ mkdir /mnt/sge/default/spool/$HOSTNAME
fi
if ! [ -L
/usr/local/sge/default/spool/$HOSTNAME ]; then
ĀĀ ln -s /mnt/sge/default/spool/$HOSTNAME
/usr/local/sge/default/spool/$HOSTNAME
fi
if [
`$SGE_ROOT/bin/lx24-x86/qstat -f|grep $HOSTNAME|wc -l` -ne 0 ]; then
Ā echo "[LCLSI] $HOSTNAME pertenece a cluster SunGrid"
else
Ā echo "[LCLSI] $HOSTNAME no pertenece a cluster SunGrid"
Ā echo "[LCLSI] Lo a±adimos...."
Ā $SGE_ROOT/bin/lx24-x86/qconf -aattr
hostgroup hostlist $HOSTNAME @allhosts
Ā $SGE_ROOT/bin/lx24-x86/qconf -aattr hostgroup
hostlist $HOSTNAME @$MY_CLUSTER
Ā $SGE_ROOT/bin/lx24-x86/qconf -aattr queue
slots "[$HOSTNAME=$NUM_CORES]" all.q
Ā $SGE_ROOT/bin/lx24-x86/qconf -aattr queue
slots "[$HOSTNAME=$NUM_CORES]" $MY_CLUSTER
Ā $SGE_ROOT/bin/lx24-x86/qconf -aattr queue
slots "[$HOSTNAME=$NUM_CORES]" $MY_CLUSTER-nice
fi
sleep 5
/etc/init.d/sgeexecd
start
# Purgamos cola
DEAD_JOBS=`/usr/local/sge/bin/lx24-x86/qstat
-s r -f -u "*" -q '*'@$HOSTNAME | egrep -v -e all.q -e ^queue -e
^$MY_CLUSTER
-e ^- |awk '{print $1}'`
if [
"$DEAD_JOBS" != "" ]; then
ĀĀ for job in $DEAD_JOBS; do
ĀĀĀĀĀĀ OWNER=`/usr/local/sge/bin/lx24-x86/qstat
-j $job|grep ^owner|awk '{print $2}'`
ĀĀĀĀĀĀ echo "JOB $job con owner:
$OWNER"
ĀĀĀĀĀĀ echo "[LCLSI] Purgamos trabajo $job encolado en nodo"
ĀĀĀĀĀĀ # No queremos que se envie mail a usuarios reales.... de momento
ĀĀĀĀĀĀ OWNER=cluster@lsi.upc.edu
ĀĀĀĀĀĀ ssh $NodoMaster "/usr/local/sge/bin/lx24-x86/qdel $job;echo \"El trabajo con id $job ha terminado de forma inesperada por fallo en nodo $HOSTNAME\"|mail -s \"[LCLSI] Job $job ha muerto\" $OWNER@lsi.upc.edu"
ĀĀ done
else
ĀĀ echo "[LCLSI] No hay trabajos que purgar en nodo"
fi
fi
19.1.14. Fichero gmond.conf
# $Id: gmond.conf,v 1.3
# This is the
configuration file for the Ganglia Monitor Daemon (gmond)
# Documentation
can be found at http://ganglia.sourceforge.net/docs/
#
# To change a
value from it's default simply uncomment the line
# and alter the
value
#####################
#
# The name of
the cluster this node is a part of
# default:
"unspecified"
# nameĀ "Testing Cluster"
name
"Master nodes"
#
# The owner of
this cluster. Represents an administrative
# domain. The
pair name/owner should be unique for all clusters
# in the world.
# default:
"unspecified"
owner
"LCLSI"
#
# The latitude
and longitude GPS coordinates of this cluster on earth.
# Specified to
# DMS format:
"N61.18 W130.50".
# default:
"unspecified"
# latlong
"N32.87 W117.22"
#
# The URL for
more information on the Cluster. Intended to give purpose,
# owner,
administration, and account details for this cluster.
# default:
"unspecified"
# url
"http://www.mycluster.edu/"
#
# The location
of this host in the cluster. Given as a 3D coordinate:
#
"Rack,Rank,Plane" that corresponds to a Euclidean coordinate
"x,y,z".
# default:
"unspecified"
# location
"0,0,0"
#
# The multicast
channel for gmond to send/receive data on
# default: 239.
Āmcast_channel 239.
#
# The multicast
port for gmond to send/receive data on
# default: 8649
Āmcast_portĀĀĀ
8649
#
# The multicast
interface for gmond to send/receive data on
# default: the
kernel decides based on routing configuration
Āmcast_ifĀ
eth0
#
# The multicast
Time-To-Live (TTL) for outgoing messages
# default: 1
#
mcast_ttlĀ 1
#
#
# The number of
threads listening to multicast traffic
# default: 2
# mcast_threads
2
#
# Which port
should gmond listen for XML requests on
# default: 8649
# xml_portĀĀĀĀ 8649
#
# The number of
threads answering XML requests
# default: 2
#
xml_threadsĀĀ 2
#
# Hosts ASIDE
from "127.0.0.1"/localhost and those multicasting
# on the same
multicast channel which you will share your XML
# data
with.Ā Multiple hosts are allowed on
multiple lines.
# Can be
specified with either hostnames or IP addresses.
# default: none
# trusted_hosts
1.1.1.1 1.1.1.2 1.1.1.3 \
# 2.3.2.3
3.4.3.4 5.6.5.6
#
# The number of
nodes in your cluster.Ā This value is
used in the
# creation of
the cluster hash.
# default: 1024
#
num_nodesĀ 1024
#
# The number of
custom metrics this gmond will be storing.Ā
This
# value is used
in the creation of the host custom_metrics hash.
# default: 16
#
num_custom_metrics 16
#
# Run gmond in
"mute" mode.Ā Gmond will only
listen to the multicast
# channel but
will not send any data on the channel.
# default: off
# mute on
#
# Run gmond in
"deaf" mode.Ā Gmond will only
send data on the multicast
# channel but
will not listen/store any data from the channel.
# default: off
# deaf on
#
# Run gmond in
"debug" mode.Ā Gmond will not
background.Ā Debug messages
# are sent to
stdout.Ā Value from 0-100.Ā The higher the number the more
# detailed
debugging information will be sent.
# default: 0
# debug_level
10
#
# If you don't
want gmond to setuid, set this to "on"
# default: off
#
no_setuidĀ on
#
# Which user
should gmond run as?
# default:
nobody
setuidĀĀĀĀ ganglia
#
# If you do not
want this host to appear in the gexec host list, set
# this value to
"on"
# default: off
# no_gexecĀĀ on
#
# If you want
any host which connects to the gmond XML to receive
# data, then
set this value to "on"
# default: off
Āall_trusted on
#
# If you want
dead nodes to "time out", enter a nonzero value here. If specified,
# a host will
be removed from our state if we have not heard from it in this
# number of
seconds.
# default: 0
(immortal)
# host_dmax
108000
19.1.15. Fichero gmetad.conf
# This is an
example of a Ganglia Meta Daemon configuration file
#ĀĀ ĀĀĀĀĀĀĀĀĀĀĀĀĀhttp://ganglia.sourceforge.net/
#
# $Id:
gmetad.conf,v
#
#--------------------------------------------------------------------
# Setting the
debug_level to 1 will keep daemon in the forground and
# show only
error messages. Setting this value higher than 1 will
# make
# gmetad output
debugging information and stay in the foreground.
# default: 0
# debug_level
10
#
#--------------------------------------------------------------------
# What to
monitor. The most important section of this file.
#
# The
data_source tag specifies either a cluster or a grid to
# monitor. If
we detect the source is a cluster, we will maintain a
# complete
# set of RRD
databases for it, which can be used to create historical
# graphs of the
metrics. If the source is a grid (it comes from
# another
gmetad),
# we will only
maintain summary RRDs for it.
#
# Format:
# data_source
"my cluster" [polling interval] address1:port
#
addreses2:port ...
#
# The keyword
'data_source' must immediately be followed by a unique
# string which
identifies the source, then an optional polling
# interval in
# seconds. The
source will be polled at this interval on average.
# If the
polling interval is omitted, 15sec is asssumed.
#
# A list of
machines which service the data source follows, in the
# format
ip:port, or name:port. If a port is not specified then 8649
# (the default
gmond port) is assumed.
# default:
There is no default value
#
# data_source
"my cluster" 10 localhostĀ
my.machine.edu:8649Ā
# 1.2.3.5:8655
# data_source
"my grid" 50 1.3.4.7:8655 grid.org:8651 grid-
#
backup.org:8651
# data_source
"another source" 1.3.4.7:8655Ā
1.3.4.8
data_source
"Master nodes" localhost master-cluster2
data_source
"eixam" node100 node101
data_source
"tenada" node200 node201
data_source
"nozomi" node300 node301
data_source
"storage" disc1 disc3
#
#--------------------------------------------------------------------
# Scalability
mode. If on, we summarize over downstream grids, and
# respect
# authority
tags. If off, we take on 2.5.0-era behavior: we do not
# wrap our
output
# in
<GRID></GRID> tags, we ignore all <GRID> tags we see, and
always
# assume
# we are the
"authority" on data source feeds. This approach does not
# scale to
# large groups
of clusters, but is provided for backwards
#
compatibility.
# default: on
# scalable off
#
#--------------------------------------------------------------------
# The name of
this Grid. All the data sources above will be wrapped
# in a GRID
# tag with this
name.
# default:
Unspecified
gridname
"LCLSI"
#
#--------------------------------------------------------------------
# The authority
URL for this grid. Used by other gmetads to locate
# graphs
# for our data
sources. Generally points to a ganglia/
# website on
this machine.
# default:
"http://hostname/ganglia/",
#ĀĀ where hostname is the name of this machine,
as defined by
#
gethostname().
# authority
"http://mycluster.org/newprefix/"
#
#--------------------------------------------------------------------
# List of
machines this gmetad will share XML with. Localhost
# is always
trusted.
# default:
There is no default value
#trusted_hosts
127.0.0.1 169.229.50.165 my.gmetad.org
trusted_hosts
127.0.0.1 master-cluster2
#
#--------------------------------------------------------------------
# If you want
any host which connects to the gmetad XML to receive
# data, then
set this value to "on"
# default: off
all_trusted on
#
#--------------------------------------------------------------------
# If you don't
want gmetad to setuid then set this to off
# default: on
# setuid off
#
#--------------------------------------------------------------------
# User gmetad
will setuid to (defaults to "nobody")
# default:
"nobody"
setuid_username
"ganglia"
#
#--------------------------------------------------------------------
# The port
gmetad will answer requests for XML
# default: 8651
# xml_port 8651
#
#--------------------------------------------------------------------
# The port
gmetad will answer queries for XML. This facility allows
# simple
subtree and summation views of the XML tree.
# default: 8652
#
interactive_port 8652
#
#--------------------------------------------------------------------
# The number of
threads answering XML requests
# default: 4
#
server_threads 10
#
#--------------------------------------------------------------------
# Where gmetad
stores its round-robin databases
# default: "/var/lib/ganglia/rrds"
# rrd_rootdir
"/some/other/place"
19.1.16. Script jobs_run.sh
#!/bin/bash
# N·mero de jobs (SunGrid) en ejecuci¾n en este nodo
HOSTNAME=`uname
-n`
CLUSTER=`grep
-w ^$HOSTNAME /etc/nodes | awk '{print $5}'`
/usr/local/sge/bin/lx24-x86/qstat
-f | grep $CLUSTER@$HOSTNAME | awk '{print $3}' | cut -f 1 -d/
19.1.17. Script jobs_run-slave.sh
#!/bin/bash
# N·mero de jobs (SunGrid) en ejecuci¾n en este nodo
HOSTNAME=`uname
-n`
CLUSTER=`grep
-w ^$HOSTNAME /etc/nodes | awk '{print $5}'`
INFO_NODE=`/usr/local/sge/bin/lx24-x86/qstat
-f | grep $CLUSTER-nice@$HOSTNAME`
# Buscamos flags de instancia suspendida ("A" por superar umbral de carga, "C" por calendario)
SUSPENDED=`echo $INFO_NODE|awk '{print $6}'|egrep -e A -e C|wc -l`
if [ $SUSPENDED
-eq 0 ]; then
ĀĀ echo $INFO_NODE|awk '{print $3}'|cut -f 1
-d/
else
ĀĀ echo 0
fi
19.1.18. Script jobs_queued.sh
#!/bin/sh
# Retorna jobs encolados
# Queremos que s¾lo el master que corre sgemaster lo ejecute.
DRDB_STATUS=`/sbin/drbdadm
state r1 |cut -f1 -d/`
if [
"$DRDB_STATUS" == "Primary" ]; then
ĀĀ echo `/usr/local/sge/bin/lx24-x86/qstat -s p
-u "*" | wc -l`
else
ĀĀ echo "0"
fi
19.1.19. Script temp_max.sh
#!/bin/bash
# Devuelve la temperatura del core mßs caliente
# Identificamos tipo de procesador
#
# Dell (Core2/CoreQuad == Xeon)
# Pentium4
(Pentium4 Hyperthreading == Pentium 4)
# AMD (AMD64/X2
== Athlon 64)
PROC_TYPE=`/usr/sbin/dmidecode
-s processor-family|head -1`
# Cargamos
modulos de temperatura
if [
"$PROC_TYPE" == "Xeon" ]; then
ĀĀ if [ `lsmod |grep coretemp|wc -l` == 0 ];
then
ĀĀĀĀĀ /sbin/modprobe -q coretemp
ĀĀ fi
ĀĀ if [ `lsmod |grep coretemp|wc -l` == 0 ];
then
ĀĀĀĀĀ echo "-1"
ĀĀĀĀĀ exit 1
ĀĀ fi
ĀĀ TEMP=`/usr/local/bin/sensors | grep Core |
awk '{print $3}' | cut -f2 -d+ | cut -f1 -d?|head -1`
elif [
"$PROC_TYPE" == "Pentium 4" ]; then
ĀĀ if [ `lsmod |grep lm85|wc -l` == 0 ]; then
ĀĀĀĀĀ /sbin/modprobe -q lm85
ĀĀ fi
ĀĀ TEMP=`/usr/local/bin/sensors | grep
"CPU Temp" | awk '{print $3}' | cut -f2 -d+ | cut -f1 -d?|head -1`
elif [
"$PROC_TYPE" == "Athlon 64" ]; then
ĀĀ if [ `lsmod |grep i2c-nforce2|wc -l` == 0 ];
then
ĀĀĀĀĀ /sbin/modprobe -q i2-nforce2
ĀĀ fi
ĀĀ TEMP=`/usr/local/bin/sensors | grep Core |
awk '{print $3}' | cut -f2 -d+ | cut -f1 -d?|head -1`
else
ĀĀ # Tipo de procesador desconocido
ĀĀ echo "-1"
fi
echo $TEMP
19.1.20. Fichero cluster_extra.tpl
<!-- A place
to put custom HTML for the cluster view. -->
<BR>
<A
HREF="./graph2.php?g=sge_jobs_run&z=large&{graph_args}">
<IMG
BORDER=0 ALT="{cluster} JOBS RUNNING"
ĀĀĀ
SRC="./graph2.php?g=sge_jobs_run&z=small&{graph_args}">
</A>
<TABLE
BORDER="0" WIDTH="100%">
<!-- START
BLOCK : source_info -->
<TR>
Ā <TD CLASS={class} COLSPAN=5>
ĀĀ <A
HREF="{url}"><STRONG>{name}</STRONG></A>
{alt_view}
Ā </TD>
</TR>
<TR>
Ā<!-- START BLOCK : public -->
Ā<TD ALIGN="LEFT"
VALIGN="TOP">
<table
cellspacing=1 cellpadding=1 width="100%" border=0>
Ā<tr><td>CPUs
Total:</td><td
align=left><B>{cpu_num}</B></td></tr>
Ā<tr><td
width="80%">Hosts up:</td><td
align=left><B>{num_nodes}</B></td></tr>
Ā<tr><td>Hosts
down:</td><td align=left><B>{num_dead_nodes}</B></td></tr>
Ā<tr><td></td></tr>
Ā<tr><td>Total
Disk:</td><td
align=left><B>{lustre_total}</B></td></tr>
Ā<tr><td>Free
Disk:</td><td align=left><B>{lustre_total_free}</B>
Ā<tr><td> </td></tr>
Ā<tr><td> </td></tr>
</table>
Ā </TD>
Ā <TD VALIGN=top align=right>
Ā <A
HREF="./graph2.php?{graph_url}&g=load_report&z=large&r={range}">
ĀĀ <IMG
SRC="./graph2.php?{graph_url}&g=load_report&z=small&r={range}"
ĀĀĀĀĀĀ ALT="{name} Load"
BORDER="0">
Ā </A>
Ā </TD>
Ā <TD VALIGN=top align=right>
Ā <A HREF="./graph2.php?{graph_url}&g=mem_report&z=large&r={range}">
ĀĀ <IMG
SRC="./graph2.php?{graph_url}&g=mem_report&z=small&r={range}"
ĀĀĀĀĀĀ ALT="{name} MEM"
BORDER="0">
Ā </A>
ĀĀ </TD>
Ā <TD VALIGN=top align=right>
Ā <A HREF="./graph2.php?{graph_url}&g=network_report&z=large&r={range}">
ĀĀ <IMG
SRC="./graph2.php?{graph_url}&g=network_report&z=small&r={range}"
ĀĀĀĀĀĀ ALT="{name} MEM"
BORDER="0">
Ā </A>
ĀĀ </TD>
Ā <TD VALIGN=top align=right>
ĀĀ <A
HREF="./graph2.php?{graph_url}&g=sge_jobs_run&z=large&r={range}"
VALIGN=medium>
ĀĀ <IMG
SRC="./graph2.php?{graph_url}&g=sge_jobs_run&z=small&r={range}"
ĀĀĀĀĀĀ ALT="{name} JOBS"
BORDER="0" ALIGN="CENTER">
Ā </A>
ĀĀ </TD>
<!-- END
BLOCK : public -->
<!-- START
BLOCK : private -->
Ā <TD ALIGN="LEFT" VALIGN="TOP">
<table
cellspacing=1 cellpadding=1 width=100% border=0>
Ā<tr><td>CPUs
Total:</td><td
align=left><B>{cpu_num}</B></td></tr>
Ā<tr><td
width=80%>Nodes:</td><td
align=left><B>{num_nodes}</B></td></tr>
Ā<tr><td> </td></tr>
Ā<tr><td class=footer colspan=2>{localtime}</td></tr>
</table>
ĀĀ </TD>
ĀĀ <TD COLSPAN=2 align=center>This is a
private cluster.</TD>
<!-- END
BLOCK : private -->
</TR>
<!-- END
BLOCK : source_info -->
</TABLE>
<!-- START
BLOCK : show_snapshot -->
<TABLE
BORDER="0" WIDTH="100%">
<TR>
Ā <TD COLSPAN="2"
CLASS=title>Snapshot of the {self} |
ĀĀ <FONT SIZE="-1"><A
HREF="./cluster_legend.html" ALT="Node Image
Legend">Legend</A></FONT>
Ā </TD>
</TR>
</TABLE>
<CENTER>
<TABLE
CELLSPACING=12 CELLPADDING=2>
<!-- START
BLOCK : snap_row -->
<tr>{names}</tr>
<tr>{images}</tr>
<!-- END
BLOCK : snap_row -->
</TABLE>
</CENTER>
<!-- END
BLOCK : show_snapshot -->
19.1.21. Fichero meta_view.tpl
<TABLE
BORDER="0" WIDTH="100%">
<!-- START
BLOCK : source_info -->
<TR>
Ā <TD CLASS={class} COLSPAN=5>
ĀĀ <A
HREF="{url}"><STRONG>{name}</STRONG></A>
{alt_view}
Ā </TD>
</TR>
<TR>
Ā<!-- START BLOCK : public -->
Ā<TD ALIGN="LEFT"
VALIGN="TOP">
<table
cellspacing=1 cellpadding=1 width="100%" border=0>
Ā<tr><td>CPUs
Total:</td><td
align=left><B>{cpu_num}</B></td></tr>
Ā<tr><td
width="80%">Hosts up:</td><td
align=left><B>{num_nodes}</B></td></tr>
Ā<tr><td>Hosts
down:</td><td
align=left><B>{num_dead_nodes}</B></td></tr>
Ā<tr><td></td></tr>
Ā<tr><td>Total
Disk:</td><td
align=left><B>{lustre_total}</B></td></tr>
Ā<tr><td>Free
Disk:</td><td align=left><B>{lustre_total_free}</B>
Ā<tr><td> </td></tr>
Ā<tr><td> </td></tr>
</table>
Ā </TD>
Ā <TD VALIGN=top align=right>
Ā <A HREF="./graph2.php?{graph_url}&g=load_report&z=large&r={range}">
ĀĀ <IMG
SRC="./graph2.php?{graph_url}&g=load_report&z=small&r={range}"
ĀĀĀĀĀĀ ALT="{name} Load"
BORDER="0">
Ā </A>
Ā </TD>
Ā <TD VALIGN=top align=right>
Ā <A HREF="./graph2.php?{graph_url}&g=mem_report&z=large&r={range}">
ĀĀ <IMG
SRC="./graph2.php?{graph_url}&g=mem_report&z=small&r={range}"
ĀĀĀĀĀĀ ALT="{name} MEM"
BORDER="0">
Ā </A>
ĀĀ </TD>
Ā <TD VALIGN=top align=right>
Ā <A
HREF="./graph2.php?{graph_url}&g=network_report&z=large&r={range}">
ĀĀ <IMG
SRC="./graph2.php?{graph_url}&g=network_report&z=small&r={range}"
ĀĀĀĀĀĀ ALT="{name} MEM"
BORDER="0">
Ā </A>
ĀĀ </TD>
Ā <TD VALIGN=top align=right>
ĀĀ <A
HREF="./graph2.php?{graph_url}&g=sge_jobs_run&z=large&r={range}"
VALIGN=medium>
ĀĀ <IMG SRC="./graph2.php?{graph_url}&g=sge_jobs_run&z=small&r={range}"
ĀĀĀĀĀĀ ALT="{name} JOBS"
BORDER="0" ALIGN="CENTER">
Ā </A>
ĀĀ </TD>
<!-- END
BLOCK : public -->
<!-- START
BLOCK : private -->
Ā <TD ALIGN="LEFT"
VALIGN="TOP">
<table
cellspacing=1 cellpadding=1 width=100% border=0>
Ā<tr><td>CPUs
Total:</td><td
align=left><B>{cpu_num}</B></td></tr>
Ā<tr><td
width=80%>Nodes:</td><td
align=left><B>{num_nodes}</B></td></tr>
Ā<tr><td> </td></tr>
Ā<tr><td class=footer
colspan=2>{localtime}</td></tr>
</table>
ĀĀ </TD>
ĀĀ <TD COLSPAN=2 align=center>This is a
private cluster.</TD>
<!-- END
BLOCK : private -->
</TR>
<!-- END
BLOCK : source_info -->
</TABLE>
<!-- START
BLOCK : show_snapshot -->
<TABLE
BORDER="0" WIDTH="100%">
<TR>
Ā <TD COLSPAN="2"
CLASS=title>Snapshot of the {self} |
ĀĀ <FONT SIZE="-1"><A
HREF="./cluster_legend.html" ALT="Node Image
Legend">Legend</A></FONT>
Ā </TD>
</TR>
</TABLE>
<CENTER>
<TABLE
CELLSPACING=12 CELLPADDING=2>
<!-- START
BLOCK : snap_row -->
<tr>{names}</tr>
<tr>{images}</tr>
<!-- END
BLOCK : snap_row -->
</TABLE>
</CENTER>
<!-- END
BLOCK : show_snapshot -->
19.1.22. Fichero graph.php
<?php
/* $Id:
graph.php 970
include_once
"./conf.php";
include_once
"./functions.php";
include_once
"./get_context.php";
# RFM - Added
all the isset() tests to eliminate "undefined index"
# messages in
ssl_error_log.
# Graph
specific variables
# ATD - No need
for escapeshellcmd or rawurldecode on $size or $graph.Ā Not used directly in rrdto
ol calls.
$size =
isset($_GET["z"]) && in_array( $_GET[ 'z' ],
$graph_sizes_keys ) ?
ĀĀĀĀĀĀĀ $_GET["z"] : NULL;
# ATD - TODO,
should encapsulate these custom graphs in some type of container, then this
code cou
ld check list
of defined containers for valid graph labels.
$graph =
isset($_GET["g"]) && in_array( $_GET['g'], array(
'cpu_report', 'mem_report', 'load_repor
t',
'network_report', 'packet_report', 'sge_jobs_run', 'lustre_report' ) ) ?
ĀĀĀĀĀĀĀ $_GET["g"] : NULL;
$grid =
isset($_GET["G"]) ?
ĀĀĀĀĀĀĀ escapeshellcmd( clean_string(
rawurldecode( $_GET["G"] ) ) ) : NULL;
$self =
isset($_GET["me"]) ?
ĀĀĀĀĀĀĀ escapeshellcmd( clean_string(
rawurldecode($_GET["me"] ) ) ) : NULL;
$max =
isset($_GET["x"]) ?
ĀĀĀĀĀĀĀ clean_number(
rawurldecode($_GET["x"] ) ) : NULL;
$min =
isset($_GET["n"]) ?
ĀĀĀĀĀĀĀ clean_number(
rawurldecode($_GET["n"] ) ) : NULL;
$value =
isset($_GET["v"]) ?
ĀĀĀĀĀĀĀ clean_number( rawurldecode(
$_GET["v"] ) ) : NULL;
$load_color =
isset($_GET["l"]) && is_valid_hex_color( rawurldecode( $_GET[
'l' ] ) ) ?
ĀĀĀĀĀĀĀ escapeshellcmd( rawurldecode(
$_GET["l"] ) ) : NULL;
$vlabel =
isset($_GET["vl"]) ?
ĀĀĀĀĀĀĀ escapeshellcmd( clean_string(
rawurldecode( $_GET["vl"] ) ) ) : NULL;
$sourcetime =
isset($_GET["st"]) ?
ĀĀĀĀĀĀĀ clean_number( $_GET["st"] ) :
NULL;
# RFM - Define
these variables to avoid "Undefined variable" errors being
# reported in
ssl_error_log.
$command = "";
$extras =
"";
$upper_limit =
"";
$lower_limit =
"";
$background =
"";
$vertical_label
= "";
# Assumes we
have a $start variable (set in get_context.php).
# $graph_sizes
and $graph_sizes_keys defined in conf.php.Ā
Add custom sizes there.
if( in_array( $size,
$graph_sizes_keys ) ) {
Ā $height = $graph_sizes[ $size ][ 'height' ];
Ā $width = $graph_sizes[ $size ][ 'width' ];
Ā $fudge_0 = $graph_sizes[ $size ][ 'fudge_0'
];
Ā $fudge_1 = $graph_sizes[ $size ][ 'fudge_1'
];
Ā $fudge_2 = $graph_sizes[ $size ][ 'fudge_2'
];
} else {
Ā $height = $graph_sizes[ 'default' ][ 'height'
];
Ā $width = $graph_sizes[ 'default' ][ 'width'
];
Ā $fudge_0 = $graph_sizes[ 'default' ][
'fudge_0' ];
Ā $fudge_1 = $graph_sizes[ 'default' ][
'fudge_1' ];
Ā $fudge_2 = $graph_sizes[ 'default' ][
'fudge_2' ];
}
# This security
fix was brought to my attention by Peter Vreugdenhil
<petervre@sci.kun.nl>
# Dont want
users specifying their own malicious command via GET variables e.g.
#
http://ganglia.mrcluster.org/graph.php?graph=blob&command=whoami;cat%20/etc/passwd
#
if($command)
ĀĀĀ {
ĀĀĀĀĀ exit();
ĀĀĀ }
switch
($context)
{
ĀĀĀ case "meta":
ĀĀĀĀĀ $rrd_dir =
"$rrds/__SummaryInfo__";
ĀĀĀĀĀ break;
ĀĀĀ case "grid":
ĀĀĀĀĀ $rrd_dir =
"$rrds/$grid/__SummaryInfo__";
ĀĀĀĀĀ break;
ĀĀĀ case "cluster":
ĀĀĀĀĀ $rrd_dir =
"$rrds/$clustername/__SummaryInfo__";
ĀĀĀĀĀ break;
ĀĀĀ case "host":
ĀĀĀĀĀ $rrd_dir =
"$rrds/$clustername/$hostname";
ĀĀĀĀĀ break;
ĀĀĀ default:
ĀĀĀĀĀ exit;
}
$fudge = 0;
if
($graph)ĀĀ /* Canned graph request */
ĀĀĀ {
ĀĀĀĀĀ if($graph == "jobs_run")
ĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀ $fudge = $fudge_1;
ĀĀĀĀĀĀĀĀĀĀĀ $style = "CPU";
ĀĀĀĀĀĀĀĀĀĀĀ $upper_limit = "--upper-limit
100 --rigid";
ĀĀĀĀĀĀĀĀĀĀĀ $lower_limit = "--lower-limit
0";
ĀĀĀ ĀĀĀĀĀĀĀĀ$vertical_label =
"--vertical-label Percent ";
if($context !=
"host" )
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ /* If we are not in a host
context, then we need to calculate the average */
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series =
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ "DEF:'num_nodes'='${rrd_dir}/cpu_user.rrd':'num':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'cpu_user'='${rrd_dir}/cpu_user.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'ccpu_user'=cpu_user,num_nodes,/ "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'cpu_nice'='${rrd_dir}/cpu_nice.rrd':'sum':AVERAGE "
Ā ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ."CDEF:'ccpu_nice'=cpu_nice,num_nodes,/
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'cpu_system'='${rrd_dir}/cpu_system.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'ccpu_system'=cpu_system,num_nodes,/ "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'cpu_idle'='${rrd_dir}/cpu_idle.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'ccpu_idle'=cpu_idle,num_nodes,/ "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."AREA:'ccpu_user'#$cpu_user_color:'User CPU' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."STACK:'ccpu_nice'#$cpu_nice_color:'Nice CPU' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ."STACK:'ccpu_system'#$cpu_system_color:'System
CPU' ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ if
(file_exists("$rrd_dir/cpu_wio.rrd")) {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series .=
"DEF:'cpu_wio'='${rrd_dir}/cpu_wio.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'ccpu_wio'=cpu_wio,num_nodes,/ "
ĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ."STACK:'ccpu_wio'#$cpu_wio_color:'WAIT
CPU' ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series .=
"STACK:'ccpu_idle'#$cpu_idle_color:'Idle CPU' ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series ="DEF:'cpu_user'='${rrd_dir}/cpu_user.rrd':'sum':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'cpu_nice'='${rrd_dir}/cpu_nice.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'cpu_system'='${rrd_dir}/cpu_system.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'cpu_idle'='${rrd_dir}/cpu_idle.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."AREA:'cpu_user'#$cpu_user_color:'User CPU' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."STACK:'cpu_nice'#$cpu_nice_color:'Nice CPU' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."STACK:'cpu_system'#$cpu_system_color:'System CPU' ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ if (file_exists("$rrd_dir/cpu_wio.rrd"))
{
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series .=
"DEF:'cpu_wio'='${rrd_dir}/cpu_wio.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."STACK:'cpu_wio'#$cpu_wio_color:'WAIT CPU' ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series .=
"STACK:'cpu_idle'#$cpu_idle_color:'Idle CPU' ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀ else if ($graph ==
"mem_report")
ĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀ $fudge = $fudge_0;
ĀĀĀĀĀĀĀĀĀĀĀ $style = "Memory";
ĀĀĀĀĀĀĀĀĀĀĀ $lower_limit = "--lower-limit
0 --rigid";
ĀĀĀĀĀĀĀĀĀĀĀ $extras = "--base 1024";
ĀĀĀĀĀĀĀĀĀĀĀ $vertical_label = "--vertical-label Bytes";
ĀĀĀĀĀĀĀĀĀĀĀ
$series =
"DEF:'mem_total'='${rrd_dir}/mem_total.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'bmem_total'=mem_total,1024,* "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ."DEF:'mem_shared'='${rrd_dir}/mem_shared.rrd':'sum':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'bmem_shared'=mem_shared,1024,* "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'mem_free'='${rrd_dir}/mem_free.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'bmem_free'=mem_free,1024,* "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ."DEF:'mem_cached'='${rrd_dir}/mem_cached.rrd':'sum':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'bmem_cached'=mem_cached,1024,* "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'mem_buffers'='${rrd_dir}/mem_buffers.rrd':'sum':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'bmem_buffers'=mem_buffers,1024,* "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ."CDEF:'bmem_used'='bmem_total','bmem_shared',-,'bmem_free',-,'bmem_cached',-,'bmem
_buffers',-
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."AREA:'bmem_used'#$mem_used_color:'Used RAMĀĀĀĀ ' ";
ĀĀĀĀĀĀĀĀĀĀĀ if
(file_exists("$rrd_dir/swap_total.rrd")) {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series .= "DEF:'swap_total'='${rrd_dir}/swap_total.rrd':'sum':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'swap_free'='${rrd_dir}/swap_free.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'bmem_swapped'='swap_total','swap_free',-,1024,* ";
ĀĀĀĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀĀĀĀĀĀĀ $series .= "LINE2:'bmem_total'#$cpu_num_color:'Total
RAM' ";
ĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀ else if ($graph ==
"load_report")
ĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀ $fudge = $fudge_2;
ĀĀĀĀĀĀĀĀĀĀĀ $style = "Load";
ĀĀĀĀĀĀĀĀĀĀĀ $lower_limit = "--lower-limit
0 --rigid";
ĀĀĀĀĀĀĀĀĀĀĀ $vertical_label =
"--vertical-label 'Load/Procs'";
ĀĀĀĀĀĀĀĀĀĀĀ $series =
"DEF:'load_one'='${rrd_dir}/load_one.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'proc_run'='${rrd_dir}/proc_run.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ."DEF:'cpu_num'='${rrd_dir}/cpu_num.rrd':'sum':AVERAGE
";
ĀĀĀĀĀĀĀĀĀĀĀ if( $context != "host" )
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series
.="DEF:'num_nodes'='${rrd_dir}/cpu_num.rrd':'num':AVERAGE ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀĀĀĀĀĀĀ $series
.="AREA:'load_one'#$load_one_color:'1-min Load' ";
ĀĀĀĀĀĀĀĀĀĀĀ if( $context != "host" )
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series .=
"LINE2:'num_nodes'#$num_nodes_color:'Nodes' ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀĀĀĀĀĀĀ $series
.="LINE2:'cpu_num'#$cpu_num_color:'CPUs' ";
ĀĀĀĀĀĀĀĀĀĀĀ $series .="LINE2:'proc_run'#$proc_run_color:'Running
Processes' ";
ĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀ else if ($graph ==
"network_report")
ĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀ $fudge = $fudge_2;
ĀĀĀĀĀĀĀĀĀĀĀ $style = "Network";
ĀĀĀĀĀĀĀĀĀĀĀ $lower_limit = "--lower-limit
0 --rigid";
ĀĀĀĀĀĀĀĀĀĀĀ $extras = "--base 1024";
ĀĀĀĀĀĀĀĀĀĀĀ $vertical_label = "--vertical-label 'Bytes/sec'";
ĀĀĀĀĀĀĀĀĀĀĀ
$series =
"DEF:'bytes_in'='${rrd_dir}/bytes_in.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'bytes_out'='${rrd_dir}/bytes_out.rrd':'sum':AVERAGE "
."LINE2:'bytes_in'#$mem_cached_color:'InĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 'ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."LINE2:'bytes_out'#$mem_used_color:'Out' ";
ĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀ else if ($graph ==
"packet_report")
ĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀ $fudge = $fudge_2;
ĀĀĀĀĀĀĀĀĀĀĀ $style = "Packets";
ĀĀĀĀĀĀĀĀĀĀĀ $lower_limit = "--lower-limit
0 --rigid";
ĀĀĀĀĀĀĀĀĀĀĀ $extras = "--base 1024";
ĀĀĀĀĀĀĀĀĀĀĀ $vertical_label =
"--vertical-label 'Packets/sec'";
ĀĀĀĀĀĀĀĀĀĀĀ $series =
"DEF:'bytes_in'='${rrd_dir}/pkts_in.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀ ĀĀĀĀĀ."DEF:'bytes_out'='${rrd_dir}/pkts_out.rrd':'sum':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."LINE2:'bytes_in'#$mem_cached_color:'In' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."LINE2:'bytes_out'#$mem_used_color:'Out' ";
ĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀ else if ($graph ==
"sge_jobs_run")
ĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀ ĀĀĀ$fudge = $fudge_2;
ĀĀĀĀĀĀĀĀĀĀĀ $style = "";
ĀĀĀĀĀĀĀĀĀĀĀ $lower_limit = "--lower-limit
0 --rigid";
ĀĀĀĀĀĀĀĀĀĀĀ $extras = "--base 1024";
ĀĀĀĀĀĀĀĀĀĀĀ $vertical_label = "--vertical-label '# Jobs'";
ĀĀĀĀĀĀĀĀĀĀĀ
if ($context ==
"cluster")
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ if ($clustername ==
"Master nodes")
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ #Dividir jobs encolados /2
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series =
"DEF:'temp'='${rrd_dir}/jobs_queued.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
#."CDEF:'jobs_1'='temp',2,/ "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'jobs_2'='temp',2,- "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'jobs_3'='jobs_2',0,GT,'jobs_2',0,IF "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."LINE2:'jobs_3'#$proc_run_color:'Queued' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."GPRINT:'jobs_3':LAST:'ĀĀĀ
%6.0lf ' ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ĀĀĀ}
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series =
"DEF:'jobs_run'='${rrd_dir}/sge_jobs_run.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'jobs_run-slave'='${rrd_dir}/sge_jobs_run-slave.rrd':'sum':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ."DEF:'cpu_num'='${rrd_dir}/cpu_num.rrd':'sum':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."LINE1:'cpu_num'#$cpu_num_color:'Max' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."GPRINT:'cpu_num':LAST:' %2.0lfĀĀĀĀĀĀĀĀ ' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."AREA:'jobs_run'#$proc_run_color:'Running prio' "
ĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ."GPRINT:'jobs_run':LAST:'%2.0lfĀĀĀĀĀĀĀĀ ' "ĀĀĀĀĀĀĀ
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."STACK:'jobs_run-slave'#$mem_buffered_color:'Running nice' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."GPRINT:'jobs_run-slave':LAST:' %2.0lf ' ";ĀĀĀĀĀĀĀ
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀĀĀĀĀĀ ĀĀĀĀ}
ĀĀĀĀĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series =
"DEF:'jobs_run'='${rrd_dir}/sge_jobs_run.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'cpu_num'='${rrd_dir}/cpu_num.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # Restamos cpus de masters y servidores de disco (4+12)
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ."CDEF:'cpu_num_real'='cpu_num',10,-
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'jobs_run-slave'='${rrd_dir}/sge_jobs_run-slave.rrd':'sum':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."LINE1:'cpu_num_real'#$cpu_num_color:'Max' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."GPRINT:'cpu_num_real':LAST:' %2.0lfĀĀĀĀĀ ' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."AREA:'jobs_run'#$proc_run_color:'Running prio' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."GPRINT:'jobs_run':LAST:'%3.0lfĀĀĀĀĀ ' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."STACK:'jobs_run-slave'#$mem_buffered_color:'Running nice' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."GPRINT:'jobs_run-slave':LAST:'ĀĀĀ
%2.0lf ' ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀ
ĀĀĀĀĀ else if ($graph ==
"lustre_report")
ĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀ $fudge = $fudge_2;
ĀĀĀĀĀĀĀĀĀĀĀ $style = "Free Disk";
ĀĀĀĀĀĀĀĀĀĀĀ $lower_limit = "--lower-limit
0 --rigid";
ĀĀĀĀĀĀĀĀĀĀĀ $vertical_label =
"--vertical-label 'Bytes'";
ĀĀĀĀĀĀĀĀĀĀĀ
ĀĀĀĀĀĀĀĀĀĀĀ exec("echo
'AFR_1\nAFR_2\nAFR_3'",$OSTS);
ĀĀĀĀĀĀĀĀĀĀĀ $series =
"DEF:'total_tmp'='${rrd_dir}/lustre_total.rrd':'sum':AVERAGE "
ĀĀĀĀĀĀĀĀĀ ĀĀ."CDEF:'total'='total_tmp',1024,* "
ĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'total_gb'='total',1073741824,/ "
ĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'total_free'='${rrd_dir}/lustre_total_free.rrd':'sum':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'total_free_gb'='total_free',1048576,/ ";
ĀĀĀĀĀĀĀĀĀĀĀ foreach ( $OSTS as $ost_i )
ĀĀĀĀĀĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series = "$series"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'lustre_${ost_i}_tmp'='${rrd_dir}/${ost_i}_total.rrd':'sum':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ
."DEF:'lustre_${ost_i}_free_tmp'='${rrd_dir}/${ost_i}_free.rrd':'sum':AVERAGE
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'lustre_${ost_i}_free_gb'='lustre_${ost_i}_free_tmp',1048576,/
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'lustre_${ost_i}'='lustre_${ost_i}_tmp',1024,* "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'lustre_${ost_i}_gb'='lustre_${ost_i}',1073741824,/ "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ."CDEF:'lustre_${ost_i}_pc_tmp'='lustre_${ost_i}_gb','lustre_${ost_i}_free_gb',/
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."CDEF:'lustre_${ost_i}_pc'='lustre_${ost_i}_pc_tmp',100,* ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ if ( $ost_i == "AFR_1"
) {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series = "$series"
ĀĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀĀĀ."AREA:'lustre_${ost_i}'#".$$ost_i.":'$ost_i'
";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ else {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series =
"$series"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."STACK:'lustre_${ost_i}'#".$$ost_i.":'$ost_i' ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $series = "$series"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."GPRINT:'lustre_${ost_i}_gb':LAST:'%4.1lf GB' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."GPRINT:'lustre_${ost_i}_pc':LAST:'(%3.1lf %%)\ ' ";
ĀĀĀĀĀĀĀĀĀĀĀĀĀ }
$series =
"$series"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."LINE2:'total'#$LUSTRE_TOTAL:'Total Disk' "
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ."LINE2:'total'#$LUSTRE_TOTAL:
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ."COMMENT:'Total Free'
"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
."GPRINT:'total_free_gb':LAST:'%4.1lf GBĀĀĀĀĀ ' ";
ĀĀĀĀĀĀĀĀĀ
ĀĀĀĀĀĀ }
ĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀ /* Got a strange value for $graph
*/
ĀĀĀĀĀĀĀĀĀĀĀ exit();
ĀĀĀĀĀĀĀĀ }
ĀĀĀ }
else
ĀĀĀ {
ĀĀĀĀĀ /* Custom graph */
ĀĀĀĀĀ $style = "";
ĀĀĀĀĀ $subtitle = $metricname;
ĀĀĀĀĀ if ($context == "host")
ĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀ if ($size == "small")
ĀĀĀĀĀĀĀĀĀĀĀĀĀ $prefix = $metricname;
ĀĀĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀĀĀĀ $prefix = $hostname;
ĀĀ ĀĀĀĀĀĀĀ$value = $value>1000 ?
number_format($value) : number_format($value, 2);
ĀĀĀĀĀĀĀĀĀ if ($range=="job") {
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $hrs = intval( -$jobrange / 3600
);
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $subtitle = "$prefix last
${hrs}h (now $value)";
ĀĀĀĀĀĀĀĀĀ }
ĀĀĀĀĀĀĀĀĀ else
Ā ĀĀĀĀĀĀĀĀĀĀĀĀ$subtitle = "$prefix last
$range (now $value)";
ĀĀĀĀĀ }
ĀĀĀĀĀ if (is_numeric($max))
ĀĀĀĀĀĀĀĀ $upper_limit = "--upper-limit
'$max' ";
ĀĀĀĀĀ if (is_numeric($min))
ĀĀĀĀĀĀĀĀ $lower_limit ="--lower-limit
'$min' ";
ĀĀĀĀĀ if ($vlabel)
ĀĀĀĀĀĀĀĀ $vertical_label = "--vertical-label '$vlabel'";
ĀĀĀĀĀ else if ($upper_limit or
$lower_limit)
ĀĀĀĀĀĀĀĀ {
ĀĀĀĀĀĀĀĀĀĀĀ $max = $max>1000 ?
number_format($max) : number_format($max, 2);
ĀĀĀĀĀĀĀĀĀĀĀ $min = $min>0 ?
number_format($min,2) : $min;
ĀĀĀĀĀĀ ĀĀĀĀĀ$vertical_label ="--vertical-label '$min - $max' ";
ĀĀĀĀĀĀĀĀ
}
ĀĀĀĀĀ $rrd_file =
"$rrd_dir/$metricname.rrd";
ĀĀĀĀĀ $series =
"DEF:'sum'='$rrd_file':'sum':AVERAGE ";
ĀĀĀĀĀĀĀ # LCLSI: quitamos subt?tulo:
ĀĀĀĀĀĀĀĀ
#."AREA:'sum'#$default_metric_color:'$subtitle' ";
ĀĀĀĀĀ if ($jobstart)
ĀĀĀĀĀĀĀĀ $series .=
"VRULE:$jobstart#$jobstart_color ";
ĀĀĀ }
# Set the graph
title.
if($context ==
"meta")
ĀĀ {
ĀĀĀĀ $title = "$self $meta_designator
$style";
ĀĀ }
else if
($context == "grid")
Ā {
ĀĀĀĀ $title = "$grid $meta_designator
$style";
Ā }
else if
($context == "cluster")
ĀĀ {
ĀĀĀĀĀ $title = "$clustername $style";
ĀĀ }
else
ĀĀ {
ĀĀĀ if ($size == "small")
ĀĀĀĀĀ {
ĀĀĀĀĀĀĀ # Value for this graph define a
background color.
ĀĀĀĀĀĀĀ if (!$load_color) $load_color =
"ffffff";
ĀĀĀĀĀĀĀ $background = "--color
BACK#'$load_color'";
ĀĀĀĀĀĀĀ $title = $hostname;
ĀĀĀĀĀ }
ĀĀĀ else if ($style)
ĀĀĀĀĀĀ $title = "$hostname $style";
ĀĀĀ else
ĀĀĀĀĀĀ $title = $metricname;
ĀĀ }
# Calculate
time range.
if
($sourcetime)
ĀĀ {
ĀĀĀĀĀ $end = $sourcetime;
ĀĀĀĀĀ # Get_context makes start negative.
ĀĀĀĀĀ $start = $sourcetime + $start;
ĀĀ }
# Fix from Phil
Radden, but step is not always 15 anymore.
if
($range=="month")
ĀĀ $end = floor($end / 672) * 672;
#
# Generate the
rrdtool graph command.
#
$fudge +=
$height;
$command =
RRDTOOL . " graph - --start $start --end $end ".
ĀĀ "--width $width --height $fudge
$upper_limit $lower_limit ".
ĀĀ "--title '$title' $vertical_label
$extras $background ".
ĀĀ $series;
$debug=0;
# Did we
generate a command?ĀĀ Run it.
if($command)
Ā{
ĀĀ /*Make sure the image is not cached*/
ĀĀ header ("Expires: Mon,
ĀĀ header ("Last-Modified: " .
gmdate("D, d M Y H:i:s") . " GMT"); // always modified
ĀĀ header ("Cache-Control: no-cache,
must-revalidate");ĀĀ // HTTP/1.1
ĀĀ header ("Pragma: no-cache");ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ // HTTP/1.0
ĀĀ if ($debug) {
ĀĀĀĀ header ("Content-type: text/html");
ĀĀĀĀ print htmlentities( $command ) .
"\n\n\n\n\n";
ĀĀĀ }
ĀĀ else {
ĀĀĀĀ header ("Content-type:
image/gif");
ĀĀĀĀ passthru($command);
ĀĀĀ }
Ā}
?>
19.1.23. Script check_sge.sh
#!/bin/bash
STATUS_OK=0
STATUS_WARNING=1
STATUS_ERROR=2
HOSTNAME=`uname
-n`
ERROR=0
if ! [ -f
/usr/local/sge/default/common/act_qmaster ]; then
ĀĀ echo "SGE ERROR: common zone not
mounted on $HOSTNAME"
ĀĀ exit ${STATUS_ERROR}
fi
SGE_MASTER=`cat
/usr/local/sge/default/common/act_qmaster`
if [
"$1" == "master" ]; then {
ĀĀ if [ $HOSTNAME != $SGE_MASTER ]; then {
ĀĀĀĀĀ echo "SGE Master not running, check
$SGE_MASTER"
ĀĀĀĀĀ exit ${STATUS_OK}
ĀĀĀĀĀ }
ĀĀ else {
ĀĀĀĀĀ SGE_RUNNING=`ps waux | grep sge_qmaster |
grep -v grep|wc -l`
ĀĀĀĀĀ if [ $SGE_RUNNING -eq 0 ]; then
ĀĀĀĀĀĀĀĀ echo "SGE ERROR: SGE missing on
$HOSTNAME"
ĀĀĀĀĀĀĀĀ exit ${STATUS_ERROR}
ĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀ echo "SGE master running on
$HOSTNAME"
ĀĀĀĀĀĀĀĀ exit ${STATUS_OK}
ĀĀĀĀĀ fi
ĀĀĀĀĀ }
ĀĀ fi
Ā }
else
ĀĀ # Nodo de ejecuci¾n. Comprobamos si $1 existe en lista de nodos
ĀĀ NODE_EXIST=`grep -w ^$1
/root/files/nodes/nodes|wc -l`
ĀĀ if [ "$NODE_EXIST" -eq 0 ]; then
ĀĀĀĀĀ echo "Node doesn't exist in
cluster"
ĀĀĀĀĀ
exit ${STATUS_ERROR}
ĀĀ fi
ĀĀ if [
"`/usr/local/sge/bin/lx24-x86/qhost -h $1|grep -w ^$1|awk '{print
$4}'`" == "-" ]; then
ĀĀĀĀĀ echo "SGE ERROR: sge_execd down on
$1"
ĀĀĀĀĀ exit ${STATUS_ERROR}
ĀĀ else
ĀĀĀĀĀ echo "sge_execd running on $1"
ĀĀĀĀĀ exit ${STATUS_OK}
ĀĀ fi
fi
19.1.24. Fichero dhcp.conf
use-host-decl-names
on;
default-lease-time
9999999999;
max-lease-timeĀĀĀĀ 9999999999;
ddns-update-style
interim;
ddns-domainname
"cluster.lsi";
ddns-updates
on;
include
"/etc/dhcp3/dhcpd3.key";
zone
cluster.lsi. {
ĀĀ primary 127.0.0.1;
}
zone
168.192.in-addr.arpa. {
ĀĀ primary 127.0.0.1;
}
failover peer
"cluster-dhcp" {
ĀĀ primary;ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # we are a primary
ĀĀ addressĀĀ
ĀĀĀmaster-cluster1;ĀĀĀĀĀĀĀ # address to listen on
ĀĀ peer address master-cluster2;ĀĀĀĀĀĀĀ # who we connect to
ĀĀ port 519;ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # port to use for
msgs
ĀĀ peer port 521;ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # where we send msgs
ĀĀ max-response-delay 60;ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # how many seconds to
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # wait
before we
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ #
determine a
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ #
failure
ĀĀ max-unacked-updates 10;ĀĀĀĀĀ ĀĀĀĀĀĀĀĀ# number of unacked
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ #
packets to send
ĀĀ mclt 3600;ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # only defined on
primary
ĀĀ split 128;
ĀĀ load balance max seconds 5;
}
subnet
192.168.0.0 netmask 255.255.0.0 {
Ā option routers 192.168.0.202;
Ā option domain-name "lsi.upc.edu";
Ā option domain-name-servers 147.83.20.5,
147.83.20.6, 147.83.2.3;
Āpool {
ĀĀĀĀĀ failover peer "cluster-dhcp";
ĀĀĀĀĀ deny dynamic bootp clients;
ĀĀĀĀĀ range 192.168.0.100 192.168.0.111;
}
Ā group {
ĀĀĀ default-lease-time -1;
ĀĀĀ option vendor-class-identifier
"PXEClient";
ĀĀĀ #### Cluster Nodes ####
ĀĀĀ host node208 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.2.108;
ĀĀĀ }
ĀĀĀ host node313 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.3.113;
ĀĀĀ }
ĀĀĀ host node310 {
Ā hardware ethernet 00:E0:81:71:44:B1;
ĀĀĀĀĀ fixed-address 192.168.3.110;
ĀĀĀ }
ĀĀĀ host node207 {
Ā hardware ethernet 00:E0:81:5D:47:B2;
ĀĀĀĀĀ fixed-address 192.168.2.107;
ĀĀĀ }
ĀĀĀ host node311 {
Ā hardware ethernet 00:E0:81:5E:C0:D6;
ĀĀĀĀĀ fixed-address 192.168.3.111;
ĀĀĀ }
ĀĀĀ host node309 {
Ā hardware ethernet 00:E0:81:55:27:31;
ĀĀĀĀĀ fixed-address 192.168.3.109;
ĀĀĀ }
ĀĀĀ host node308 {
Ā hardware ethernet 00:E0:81:55:27:2F;
ĀĀĀĀĀ fixed-address 192.168.3.108;
ĀĀĀ }
ĀĀĀ host node307 {
Ā hardware ethernet 04:4B:80:80:80:03;
ĀĀĀĀĀ fixed-address 192.168.3.107;
ĀĀĀ }
ĀĀĀ host node312 {
Ā hardware ethernet 00:E0:81:5E:C1:65;
ĀĀĀĀĀ fixed-address 192.168.3.112;
ĀĀĀ }
ĀĀĀ host node111 {
Ā hardware ethernet 00:E0:81:71:41:F8;
fixed-address
192.168.1.111;
ĀĀĀ }
ĀĀĀ host node110 {
Ā hardware ethernet 00:E0:81:71:44:BA;
ĀĀĀĀĀ fixed-address 192.168.1.110;
ĀĀĀ }
ĀĀĀ host node109 {
Ā hardware ethernet 00:E0:81:71:41:BC;
ĀĀĀĀĀ fixed-address 192.168.1.109;
ĀĀĀ }
ĀĀĀ host node108 {
Ā hardware ethernet 00:E0:81:5E:E7:A5;
ĀĀĀĀĀ fixed-address 192.168.1.108;
ĀĀĀ }
ĀĀĀ host node306 {
Ā hardware ethernet 00:E0:81:5E:F7:A1;
ĀĀĀĀĀ fixed-address 192.168.3.106;
ĀĀĀ }
ĀĀĀ host node107 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.1.107;
ĀĀĀ }
ĀĀĀ host node118 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.1.118;
ĀĀĀ }
ĀĀĀ host node117 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.1.117;
ĀĀĀ }
ĀĀĀ host node116 {
Ā hardware ethernet 00:0C:F1:90:A1:DE;
ĀĀĀĀĀ fixed-address 192.168.1.116;
ĀĀĀ }
ĀĀĀ host node115 {
Ā hardware ethernet 00:0C:F1:8F:47:D4;
ĀĀĀĀĀ fixed-address 192.168.1.115;
ĀĀĀ }
ĀĀĀ host node114 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.1.114;
ĀĀĀ }
ĀĀĀ host node113 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.1.113;
ĀĀĀ }
ĀĀĀ host node112 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.1.112;
ĀĀĀ }
ĀĀĀ host node106 {
Ā hardware ethernet 00:E0:81:71:41:F2;
ĀĀĀĀĀ fixed-address 192.168.1.106;
ĀĀĀ }
ĀĀĀ host node304 {
Ā hardware ethernet 00:1E:C9:FE:3E:48;
ĀĀĀĀĀ fixed-address 192.168.3.104;
ĀĀĀ }
ĀĀĀ host node305 {
Ā hardware ethernet 00:1E:C9:FE:45:98;
ĀĀĀĀĀ fixed-address 192.168.3.105;
ĀĀĀ }
ĀĀĀ host node100 {
Ā hardware ethernet 00:1C:23:E3:0C:58;
ĀĀĀĀĀ fixed-address 192.168.1.100;
ĀĀĀ }
ĀĀĀ host node303 {
Ā hardware ethernet 00:1E:C9:FE:3A:49;
ĀĀĀĀĀ fixed-address 192.168.3.103;
ĀĀĀ }
ĀĀĀ host node302 {
Ā hardware ethernet 00:1E:C9:FE:32:4B;
ĀĀĀĀĀ fixed-address 192.168.3.102;
ĀĀĀ }
ĀĀĀ host node301 {
Ā hardware ethernet 00:1D:09:F0:2C:BE;
ĀĀĀĀĀ fixed-address 192.168.3.101;
}
ĀĀĀ host node300 {
Ā hardware ethernet 00:1D:09:F0:2E:83;
ĀĀĀĀĀ fixed-address 192.168.3.100;
ĀĀĀ }
ĀĀĀ host node206 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.2.106;
ĀĀĀ }
ĀĀĀ host node205 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.2.105;
ĀĀĀ }
ĀĀĀ host node204 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.2.104;
ĀĀĀ }
ĀĀĀ host node203 {
Ā hardware ethernet 00:1C:23:E3:08:5C;
ĀĀĀĀĀ fixed-address 192.168.2.103;
ĀĀĀ }
ĀĀĀ host node202 {
Ā hardware ethernet 00:1D:09:F0:D0:BB;
ĀĀĀĀĀ fixed-address 192.168.2.102;
ĀĀĀ }
ĀĀĀ host node201 {
Ā hardware ethernet 00:1D:09:F0:2C:D3;
ĀĀĀĀĀ fixed-address 192.168.2.101;
ĀĀĀ }
ĀĀĀ host node105 {
Ā hardware ethernet 00:1D:09:F0:2E:9B;
ĀĀĀĀĀ fixed-address 192.168.1.105;
ĀĀĀ }
ĀĀĀ host node104 {
Ā hardware ethernet 00:1D:09:F0:2E:FB;
ĀĀĀĀĀ fixed-address 192.168.1.104;
ĀĀĀ }
ĀĀĀ host node103 {
Ā hardware ethernet 00:1D:09:F0:2F:AC;
ĀĀĀĀĀ fixed-address 192.168.1.103;
ĀĀĀ }
ĀĀĀ host node101 {
Ā hardware ethernet 00:1C:23:E3:0B:8C;
ĀĀĀĀĀ fixed-address 192.168.1.101;
ĀĀĀ }
ĀĀĀ host node102 {
Ā hardware ethernet 00:1D:09:F0:30:27;
ĀĀĀĀĀ fixed-address 192.168.1.102;
ĀĀĀ }
ĀĀĀ host node200 {
Ā hardware ethernet 00:1D:09:F0:2E:1A;
ĀĀĀĀĀ fixed-address 192.168.2.100;
ĀĀĀ }
ĀĀĀ host disc6 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.0.106;
ĀĀĀ }
ĀĀĀ host disc5 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.0.105;
ĀĀĀ }
ĀĀĀ host disc4 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.0.104;
ĀĀĀ }
ĀĀĀ host disc3 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.0.103;
ĀĀĀ }
ĀĀĀ host disc2 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.0.102;
ĀĀĀ }
ĀĀĀ host disc1 {
Ā hardware ethernet
ĀĀĀĀĀ fixed-address 192.168.0.101;
ĀĀĀ }
}
}
19.1.25. Fichero update.exim4.conf en master-cluster1
dc_eximconfig_configtype='satellite'
dc_other_hostnames=''
dc_local_interfaces='127.0.0.1;192.168.0.201'
dc_readhost='lsi.upc.edu'
dc_relay_domains=''
dc_minimaldns='false'
dc_relay_nets='192.168.0.0/24'
dc_smarthost='mail.lsi.upc.edu'
CFILEMODE='644'
dc_use_split_config='false'
dc_hide_mailname='true'
dc_mailname_in_oh='true'
dc_localdelivery='mail_spool'
19.1.26. Fichero update.exim4.conf en nodos de computaci¾n y servidores de
disco
dc_eximconfig_configtype='satellite'
dc_other_hostnames=''
dc_local_interfaces='127.0.0.1;192.168.0.202'
dc_readhost='lsi.upc.edu'
dc_relay_domains=''
dc_minimaldns='false'
dc_relay_nets='192.168.0.0/24'
dc_smarthost='mail.lsi.upc.edu'
CFILEMODE='644'
dc_use_split_config='false'
dc_hide_mailname='true'
dc_mailname_in_oh='true'
dc_localdelivery='mail_spool'
19.1.27. Fichero ntp.conf en nodos master-cluster
#
/etc/ntp.conf, configuration for ntpd
driftfile
/var/lib/ntp/ntp.drift
statsdir
/var/log/ntpstats/
statistics
loopstats peerstats clockstats
filegen
loopstats file loopstats type day enable
filegen
peerstats file peerstats type day enable
filegen
clockstats file clockstats type day enable
# You do need
to talk to an NTP server or two (or three).
#server
ntp.your-provider.example
# pool.ntp.org
maps to more than 300 low-stratum NTP servers.
# Your server
will pick a different set every time it starts up.
#Ā *** Please consider joining the pool! ***
#Ā *** <http://www.pool.ntp.org/join.html>
***
server
ntp.lsi.upc.edu iburst
server
hora.rediris.es iburst
server
0.debian.pool.ntp.org iburst
server
1.debian.pool.ntp.org iburst
server
2.debian.pool.ntp.org iburst
server
3.debian.pool.ntp.org iburst
# By default,
exchange time with everybody, but don't allow configuration.
# See
/usr/share/doc/ntp-doc/html/accopt.html for details.
restrict -4
default kod notrap nomodify nopeer noquery
restrict -6
default kod notrap nomodify nopeer noquery
# Local users
may interrogate the ntp server more closely.
restrict
127.0.0.1
restrict ::1
# Clients from
this (example!) subnet have unlimited access,
# but only if
cryptographically authenticated
#restrict
192.168.123.0Ā maskĀ 255.255.255.0 notrust
# If you want
to provide time to your local subnet, change the next line.
# (Again, the
address is an example only.)
broadcast
192.168.0.255
# If you want
to listen to time broadcasts on your local subnet,
# de-comment
the next lines. Please do this only if you trust everybody
# on the
network!
disable auth
broadcastclient
19.1.28. Fichero ntp.conf en nodos de computaci¾n y servidores de disco
#
/etc/ntp.conf, configuration for ntpd
driftfile
/var/lib/ntp/ntp.drift
statsdir
/var/log/ntpstats/
statistics
loopstats peerstats clockstats
filegen
loopstats file loopstats type day enable
filegen
peerstats file peerstats type day enable
filegen
clockstats file clockstats type day enable
# You do need
to talk to an NTP server or two (or three).
#server ntp.your-provider.example
# pool.ntp.org
maps to more than 300 low-stratum NTP servers.
# Your server
will pick a different set every time it starts up.
#Ā *** Please consider joining the pool! ***
#Ā *** <http://www.pool.ntp.org/join.html>
***
server
master-cluster1 iburst
server
master-cluster2 iburst
# By default,
exchange time with everybody, but don't allow configuration.
# See
/usr/share/doc/ntp-doc/html/accopt.html for details.
restrict -4
default kod notrap nomodify nopeer noquery
restrict -6
default kod notrap nomodify nopeer noquery
# Local users
may interrogate the ntp server more closely.
#restrict
127.0.0.1
#restrict ::1
# Clients from
this (example!) subnet have unlimited access,
# but only if
cryptographically authenticated
#restrict
192.168.123.0Ā maskĀ 255.255.255.0 notrust
# If you want
to provide time to your local subnet, change the next line.
# (Again, the
address is an example only.)
#broadcast
192.168.123.255
# If you want
to listen to time broadcasts on your local subnet,
# de-comment
the next lines. Please do this only if you trust everybody
# on the
network!
#disable auth
#broadcastclient
19.1.29. Fichero /etc/exports
/etc/exports
Ā# /etc/exports: the access control list for
filesystems which may be exported
#ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ to NFS clients.Ā See exports(5).
/mnt/glusterfs/homeĀĀĀĀĀ master-cluster2 (ro, fsid=0,
no_root_squash, sync,subtree_check)
19.1.30. Fichero awstats.conf
LogFile="/var/log/apache/access.log"
LogType=W
LogFormat=4
LogSeparator="
"
SiteDomain="master-cluster1.lsi.upc.edu"
HostAliases="localhost
127.0.0.1"
DNSLookup=1
DirData="/var/lib/awstats"
DirCgi="/cgi-bin"
DirIcons="/awstats-icon"
AllowToUpdateStatsFromBrowser=0
AllowFullYearView=2
EnableLockForUpdate=0
DNSStaticCacheFile="dnscache.txt"
DNSLastUpdateCacheFile="dnscachelastupdate.txt"
SkipDNSLookupFor=""
AllowAccessFromWebToAuthenticatedUsersOnly=0
AllowAccessFromWebToFollowingAuthenticatedUsers=""
AllowAccessFromWebToFollowingIPAddresses=""
CreateDirDataIfNotExists=0
BuildHistoryFormat=text
BuildReportFormat=html
SaveDatabaseFilesWithPermissionsForEveryone=0
PurgeLogFile=0
ArchiveLogRecords=0
KeepBackupOfHistoricFiles=0
DefaultFile="index.html"
SkipHosts=""
SkipUserAgents=""
SkipFiles=""
SkipReferrersBlackList=""
OnlyHosts=""
OnlyUserAgents=""
OnlyFiles=""
NotPageList="css
js class gif jpg jpeg png bmp ico swf"
ValidHTTPCodes="200
304"
ValidSMTPCodes="1
250"
AuthenticatedUsersNotCaseSensitive=0
URLNotCaseSensitive=0
URLWithAnchor=0
URLQuerySeparators="?;"
URLWithQuery=0
URLWithQueryWithOnlyFollowingParameters=""
URLWithQueryWithoutFollowingParameters=""
URLReferrerWithQuery=0
WarningMessages=1
ErrorMessages=""
DebugMessages=0
NbOfLinesForCorruptedLog=50
WrapperScript=""
DecodeUA=0
MiscTrackerUrl="/js/awstats_misc_tracker.js"
LevelForBrowsersDetection=2ĀĀĀĀĀĀĀĀ # 0 disables Browsers detection.
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # 2 reduces
AWStats speed by 2%
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # allphones
reduces AWStats speed by 5%
LevelForOSDetection=2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # 0 disables OS detection.
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # 2 reduces
AWStats speed by 3%
LevelForRefererAnalyze=2ĀĀĀĀĀĀĀĀĀĀĀ # 0 disables Origin detection.
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # 2 reduces
AWStats speed by 14%
LevelForRobotsDetection=2ĀĀĀĀĀĀĀĀĀĀ # 0 disables Robots detection.
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ĀĀ# 2 reduces AWStats speed by 2.5%
LevelForSearchEnginesDetection=2ĀĀĀ # 0 disables Search engines detection.
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # 2 reduces
AWStats speed by 9%
LevelForKeywordsDetection=2ĀĀĀĀĀĀĀĀ # 0 disables Keyphrases/Keywords
detection.
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # 2 reduces
AWStats speed by 1%
LevelForFileTypesDetection=2ĀĀĀĀĀĀĀ # 0 disables File types detection.
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # 2 reduces
AWStats speed by 1%
LevelForWormsDetection=0ĀĀĀĀĀĀĀĀĀĀĀ # 0 disables Worms detection.
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # 2 reduces
AWStats speed by 15%
UseFramesWhenCGI=1
DetailedReportsOnNewWindows=1
Expires=0
MaxRowsInHTMLOutput=1000
Lang="auto"
DirLang="/usr/share/awstats/lang"
ShowMenu=1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀ
ShowSummary=UVPHB
ShowMonthStats=UVPHB
ShowDaysOfMonthStats=VPHB
ShowDaysOfWeekStats=PHB
ShowHoursStats=PHB
ShowDomainsStats=PHB
ShowHostsStats=PHBL
ShowAuthenticatedUsers=0
ShowRobotsStats=HBL
ShowWormsStats=0
ShowEMailSenders=0
ShowEMailReceivers=0
ShowSessionsStats=1
ShowPagesStats=PBEX
ShowFileTypesStats=HB
ShowFileSizesStats=0ĀĀĀĀĀĀĀĀĀ
ShowOSStats=1
ShowBrowsersStats=1
ShowScreenSizeStats=0
ShowOriginStats=PH
ShowKeyphrasesStats=1
ShowKeywordsStats=1
ShowMiscStats=a
ShowHTTPErrorsStats=1
ShowSMTPErrorsStats=0
ShowClusterStats=0
AddDataArrayMonthStats=1
AddDataArrayShowDaysOfMonthStats=1
AddDataArrayShowDaysOfWeekStats=1
AddDataArrayShowHoursStats=1
IncludeInternalLinksInOriginSection=0
MaxNbOfDomain =
10
MinHitDomainĀ = 1
MaxNbOfHostsShown
= 10
MinHitHostĀĀĀ = 1
MaxNbOfLoginShown
= 10
MinHitLoginĀĀ = 1
MaxNbOfRobotShown
= 10
MinHitRobotĀĀ = 1
MaxNbOfPageShown
= 10
MinHitFileĀĀĀ = 1
MaxNbOfOsShown
= 10
MinHitOsĀĀĀĀĀ = 1
MaxNbOfBrowsersShown
= 10
MinHitBrowser =
1
MaxNbOfScreenSizesShown
= 5
MinHitScreenSize
= 1
MaxNbOfWindowSizesShown
= 5
MinHitWindowSize
= 1
MaxNbOfRefererShown
= 10
MinHitReferĀĀ = 1
MaxNbOfKeyphrasesShown
= 10
MinHitKeyphrase
= 1
MaxNbOfKeywordsShown
= 10
MinHitKeyword =
1
MaxNbOfEMailsShown
= 20
MinHitEMailĀĀ = 1
FirstDayOfWeek=1
ShowFlagLinks=""
ShowLinksOnUrl=1
UseHTTPSLinkForUrl=""
MaxLengthOfShownURL=64
HTMLHeadSection=""
HTMLEndSection=""
Logo="awstats_logo6.png"
LogoLink="http://awstats.sourceforge.net"
BarWidthĀĀ = 260
BarHeightĀ = 90
StyleSheet=""
color_Background="FFFFFF"ĀĀĀĀĀĀĀĀĀĀ # Background color for main page
(Default = "FFFFFF")
color_TableBGTitle="CCCCDD"ĀĀĀĀĀĀĀĀ # Background color for table title
(Default = "CCCCDD")
color_TableTitle="000000"ĀĀĀĀĀĀĀĀĀĀ # Table title font color (Default =
"000000")
color_TableBG="CCCCDD"ĀĀĀĀĀĀĀĀĀĀĀĀĀ # Background color for table
(Default = "CCCCDD")
color_TableRowTitle="FFFFFF"Ā # Table row title font color (Default =
"FFFFFF")
color_TableBGRowTitle="ECECEC"ĀĀĀĀĀ # Background color for row title (Default
= "ECECEC")
color_TableBorder="ECECEC"ĀĀĀĀĀĀĀĀĀ # Table border color (Default =
"ECECEC")
color_text="000000"ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # Color of text (Default
= "000000")
color_textpercent="606060"ĀĀĀĀĀĀĀĀĀ # Color of text for percent values
(Default = "606060")
color_titletext="000000"ĀĀĀĀĀĀĀĀĀĀĀ # Color of text title within colored
Title Rows (Default = "000000")
color_weekend="EAEAEA"ĀĀĀĀĀĀĀĀĀĀĀĀĀ # Color for week-end days (Default
= "EAEAEA")
color_link="0011BB"ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # Color of HTML links
(Default = "0011BB")
color_hover="605040"ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # Color of HTML on-mouseover
links (Default = "605040")
color_u="FFAA66"ĀĀĀĀĀĀĀĀĀĀĀĀĀ ĀĀĀĀĀ #
Background color for number of unique visitors (Default = "FFAA66")
color_v="F4F090"ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # Background color for
number of visites (Default = "F4F090")
color_p="4477DD"ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # Background color for
number of pages (Default = "4477DD")
color_h="66DDEE"ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # Background color for
number of hits (Default = "66DDEE")
color_k="2EA495"ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # Background color for
number of bytes (Default = "2EA495")
color_s="8888DD"ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # Background color for
number of search (Default = "8888DD")
color_e="CEC2E8"ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # Background color for
number of entry pages (Default = "CEC2E8")
color_x="C1B2E2"ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ # Background color for
number of exit pages (Default = "C1B2E2")
LoadPlugin="hashfiles"
ExtraTrackedRowsLimit=500
Include
"/etc/awstats/awstats.conf.local"
19.1.31. Fichero .htaccess
AuthUserFile
/var/www/awstats/cgi-bin/.htpasswd
AuthGroupFile
/dev/null
AuthName
"master-cluster1 WWW statistics"
AuthType Basic
<Limit
GET>
ĀĀĀĀĀĀĀ require user ivanc gabriel
ĀĀĀĀĀĀĀ order deny,allow
ĀĀĀĀĀĀĀ allow from all
</limit>
19.1.32. Script wakeup-cluster.sh
#!/bin/tcsh
#
#Ā Script de encendido del clusterĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ#
#
#Ā Uso: wakeup-cluster [nombre_nodo/all]ĀĀĀĀĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
#ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
#Ā Primer parßmetro:ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ#
#ĀĀĀ Se especifica el nombre del nodo a levantar
o "all" paraĀĀĀĀĀĀĀĀĀĀ # ĀĀĀhacerlo en todos los nodos del cluster.ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ Ā#
#ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
#ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
#ĀĀĀ Ivßn C.ĀĀĀĀ
#
if (
"$#" != "1" ) then
ĀĀ echo "Uso correcto: wakeup-cluster [-g
grupo] [num_nodo/all]"
ĀĀ exit 1
endif
switch($1)
ĀĀĀ case 'all':
ĀĀ ĀĀĀĀforeach node (`cat /etc/hosts|awk '{print
$2}'`)
ĀĀĀĀĀĀĀĀĀĀĀĀ echo Waking-up $node
ĀĀĀĀĀĀĀĀĀĀĀĀ /usr/sbin/etherwake -i eth0 ` arp
-a | grep node105 |awk '{print $4}'`
ĀĀĀĀĀĀ end
ĀĀĀĀĀĀĀĀĀ breaksw
default:
ĀĀĀĀĀĀ if ( `grep $1 /etc/hosts` !=
"" ) then
ĀĀĀĀĀĀĀĀĀ
echo Waking-up $1
ĀĀĀĀĀĀĀĀĀ /usr/sbin/etherwake -i eth0 ` arp -a
| grep node105 |awk '{print $4}'`
ĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀ echo "Error: nodo $1 no existe"
ĀĀĀĀĀĀĀĀĀ
exit 1
ĀĀĀĀĀĀ endif
ĀĀĀĀĀĀ breaksw
endsw
19.1.33. Script halt-cluster.sh
#
#Ā Script de parada/reboot de clusterĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ #
# ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ĀĀ
#Ā Uso: halt-cluster [-r/-h]
[nombre_nodo/all]ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
ĀĀĀĀĀĀĀ#Ā
#ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
#Ā Primer parßmetro:ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
#
#ĀĀĀ La opcion -r hace un reboot de un nodoĀĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
#ĀĀĀ La opcion -h hace halt (parada elķctrica)
del nodo, dejßndolo enĀĀ
#ĀĀĀ condiciones de ralizar wake-on-lanĀĀĀĀĀĀĀĀĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ#ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
#Ā Segundo parßmetro:ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ#
#ĀĀĀ Se especifica el nombre del nodo a
parar/rebotar o "all" para
#ĀĀĀ hacerlo en todos los nodos del
cluster.ĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ#
#ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
#ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
#
#ĀĀĀ Ivßn C.ĀĀĀĀ
#
if (
"$#" != "2" ) then
ĀĀ echo "Uso correcto: halt-cluster [-r/-h]
[num_nodo/all]"
ĀĀ exit 1
endif
if ((
"$1" != "-r") && ( "$1" !=
"-h")) then
ĀĀĀ echo "Parametro incorrecto $1. Uso correcto: halt-cluster [-r/-h] [nodo/all]"
ĀĀĀ exit 1
endif
switch ($1)
Ā case "-r":
ĀĀĀĀĀĀĀĀ set
command_line="/sbin/reboot"
ĀĀĀĀĀĀĀĀ set command="Rebooting"
ĀĀĀĀĀĀĀĀ breaksw
Ā case "-h":
ĀĀĀĀĀĀĀĀ set
command_line="/sbin/halt"
ĀĀĀĀĀĀĀĀ set command="Halting"
ĀĀĀĀĀĀĀĀ breaksw
Ā default:
ĀĀĀĀĀĀĀĀ echo "Error en argumento. Uso correcto: halt-cluster [-r/-h] [nodo/all]"
ĀĀĀĀĀĀĀĀ
exit 1
ĀĀĀĀĀĀĀĀ breaksw
Ā endsw
switch ($2)
Ā case "all":ĀĀ
ĀĀĀĀĀĀĀĀ foreach p (`cat /etc/hosts|grep
node|awk '{print $2}'`)
ĀĀĀĀĀĀĀĀĀĀĀĀĀ echo $command $p
ĀĀĀĀĀĀĀĀĀĀĀĀĀ if (`fping -u $p` ==
"") then
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ ssh $p $command_line
ĀĀĀĀĀĀĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "Warning: $p sin
conectividad"
ĀĀĀĀĀĀĀĀĀĀĀĀĀ endif
ĀĀĀĀĀĀĀĀ end
ĀĀĀĀĀĀĀĀ breaksw
Ā default:
ĀĀĀĀĀĀĀĀ breaksw
Ā endsw
19.1.34. Script alta_nodo.sh
#!/bin/bash
# Script de alta de nodosĀ (Septiembre 2008)
ESTE_MASTER=`uname
-n`
if [
$ESTE_MASTER == "master-cluster1" ]; then
ĀĀ OTRO_MASTER="master-cluster2"
else
ĀĀ OTRO_MASTER="master-cluster1"
fi
RANGO_IP=192.168
RANGO_STORAGE=0
RANGO_EIXAM=1
RANGO_TENADA=2
RANGO_NOZOMI=3
MCAST_CHANNEL_EIXAM=239.
MCAST_CHANNEL_NOZOMI=239.
MCAST_CHANNEL_TENADA=239.
MCAST_CHANNEL_STORAGE=239.
LINEA=""
echo "Script de ALTA de nodos en cluster LSI"
echo ""
read -p "1) A qu? grupo pertenece el nuevo nodo? (eixam/nozomi/tenada/storage) " grupo
if [ $grupo == "eixam" ]; then
ĀĀ rango=$RANGO_EIXAM
elif [ $grupo == "nozomi" ]; then
ĀĀ rango=$RANGO_NOZOMI
elif [ $grupo == "tenada" ]; then
ĀĀ rango=$RANGO_TENADA
elif [ $grupo
== "storage" ]; then
ĀĀ rango=$RANGO_STORAGE
else
ĀĀ echo "Error, grupo incorrecto"
ĀĀ exit 1
fi
echo
""
read -p
"2) @MAC " MAC_NODO
# Comprobar MAC
echo ""
read -p "3) Numero de nodo (Sin contar el \"$rango\" por ser nodo de $grupo) " num_nodo
if [ $num_nodo -gt 99 ]; then
ĀĀ echo "ĀĀ N?mero de nodo debe ser < 100"
ĀĀ exit 1
fi
IP_AUX=`expr
$num_nodo \+ 100`
IP_NODO=$RANGO_IP.$rango.$IP_AUX
# Damos nombre al nodo:
if [ $grupo == "storage" ]; then
ĀĀ NOMBRE_NODO=disc$num_nodo
else
ĀĀ NOMBRE_NODO=node$rango$num_nodo
fi
echo ""
echo "ĀĀ Nuevo nodo: $NOMBRE_NODO con IP $IP_NODO"
Ā
# Comprobamos que nodo no esta en /etc/hosts
if [ `grep
$NOMBRE_NODO /etc/hosts | wc -l` -ne 0 ]; then
ĀĀ echo "ĀĀ Error. $NOMBRE_NODO ya est? dado de alta en /etc/hosts"
ĀĀ exit 1
fi
if [ `grep
^$NOMBRE_NODO /root/files/nodes/nodes|wc -l` -ne 0 ]; then
ĀĀ echo "ĀĀ Error. $NOMBRE_NODO ya est? dado de alta en fichero nodes"
ĀĀ exit 1
fi
LINEA="$NOMBRE_NODO"
if [ $grupo !=
"storage" ]; then
ĀĀ LINEA="$LINEAĀĀĀĀĀĀĀ NOĀĀĀĀĀ
-ĀĀĀĀĀĀ -"
else
ĀĀ echo ""
ĀĀ read -p "5) Rol del nuevo nodo? (P)rimario o (S)ecundario " rol
ĀĀ if [ $rol != "p" ]
&& [ $rol != "P" ] && [ $rol != "s" ]
&& [ $rol != "S" ]; then
ĀĀĀĀĀ echo "Error, rol debe ser
\"P\" ? \"S\""
ĀĀ fi
ĀĀ case $rol in
ĀĀĀĀĀ p) rol="P"
ĀĀĀĀĀĀĀĀ ;;
ĀĀĀĀĀ s) rol="S"
ĀĀĀĀĀĀĀĀ ;;
ĀĀ esac
ĀĀ LINEA="$LINEAĀĀĀĀĀĀĀ SIĀĀĀĀĀ $rol"
ĀĀ echo ""
ĀĀ read -p "6) Pairnode (nombre completo) ? " pairnode
ĀĀ # Si rol de nodo es secundario => pairnode es primario => DEBE EXISTIR
ĀĀ LINEA="$LINEAĀĀĀĀĀĀĀ $pairnode"
ĀĀ EXISTE_PRIMARIO=`grep ^$pairnode
/root/files/nodes/nodes`
ĀĀ if [ "$rol" == "s" ] ||
[ "$rol" == "S" ]; then
if [ "$EXISTE_PRIMARIO" == "" ]; then
ĀĀĀĀĀĀĀĀ echo "ĀĀ Error, pairnode $pairnode no existe"
ĀĀĀĀĀĀĀĀ
exit 1
ĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀ ROL_PAIRNODE=`echo
$EXISTE_PRIMARIO|awk '{print $3}'`
ĀĀĀĀĀĀĀĀ if [ $ROL_PAIRNODE != "P" ]; then
ĀĀĀĀĀĀĀĀĀĀĀ echo "ĀĀ Error. Pairnode ($pairnode) no es nodo PRIMARIO"
ĀĀĀĀĀĀĀĀĀĀĀ
exit 1
ĀĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀĀ PAIRNODE_PAIRNODE=`echo
$EXISTE_PRIMARIO|awk '{print $4}'`
ĀĀĀĀĀĀĀĀĀĀĀ if [ $PAIRNODE_PAIRNODE != "$NOMBRE_NODO" ]; then
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ echo "ĀĀ Error. Pairnode ($pairnode) no tiene a $NOMBRE_NODO como secundario"
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
exit 1
ĀĀĀĀĀĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ LINEA="$LINEAĀĀĀĀĀĀ $PAIRNODE"
ĀĀĀĀĀĀĀĀĀĀĀ fi
ĀĀĀĀĀĀĀĀ fi
ĀĀĀĀĀĀ fi
ĀĀ fi
ĀĀ LINEA="$LINEAĀĀĀĀĀĀĀ $PAIRNODE"
Ā fi
# A±adimos informaci¾n de la cola
## Comprobar
cola
if [ $grupo ==
"eixam" ]; then
ĀĀ LINEA="$LINEAĀĀĀĀĀĀĀĀĀĀĀ eixamĀĀĀĀĀĀĀĀĀĀ $MCAST_CHANNEL_EIXAM"
elif [ $grupo
== "nozomi" ]; then
ĀĀ LINEA="$LINEAĀĀĀĀĀĀĀ nozomiĀĀĀĀĀĀĀĀĀ $MCAST_CHANNEL_NOZOMI"
elif [ $grupo
== "tenada" ]; then
ĀĀ LINEA="$LINEAĀĀĀĀĀĀĀ tenadaĀĀĀĀĀĀĀĀĀ $MCAST_CHANNEL_TENADA"
elif [ $grupo
== "storage" ]; then
ĀĀ LINEA="$LINEAĀĀĀĀĀĀĀ storageĀĀĀĀĀĀĀĀ $MCAST_CHANNEL_STORAGE"
else
ĀĀ echo "ERROR: Cola $COLA no existe"
ĀĀ exit 1
fi
echo "$LINEA"
## Metemos nodo en DHCP
echo ""
echo "* Damos de alta $nombre_nodo en DHCP"
echo
""
sed 's/ĀĀĀ #### Cluster Nodes ####/ĀĀĀ #### Cluster Nodes ####\n\nĀĀĀ host '$NOMBRE_NODO' {\nĀ har
dware ethernet
'$MAC_NODO';\nĀĀĀĀĀ fixed-address '$IP_NODO';\nĀĀĀ }/' /etc/dhcp3/dhcpd.conf > /tmp
/.dhcpd.conf
cp
/etc/dhcp3/dhcpd.conf /etc/dhcp3/dhcpd.conf.old
cp
/tmp/.dhcpd.conf /etc/dhcp3/dhcpd.conf
rm
/tmp/.dhcpd.conf
/etc/init.d/dhcp3-server
restart
# Copiamos config. dhcp al otro nodo master y reiniciamos
echo "[LCLSI] Reiniciando dhcp en el otro nodo master"
sed
s/"Ā option routers
192.168.0.201;"/"Ā option
routers 192.168.0.202;"/ /etc/dhcp3/dhcpd.conf >
Ā/tmp/.dhcpd.conf
scp
/tmp/.dhcpd.conf $OTRO_MASTER:/etc/dhcp3/dhcpd.conf
rm /tmp/.dhcpd.conf
ssh $OTRO_MASTER "/etc/init.d/dhcp3-server restart"
# A±adimos nodo a /etc/hosts
echo "$IP_NODOĀ $NOMBRE_NODO" >> /etc/hosts
# 6. SunGrid. Convertimos host en nodo de ejecuci¾n
if [ $grupo != "storage" ]; then
ĀĀ echo "[LCLSI] Dando permisos administrativos a nodo $NOMBRE_NODO en SGE"
ĀĀ /usr/local/sge/bin/lx24-x86/qconf -ah $NOMBRE_NODO
fi
ĀĀ echo $LINEA >> /root/files/nodes/nodes
ĀĀ scp /root/files/nodes/nodes
$OTRO_MASTER:/root/files/nodes/nodes
ĀĀ # A?adimos host a lista de dsh
ĀĀ echo $NOMBRE_NODO >> /etc/dsh/machines.list
ĀĀ echo $NOMBRE_NODO >> /etc/dsh/group/$grupo
ĀĀ scp /etc/dsh/machines.list
$OTRO_MASTER:/etc/dsh/
ĀĀ scp /etc/dsh/group/$grupo
$OTRO_MASTER:/etc/dsh/groups
ĀĀ # Propagamos ficheros hosts y nodes a todo el cluster
ĀĀ #/usr/bin/dsh -a "scp $ESTE_MASTER:/etc/hosts /etc/"
ĀĀ scp /etc/hosts $OTRO_MASTER:/etc/
19.1.35. Script alta_usuario.sh
#!/bin/tcsh
#
# Script de alta de usuario en cluster
set
ESTE_MASTER=`uname -n`
if (
"$ESTE_MASTER" == "master-cluster1" ) then
ĀĀ set OTRO_MASTER="master-cluster2"
else
ĀĀ set OTRO_MASTER="master-cluster1"
endif
set
CLUSTERS="eixam nozomi tenada"
if ( "$#" != "2" ) then
ĀĀ echo "ERROR. N?mero de parßmetros incorrecto"
ĀĀ echo "ĀĀĀĀĀĀ Uso correcto: new_user.sh username
cluster"
ĀĀ exit 1
endif
if ( `grep -w $1 /etc/allowed_users | wc -l` != "0" ) then
ĀĀ echo "ERROR: Usuario $1 ya incluido en lista de acceso"
ĀĀ exit 1
endif
if (
`/usr/bin/ypcat passwd | cut -f1 -d: | grep -w $1 | wc -l` == "0" )
then
ĀĀ echo "ERROR: Usuario $1 no es usuario NIS"
ĀĀ exit 1
endif
set
cluster_valido=0
foreach cluster
($CLUSTERS)
Ā if ( $2 == $cluster ) then
ĀĀĀĀ set cluster_valido=1
ĀĀĀĀ break;
Ā endif
end
if ( $cluster_valido == 0 ) then
ĀĀĀ echo "[LCLSI] Error, cluster no existe."
ĀĀĀ echo "ĀĀĀĀĀĀĀ Clusters v?lidos: $CLUSTERS"
ĀĀĀ exit 1
endif
echo
"$1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ $2" >>
/etc/allowed_users
/root/scripts/build_users.sh
/root/scripts/build_homes.sh
echo "Propagando info usuario a nodos del cluster"
echo "ESTE MASTER: $ESTE_MASTER"
/usr/bin/dsh -a "scp ${ESTE_MASTER}:/etc/passwd.nodes /etc/passwd;scp ${ESTE_MASTER}:/etc/shadow /
etc/shadow;scp
${ESTE_MASTER}:/etc/group /etc/group"
scp
/etc/allowed_users ${OTRO_MASTER}:/etc/allowed_users
scp /etc/passwd ${OTRO_MASTER}:/etc/passwd
scp /etc/shadow ${OTRO_MASTER}:/etc/shadow
scp /etc/group ${OTRO_MASTER}:/etc/group
# A?adimos usuario a lista de acceso
echo "A?adimos usuario $1 a lista de acceso $2"
/usr/local/sge/bin/lx24-x86/qconf
-au $1 $2
19.1.36. Script build_users.sh
#!/bin/bash
#
# Script de creaci¾n de ficheros passwd, shadow y group
#
cp /etc/passwd.old /etc/passwd
cp /etc/passwd.old /etc/passwd.nodes
cp /etc/shadow.old /etc/shadow
cp
/etc/group.old /etc/group
# Inclu?mos grupos it y sistemas en /etc/group
echo "it:x:100:" >> /etc/group
echo "beclsi:x:1900:" >> /etc/group
echo "becproy:x:1800:" >> /etc/group
echo "doctorat:x:1600:" >> /etc/group
echo "sistemas:x:50:" >>Ā /etc/group
echo "pfc:x:3100:" >> /etc/group
echo "p:x:500:" >> /etc/group
echo "ia:x:400:" >> /etc/group
echo "master:x:40000:" >> /etc/group
echo "altres:x:600:" >> /etc/group
# A±adimos usuarios de grupo
Āset
ALLOWED="tools:x:2000:"
foreach user
(`cat /etc/allowed_users|awk '{print $1}'`)
Ā set line=`/usr/bin/ypcat passwd | grep -w
^$user`
Ā set USERNAME=`echo $line |cut -f1 -d:`
Ā set PASSWORD=`echo $line |cut -f2 -d:`
Ā set UID=`echo $line | cut -f3 -d:`
Ā set GID=`echo $line | cut -f4 -d:`
Ā if ( $USERNAME != "" ) then
ĀĀĀĀ echo
$USERNAME":x:"$UID":"$GID"::/home/usuaris/"$USERNAME":/bin/tcsh"
>> /etc/passwd
ĀĀĀĀ echo $USERNAME":x:"$UID":"$GID"::/home/usuaris/"$USERNAME":/bin/false"
>> /etc/passwd.nodes
ĀĀĀĀ echo
$USERNAME":"$PASSWORD":12424:0:99999:7:::" >>
/etc/shadow
Ā endif
Ā set ALLOWED=$ALLOWED$user","
end
# Creamos grupo
tools
echo $ALLOWED
>> /etc/group
19.1.37. Script build_homes.sh
#!/bin/tcsh
#
# Script de creaci¾n de zonas de usuario
if !( -d /home/usuaris ) then
ĀĀ echo "[LCLSI] Creada zona de usuarios"
ĀĀ mkdir /home/usuaris
endif
# Creamos zona
tools
if !( -d
/home/usuaris/tools ) then
ĀĀ echo "[LCLSI] Creada zona tools"
ĀĀ mkdir /home/usuaris/tools
ĀĀ chown root:tools /home/usuaris/tools
ĀĀ chmod 775 /home/usuaris/tools
endif
foreach line
(`cat /etc/passwd | awk '/:400::|:500::|:3100::|:100::|:50::|:1900::|:1800::|:600::|:
40000::|:1600::/
{print $1}'`)
Ā set USERNAME=`echo $line | cut -f1 -d:`
Ā set GROUP=`echo $line | cut -f4 -d:`
Ā if ( $USERNAME != "" ) then
ĀĀĀ if !( -d /home/usuaris/$USERNAME ) then
ĀĀĀĀĀĀ echo "[LCLSI] Creada zona de usuario $USERNAME"
ĀĀĀĀĀĀ mkdir /home/usuaris/$USERNAME
ĀĀĀĀĀĀ cp /etc/skel/.tcshrc
/home/usuaris/$USERNAME/
ĀĀĀĀĀĀ # Fichero .sge_qstat
ĀĀĀĀĀĀ set QUEUE=`grep -w ^$USERNAME
/etc/allowed_users|awk '{print $2}'`
ĀĀĀĀĀĀ if ( $QUEUE == "all" ) then
ĀĀĀĀĀĀĀĀĀ echo "-u *" >
/home/usuaris/$USERNAME/.sge_qstat
ĀĀĀĀĀĀ else
ĀĀĀĀĀĀĀĀĀ echo "-u * -q $QUEUE" >
/home/usuaris/$USERNAME/.sge_qstat
ĀĀĀĀĀĀ endif
ĀĀĀĀĀĀ chown -R
"$USERNAME":"$GROUP" /home/usuaris/$USERNAME
ĀĀĀ endif
Ā endif
end
19.1.38. Script master_lectura.sh
#!/bin/sh
echo " "
echo "master <numero_jobs>
<concurrencia>"
echo " "
if [ "$1" == "" ]
then
ĀĀĀ echo
"Falta el parametro 1"
ĀĀĀ exit 0
else
if [ "$2" == "" ]
then
ĀĀĀ echo
"Falta el parametro 2"
ĀĀĀ exit 0
fi
fi
touch
/home/usuaris/ivanc/RESULTADOS/RESULTADO_lectura.TXT
echo " "Ā
>> /home/usuaris/ivanc/RESULTADOS/RESULTADO_lectura.TXT
echo " "Ā
>> /home/usuaris/ivanc/RESULTADOS/RESULTADO_lectura.TXT
echo "=============================================================================="
>> /home/usuaris/ivanc/R
ESULTADOS/RESULTADO_lectura.TXT
echo "Ejecutando $1 Jobs con concurrencia
$2" >> /home/usuaris/ivanc/RESULTADOS/RESULTADO_lectura.TXT
echo " " >>
/home/usuaris/ivanc/RESULTADOS/RESULTADO_lectura.TXT
contador=0
while [ $contador -lt $1 ] ; do
ĀĀĀ qsub
/home/usuaris/ivanc/EXE/slave.sh $2
ĀĀĀ
contador=`expr $contador + 1`
done
19.1.39. Script slave.sh
#!/bin/csh
#$ -M ivanc@lsi.upc.edu
#$ -m beas
/home/usuaris/ivanc/EXE/test-disco_lectura.sh
/home/usuaris/ivanc/5MB /home/usuaris/ivanc/RESULTADOS $1
19.1.40. Script test-disco_lectura.sh
#!/bin/sh
echo "
"
echo
"test_disco_lectura.sh <path_lectura> <path_escritura>
<concurrencia>"
echo "
"
echo "
"
if [
"$1" == "" ]
then
ĀĀĀ echo "Falta el parametro 1"
ĀĀĀ exit 0
else
if [ "$2" == "" ]
then
ĀĀĀ echo "Falta el parametro
2"
ĀĀĀ exit 0
else
if [ "$3" == "" ]
then
ĀĀĀ echo "Falta el parametro 3"
ĀĀĀ exit 0
fi
fi
fi
echo
"Leyendo $1 con concurrencia $3"
echo " "
contador=0
while [ $contador -lt $3 ] ; do
ĀĀĀ if [ -d $2 ]
ĀĀĀ then
ĀĀĀĀĀĀĀĀ echo "Ya existe el directorio $2 .... se
sobreescribiran los archivos."
ĀĀĀĀĀĀĀĀ echo " "
ĀĀĀ else
ĀĀĀĀĀĀĀĀ mkdir -p $2
ĀĀĀ fi
ĀĀĀ echo "NO => Lanzado en background
el proceso TAR (sin gzip!) en $2"
#ĀĀĀ /usr/bin/time -f "Tiempo CPU : %E
s.\nCPUĀĀĀĀĀĀĀ : %P\nRAMĀĀĀĀĀĀĀ : %M\n" tar -cjf $2/$contador $1
&
ĀĀĀ
ĀĀĀ
ĀĀĀ echo "Realizo un cat * > /dev/null
de $2 (Resultado a?adido en $2/RESULTADO_lectura.TXT)"
/usr/bin/time
-o $2/RESULTADO_lectura.TXT -a -f "Tiempo CPU `uname -n`: %E s.\nCPUĀĀĀĀĀĀĀ : %P\nRAMĀĀĀĀĀĀĀ : %
M\n" find $1 -type f -exec cat {} > /dev/null \;
ĀĀĀ contador=`expr $contador + 1`
done
wait
19.1.41. Script master_escritura.sh
#!/bin/sh
echo "
"
echo
"master <numero_jobs> <concurrencia>"
echo "
"
if [
"$1" == "" ]
then
ĀĀĀ echo "Falta el parametro 1"
ĀĀĀ exit 0
else
if [
"$2" == "" ]
then
ĀĀĀ echo "Falta el parametro 2"
ĀĀĀ exit 0
fi
fi
echo "
"Ā >>
/home/usuaris/ivanc/RESULTADOS/RESULTADO_escritura.TXT
echo "
"Ā >>
/home/usuaris/ivanc/RESULTADOS/RESULTADO_escritura.TXT
echo
"=============================================================================="
>> /home/usuaris/ivanc/R
ESULTADOS/RESULTADO_escritura.TXT
echo
"Ejecutando $1 Jobs con concurrencia $2" >>
/home/usuaris/ivanc/RESULTADOS/RESULTADO_escritura.TXT
echo "
" >> /home/usuaris/ivanc/RESULTADOS/RESULTADO_escritura.TXT
contador=0
while [ $contador -lt $1 ] ; do
ĀĀĀ qsub
/home/usuaris/ivanc/EXE/slave2.sh $2
ĀĀĀ contador=`expr $contador + 1`
done
19.1.42. Script slave2.sh
#!/bin/csh
#$ -M ivanc@lsi.upc.edu
#$ -m beas
/home/usuaris/ivanc/EXE/test-disco_escritura.sh
/dev/shm/test-disco.5Mb.tar.bz2 /home/usuaris/ivanc/5MBytes/`d
ate +%H_%M_%S`/`uname -n` $1
19.1.43. Script test-disco_escritura.sh
#!/bin/sh
echo "
"
echo
"test_disco_escritura.sh <nombre_fichero> <path_escritura>
<concurrencia>"
echo "
"
echo "
"
echo
"============================ Ficheros Disponibles
============================================"
ls *.tar.bz2
echo "=============================================================================================="
echo "
"
if [
"$1" == "" ]
then
ĀĀĀ echo "Falta el parametro 1"
ĀĀĀ exit 0
else
if [ "$2" == "" ]
then
ĀĀĀ echo "Falta el parametro
2"
ĀĀĀ exit 0
else
if [ "$3" == "" ]
then
ĀĀĀ echo "Falta el parametro 3"
ĀĀĀ exit 0
fi
fi
fi
echo
"Deshaciendo $1 en $2 con concurrencia $3"
echo "
"
contador=0
while [
$contador -lt $3 ] ; do
ĀĀĀ if [ -d $2/$PPID.$contador ]
ĀĀĀ then
ĀĀĀĀĀĀĀĀ echo "Ya existe el directorio
$2/$contador .... se sobreescribiran los archivos."
ĀĀĀ else
ĀĀĀĀĀĀĀĀ mkdir -p $2/$PPID.$contador
ĀĀĀ fi
ĀĀĀ echo "Lanzado en background el proceso
en $2/$PPID.$contador"
ĀĀĀ /usr/bin/time -o /home/usuaris/ivanc/RESULTADOS/RESULTADO_escritura.TXT
-a -f "Tiempo CPU `uname -n`: %E s
.\nCPUĀĀĀĀĀĀĀ : %P\nRAMĀĀĀĀĀĀĀ : %M\n" tar -C $2/$PPID.$contador
-xjf $1Ā &
ĀĀĀ contador=`expr $contador + 1`
done
wait
19.1.44. Fichero resultado_lectura.sh
=====================================================================
Ejecutando 1
Jobs con concurrencia 1
Ā
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 9%
RAMĀĀĀĀĀĀĀ : 0
^^^ node4 ^^^
Ā
Ā
=====================================================================
Ejecutando 6
Jobs con concurrencia 1
Ā
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 5%
RAMĀĀĀĀĀĀĀ : 0
^^^ node4 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 5%
RAMĀĀĀĀĀĀĀ : 0
^^^ node5 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 6%
RAMĀĀĀĀĀĀĀ : 0
^^^ node1 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 5%
RAMĀĀĀĀĀĀĀ : 0
^^^ node2 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 5%
RAMĀĀĀĀĀĀĀ : 0
^^^ node6 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 4%
RAMĀĀĀĀĀĀĀ : 0
^^^ node3 ^^^
Ā
Ā
=====================================================================
Ejecutando 10
Jobs con concurrencia 1
Ā
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 4%
RAMĀĀĀĀĀĀĀ : 0
^^^ node4 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 4%
RAMĀĀĀĀĀĀĀ : 0
^^^ node3 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 4%
RAMĀĀĀĀĀĀĀ : 0
^^^ node2 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 4%
RAMĀĀĀĀĀĀĀ : 0
^^^ node2 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 3%
RAMĀĀĀĀĀĀĀ : 0
^^^ node5 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 3%
RAMĀĀĀĀĀĀĀ : 0
^^^ node5 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 3%
RAMĀĀĀĀĀĀĀ : 0
^^^ node6 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 3%
RAMĀĀĀĀĀĀĀ : 0
^^^ node1 ^^^
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 3%
RAMĀĀĀĀĀĀĀ : 0
Tiempo CPU :
CPUĀĀĀĀĀĀĀ : 3%
RAMĀĀĀĀĀĀĀ : 0
19.1.45. Listado de paquetes de software instalado
A continuaci¾n se incluye la lista completa del software instalado como paquete Debian. Junto con el nombre del paquete se especifica la versi¾n del mismo, que es la ·ltima disponible en el momento de realizar la instalaci¾n del cluster.
NombreĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ versi¾n
AdduserĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.102
AlienĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.64
AntlrĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.7.6-7
apache-commonĀĀĀĀĀĀĀĀĀĀ 1.3.34-4.1+etch1
apache2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.2.3-4+etch5
apache2-mpm-preforkĀĀĀĀ 2.2.3-4+etch5
apache2-utilsĀĀĀĀĀĀĀĀĀĀ 2.2.3-4+etch5
apache2.2-commonĀĀĀĀĀĀĀ 2.2.3-4+etch5
aptĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.6.46.4-0.1
apt-utilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.6.46.4-0.1
aptitudeĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.4.4-4
aspellĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.60.4-4
aspell-esĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.9-8
atĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ
attrĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.32-1
autoconfĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.61-4
autoconf2.13ĀĀĀĀĀĀĀĀĀĀĀ 2.13-58
autofsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.4-13
automake1.4ĀĀĀĀĀĀĀĀĀĀĀĀ 1.4-p6-12
autotools-devĀĀĀĀĀĀĀĀĀĀ 20060702.1
awstatsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 6.5+dfsg-1
base-filesĀĀĀĀĀĀĀĀĀĀĀĀĀ 4
base-passwdĀĀĀĀĀĀĀĀĀĀĀĀ
bashĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.1dfsg-8
bcĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.06-20
bibindexĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.10-5
bibtoolĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.48alpha.2-3
biffĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.17.pre20000412-3
bin86ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.16.14-1.4
bind-docĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.4.7-1
bind9ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.3.4-2etch3
bind9-docĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.3.4-2etch3
bind9-hostĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.3.4-2etch3
binutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.17-3
bisonĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.3.dfsg-4
bltĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4z-4
blt-devĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4z-4
bonnie++ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.03a+b1
bsdmainutilsĀĀĀĀĀĀĀĀĀĀĀ 6.1.6
bsdutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.12r-19etch1
busyboxĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.3-4
bwmĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.0-8.1
bzip2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.3-6
c2manĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.41-17
ca-certificatesĀĀĀĀĀĀĀĀ 20070303
cflowĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1-1
console-commonĀĀĀĀĀĀĀĀĀ 0.7.69
console-dataĀĀĀĀĀĀĀĀĀĀĀ 1.01-7
console-toolsĀĀĀĀĀĀĀĀĀĀ 0.2.3dbs-65
coreutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.97-5.3
courier-authdaemonĀĀĀĀĀ 0.58-4
courier-authlibĀĀĀĀĀĀĀĀ 0.58-4
courier-authlib-userdbĀ 0.58-4
courier-baseĀĀĀĀĀĀĀĀĀĀĀ 0.53.3-5
cpioĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.6-18.1+etch1
cppĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-15
cpp-2.95ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.95.4-27
cpp-3.3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.3.6-15
cpp-3.4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.4.6-5
cpp-4.1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-21
cramfsprogsĀĀĀĀĀĀĀĀĀĀĀĀ 1.1-6
cronĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.0pl1-100
cshĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 20060813-1
cutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.6-3
cvsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.12.13-8
cxrefĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.6a-1.1
dashĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.5.3-7
db4.4-utilĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.4.20-8
dcĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.06-20
dddĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.3.11-1
debconfĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.5.11etch2
debconf-i18nĀĀĀĀĀĀĀĀĀĀĀ 1.5.11etch2
debconf-utilsĀĀĀĀĀĀĀĀĀĀ 1.5.11etch2
debhelperĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.0.42
debian-archive-keyringĀ
debian-reference-common
debian-reference-esĀĀĀĀ 1.11
debianutilsĀĀĀĀĀĀĀĀĀĀĀĀ 2.17
defomaĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.11.10-0.1
devscriptsĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.9.26
dhcp-clientĀĀĀĀĀĀĀĀĀĀĀĀ 2.0pl5-19.5etch2
dhcp3-commonĀĀĀĀĀĀĀĀĀĀĀ 3.0.4-13
dhcp3-serverĀĀĀĀĀĀĀĀĀĀĀ 3.0.4-13
dialogĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0-20060221-3
dictionaries-commonĀĀĀĀ 0.70.10
diffĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.8.1-11
diffstatĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.43-2
discover1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.7.19
discover1-dataĀĀĀĀĀĀĀĀĀ 2.2007.02.02
dmidecodeĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.8-4
dnsutilsĀĀĀ ĀĀĀĀĀĀĀĀĀĀĀ 9.3.4-2etch3
doc-debianĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.1.5
doc-debian-esĀĀĀĀĀĀĀĀĀĀ 2.5
doc-linux-esĀĀĀĀĀĀĀĀĀĀĀ 2003.04-2
doc-linux-textĀĀĀĀĀĀĀĀĀ 2007.02-1
dpkgĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.13.25
dpkg-devĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.13.25
dselectĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.13.25
dshĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.25.7-1
dvidviĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0-8etch2
e2fslibsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.39+1.40-WIP-2006.11.14+dfsg-2etch1
e2fsprogsĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.39+1.40-WIP-2006.11.14+dfsg-2etch1
ecj-bootstrapĀĀĀĀĀĀĀĀĀĀ 3.2.1-3
ecj-bootstrap-gcjĀĀĀĀĀĀ 3.2.1-3
edĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.2-20
ejectĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.1.4-3
emacs21ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 21.4a+1-3etch1
emacs21-bin-commonĀĀĀĀĀ 21.4a+1-3etch1
emacs21-commonĀĀĀĀĀĀĀĀĀ 21.4a+1-3etch1
emacsen-commonĀĀĀĀĀĀĀĀĀ 1.4.17
esound-commonĀĀĀĀĀĀĀĀĀĀ 0.2.36-3
etherwakeĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.09-1
ethtoolĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5-1
exim4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.63-17
exim4-baseĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.63-17
exim4-configĀĀĀĀĀĀĀĀĀĀĀ 4.63-17
exim4-daemon-lightĀĀĀĀĀ 4.63-17
fastjarĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-21
fdutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.5-20060227-1.1
fftw2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.1.3-20
fileĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.17-5etch3
fileutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.97-5.3
findutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.2.28-1etch1
fingerĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.17-10
flexĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.5.33-11
fontconfigĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.2-1.2
fontconfig-configĀĀĀĀĀĀ 2.4.2-1.2
fpingĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4b2-to-ipv6-14
ftnchekĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.3.1-1
ftpĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.17-16
fvwmĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.5.18-3
g++ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-15
g++-2.95ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.95.4-27
g++-3.3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.3.6-15
g++-4.1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-21
g77ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.4.6-19
g77-3.4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.4.6-5
gadflyĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.0-11
ganglia-monitorĀĀĀĀĀĀĀĀ 2.5.7-3.1
gappletviewer-4.1ĀĀĀĀĀĀ 4.1.1-20
gawkĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.1.5.dfsg-4
gccĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-15
gcc-2.95ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.95.4-27
gcc-3.3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.3.6-15
gcc-3.3-baseĀĀĀĀĀĀĀĀĀĀĀ 3.3.6-15
gcc-3.4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.4.6-5
gcc-3.4-baseĀĀĀĀĀĀĀĀĀĀĀ 3.4.6-5
gcc-4.1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-21
gcc-4.1-baseĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-21
gcj-4.1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-20
gcj-4.1-baseĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-20
gconf2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.16.1-1
gconf2-commonĀĀĀĀĀĀĀĀĀĀ 2.16.1-1
gdbĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 6.4.90.dfsg-1
gdk-imlib1ĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.9.14-31
gdk-imlib11ĀĀĀĀĀĀĀĀĀĀĀĀ 1.9.14-31
gettextĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.16.1-1
gettext-baseĀĀĀĀĀĀĀĀĀĀĀ 0.16.1-1
gij-4.1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-20
gjdocĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.7.7-7
glibc-docĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.3.6.ds1-13etch7
gmetadĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.5.7-3.1
gnome-binĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.2-34
gnome-libs-dataĀĀĀĀĀĀĀĀ 1.4.2-34
gnu-efiĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.0c-1
gnupgĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.6-2
gnuplotĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.0.0-5
gnuplot-noxĀĀĀĀĀĀĀĀĀĀĀĀ 4.0.0-5
gnuplot-x11ĀĀĀĀĀĀĀĀĀĀĀĀ 4.0.0-5
gpgvĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.6-2
grepĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.5.1.ds2-6
groff-baseĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.18.1.1-12
grubĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.97-27etch1
gsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.54.dfsg.1-5etch1
gs-commonĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.3.11
gs-gplĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.54.dfsg.1-5etch1
gsfontsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.11+urwcyr1.0.7~pre41-1
gsfonts-x11ĀĀĀĀĀĀĀĀĀĀĀĀ 0.20
gsl-binĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.8-2
gvĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.6.2-3
gzipĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.3.5-15
hdparmĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 6.9-2
heartbeatĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.5-3
hostnameĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.93
html2textĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.3.2a-3
htmlgenĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.2.2-10
hyperlatexĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.8b-3
iamericanĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.1.20.0-4.3
ibritishĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.1.20.0-4.3
icatalanĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.5-3
iceweaselĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.0.0.16-0etch1
iconxĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.4.2-2.7
ifstatĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1-5.0.1
iftopĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.17-3
ifupdownĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.6.8
imlib-baseĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.9.14-31
indentĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.2.9-7
infoĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.8.dfsg.1-4
initramfs-toolsĀĀĀĀĀĀĀĀ 0.85i
initrd-toolsĀĀĀĀĀĀĀĀĀĀĀ 0.1.84.2
initscriptsĀĀĀĀĀĀĀĀĀĀĀĀ 2.86.ds1-38+etchnhalf.1
intltool-debianĀĀĀĀĀĀĀĀ 0.35.0+20060710.1
ipchainsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.3.10-15
iperfĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.0.2-2
iprouteĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 20061002-3
iptablesĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.3.6.0debian1-5
iputils-pingĀĀĀĀĀĀĀĀĀĀĀ 20020927-6
iso-codesĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0a-1
ispanishĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.9-8
ispellĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.1.20.0-4.3
itcl3.1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.1.0-7.1
itcl3.1-devĀĀĀĀĀĀĀĀĀĀĀĀ 3.1.0-7.1
java-commonĀĀĀĀĀĀĀĀĀĀĀĀ 0.25
java-gcj-compatĀĀĀĀĀĀĀĀ 1.0.65-10
java-gcj-compat-devĀĀĀĀ 1.0.65-10
jfsutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.11-1
kernel-image-2.4.27-2ĀĀ 2.4.27-10sarge1
klibc-utilsĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.34-2
klogdĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.1-18
lacheckĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.26-9
language-envĀĀĀĀĀĀĀĀĀĀĀ 0.68
laptop-detectĀĀĀĀĀĀĀĀĀĀ 0.12.1
lessĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 394-4
lesstif1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.93.94-11.4
lesstif2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.94.4-2
libacl1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.2.41-1
libamu2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 6.0.9-3.2
libapache2-mod-php5ĀĀĀĀ 5.2.0-8+etch11
libapr1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.7-8.2
libaprutil1ĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.7+dfsg-2
libapt-pkg-perlĀĀĀĀĀĀĀĀ 0.1.20
libart-2.0-2ĀĀĀĀĀĀĀĀĀĀĀ 2.3.17-1
libart-2.0-devĀĀĀĀĀĀĀĀĀ 2.3.17-1
libart2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.2-34
libasound2ĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.13-2
libaspell15ĀĀĀĀĀĀĀĀĀĀĀĀ 0.60.4-4
libatk1.0-0ĀĀĀĀĀĀĀĀĀĀĀĀ 1.12.4-3
libatm1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.1-17
libattr1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.32-1
libaudio-devĀĀĀĀĀĀĀĀĀĀĀ 1.8-4
libaudio2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.8-4
libaudiofile0ĀĀĀĀĀĀĀĀĀĀ 0.2.6-6
libbeecrypt6ĀĀĀĀĀĀĀĀĀĀĀ 4.1.2-6
libbind9-0ĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.3.4-2etch3
libblkid1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.39+1.40-WIP-2006.11.14+dfsg-2etch1
libbonobo2ĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.22-2.2
libbz2-1.0ĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.3-6
libc6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.3.6.ds1-13etch7
libc6-devĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.3.6.ds1-13etch7
libcairo2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.4-4.1+etch1
libcap1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.10-14
libcomerr2ĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.39+1.40-WIP-2006.11.14+dfsg-2etch1
libconfig-inifiles-perl 2.39-2
libconsoleĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.2.3dbs-65
libcsiro0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.6.1-10
libcupsys2ĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.7-4etch4
libcupsys2-devĀĀĀĀĀĀĀĀĀ 1.2.7-4etch4
libcurl3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 7.15.5-1etch1
libcurl3-gnutlsĀĀĀĀĀĀĀĀ 7.15.5-1etch1
libdb1-compatĀĀĀĀĀĀĀĀĀĀ 2.1.3-9
libdb2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.7.7.0-9
libdb3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.2.9+dfsg-0.1
libdb3-utilĀĀĀĀĀĀĀĀĀĀĀĀ 3.2.9+dfsg-0.1
libdb4.2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.2.52+dfsg-2
libdb4.3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.3.29-8
libdb4.4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.4.20-8
libdbi-perlĀĀĀĀĀĀĀĀĀĀĀĀ 1.53-1etch1
libdbus-1-3ĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.2-1+etch1
libdbus-glib-1-2ĀĀĀĀĀĀĀ 0.71-3
libdevmapper1.01ĀĀĀĀĀĀĀ 1.01.00-4
libdevmapper1.02ĀĀĀĀĀĀĀ 1.02.08-1
libdiscover1ĀĀĀĀĀĀĀĀĀĀĀ 1.7.19
libdns16ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.2.4-1
libdns22ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.3.4-2etch3
libdrm2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.0.2-0.1
libdshconfig1ĀĀĀĀĀĀĀĀĀĀ 0.20.12-2
libedit2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.9.cvs.20050518-2.2
libefs1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.22-2.2
libelfg0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.8.6-3
libesd0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.2.36-3
libevent1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1a-1
libexpat1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.95.8-3.4
libexpat1-devĀĀĀĀĀĀĀĀĀĀ 1.95.8-3.4
libfam0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.7.0-12
libfam0c102ĀĀĀĀĀĀĀĀĀĀĀĀ 2.7.0-12
libflac6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.1-5
libflac7ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.2-8
libfontconfig1ĀĀĀĀĀĀĀĀĀ 2.4.2-1.2
libfontconfig1-devĀĀĀĀĀ 2.4.2-1.2
libfontenc-devĀĀĀĀĀĀĀĀĀ 1.0.2-2
libfontenc1ĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.2-2
libfreetype6ĀĀĀĀĀĀĀĀĀĀĀ 2.2.1-5+etch2
libfreetype6-devĀĀĀĀĀĀĀ 2.2.1-5+etch2
libfribidi0ĀĀĀĀĀĀĀĀĀĀĀĀ 0.10.7-4
libfs6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.0-4
libg2c0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.4.6-5
libg2c0-devĀĀĀĀĀĀĀĀĀĀĀĀ 3.4.6-5
libgc1c2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 6.8-1
libgcc1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-21
libgcj-bcĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-21
libgcj-commonĀĀĀĀĀĀĀĀĀĀ 4.1.1-21
libgcj7-0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-20
libgcj7-awtĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-20
libgcj7-devĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-20
libgcj7-jarĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-20
libgconf2-4ĀĀĀĀĀĀĀĀĀĀĀĀ 2.16.1-1
libgcrypt11ĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.3-2
libgcrypt11-devĀĀĀĀĀĀĀĀ 1.2.3-2
libgd2-xpmĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.0.33-5.2etch1
libgdbm3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.8.3-3
libgdk-pixbuf2ĀĀĀĀĀĀĀĀĀ 0.22.0-11
libgimpprint1ĀĀĀĀĀĀĀĀĀĀ 4.2.7-10
libgl1-mesa-devĀĀ ĀĀĀĀĀ 6.5.1-0.6
libgl1-mesa-driĀĀĀĀĀĀĀĀ 6.5.1-0.6
libgl1-mesa-glxĀĀĀĀĀĀĀĀ 6.5.1-0.6
libglade-gnome0ĀĀĀĀĀĀĀĀ 0.17-8
libglade0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.17-8
libglib1.2ĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.10-17
libglib2.0-0ĀĀĀĀĀĀĀĀĀĀĀ 2.12.4-2
libglu1-mesaĀĀĀĀĀĀĀĀĀĀĀ 6.5.1-0.6
libgmp3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.4-6
libgnome32ĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.2-34
libgnomeprint-binĀĀĀĀĀĀ 0.37-12
libgnomeprint-dataĀĀĀĀĀ 0.37-12
libgnomeprint15ĀĀĀĀĀĀĀĀ 0.37-12
libgnomesupport0ĀĀĀĀĀĀĀ 1.4.2-34
libgnomeui32ĀĀĀĀĀĀĀĀĀĀĀ 1.4.2-34
libgnorba27ĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.2-34
libgnorbagtk0ĀĀĀĀĀĀĀĀĀĀ 1.4.2-34
libgnutls-devĀĀĀĀĀĀĀĀĀĀ 1.4.4-3+etch1
libgnutls11ĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.16-13.1
libgnutls13ĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.4-3+etch1
libgpg-error-devĀĀĀĀĀĀĀ 1.4-1
libgpg-error0ĀĀĀĀĀĀĀĀĀĀ 1.4-1
libgpmg1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.19.6-25
libgsl0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.8-2
libgsl0-devĀĀĀĀĀĀĀĀĀĀĀĀ 1.8-2
libgssapi2ĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.10-4
libgtk1.2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.10-18
libgtk1.2-commonĀĀĀĀĀĀĀ 1.2.10-18
libgtk2.0-0ĀĀĀĀĀĀĀĀĀĀĀĀ 2.8.20-7
libgtk2.0-commonĀĀĀĀĀĀĀ 2.8.20-7
libgtkxmhtml1ĀĀĀĀĀĀĀĀĀĀ 1.4.2-34
libhdf4gĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1r4-18.1
libhesiod0ĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.0.2-18.1
libibverbs-devĀĀĀĀĀĀĀĀĀ 1.0.4-1
libibverbs1ĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.4-1
libice-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-2
libice6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-2
libid3tag0ĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.15.1b-10
libidentĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.22-3
libidl0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.8.6-1
libidn11ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.6.5-1
libisc11ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.3.4-2etch3
libisc7ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.2.4-1
libisccc0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.3.4-2etch3
libisccfg1ĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.3.4-2etch3
libjack0.100.0-0ĀĀĀĀĀĀĀ 0.101.1-2
libjasper-1.701-1ĀĀĀĀĀĀ 1.701.0-2
libjpeg62ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 6b-13
libjpeg62-devĀĀĀĀĀĀĀĀĀĀ 6b-13
libklibcĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.34-2
libkpathsea3ĀĀĀĀĀĀĀĀĀĀĀ 2.0.2-30sarge4
libkpathsea4ĀĀĀĀĀĀĀĀĀĀĀ 3.0-30
libkrb53ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.4-7etch6
liblcms1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.15-1
liblcms1-devĀĀĀĀĀĀĀĀĀĀĀ 1.15-1
libldap-2.2-7ĀĀĀĀĀĀĀĀĀĀ 2.2.23-8
libldap2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.1.30-13.3
liblocale-gettext-perlĀ 1.05-1
liblockfile1ĀĀĀĀĀĀĀĀĀĀĀ 1.06.1
libltdl3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.5.22-4
liblwres1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.2.4-1
liblwres9ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 9.3.4-2etch3
liblzo-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.08-3
liblzo1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.08-3
libmad0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.15.1b-2.1
libmagic1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.17-5etch3
libmagick9ĀĀĀĀĀĀĀĀĀĀĀĀĀ 6.2.4.5.dfsg1-0.14
libmng-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.9-1
libmng1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.9-1
libmodplug0c2ĀĀĀĀĀĀĀĀĀĀ 0.7-5.2
libmpcdec3ĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.2-1
libmpich1.0c2ĀĀĀĀĀĀĀĀĀĀ 1.2.7-2
libmyspell3c2ĀĀĀĀĀĀĀĀĀĀ 3.1-18
libmysql-javaĀĀĀĀĀĀĀĀĀĀ 5.0.4+dfsg-2
libncurses5ĀĀĀĀĀĀĀĀĀĀĀĀ 5.5-5
libncurses5-devĀĀĀĀĀĀĀĀ 5.5-5
libncursesw5ĀĀĀĀĀĀĀĀĀĀĀ 5.5-5
libneon25ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.25.5.dfsg-6
libnet-daemon-perlĀĀĀĀĀ 0.38-1.1
libnet1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.2.1-2
libnetpbm10ĀĀĀĀĀĀĀĀĀĀĀĀ 10.0-11.1+etch1
libnewt0.52ĀĀĀĀĀĀĀĀĀĀĀĀ 0.52.2-10
libnfsidmap2ĀĀĀĀĀĀĀĀĀĀĀ 0.18-0
libnss-dbĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.2.3pre1-2
liboaf0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.6.10-8
libogg0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.3-2
libopencdk8ĀĀĀĀĀĀĀĀĀĀĀĀ 0.5.9-2
libopencdk8-devĀĀĀĀĀĀĀĀ 0.5.9-2
liborbit0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.5.17-11.1
liborbit2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.14.3-0.2
libpam-modulesĀĀĀĀĀĀĀĀĀ 0.79-5
libpam-runtimeĀĀĀĀĀĀĀĀĀ 0.79-5
libpam0gĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.79-5
libpango1.0-0ĀĀĀĀĀĀĀĀĀĀ 1.14.8-5
libpango1.0-commonĀĀĀĀĀ 1.14.8-5
libpaper1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.21
libparted1.7-1ĀĀĀĀĀĀĀĀĀ 1.7.1-5.1
libpcap0.7ĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.7.2-7
libpcap0.8ĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.9.5-1
libpci2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.1.11-3
libpcre3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 6.7+7.4-4
libperl5.8ĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.8.8-7etch3
libpils0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.5-3
libplot2c2ĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.1-15
libplplot9ĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.6.1-10
libplrpc-perlĀĀĀĀĀĀĀĀĀĀ 0.2017-1.1
libpng12-0ĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.15~beta5-1
libpng12-devĀĀĀĀĀĀĀĀĀĀĀ 1.2.15~beta5-1
libpng3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.15~beta5-1
libpoppler0c2ĀĀĀĀĀĀĀĀĀĀ 0.4.5-5.1etch3
libpopt-devĀĀĀĀĀĀĀĀĀĀĀĀ 1.10-3
libpopt0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.10-3
libpq4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.1.11-0etch1
libqhull5ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2003.1-2
libqt3-headersĀĀĀĀĀĀĀĀĀ 3.3.7-4etch2
libqt3-mtĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.3.7-4etch2
libqt3c102ĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.3.4-3
libreadline4ĀĀĀĀĀĀĀĀĀĀĀ 4.3-11
libreadline5ĀĀĀĀĀĀĀĀĀĀĀ 5.2-2
librpcsecgss3ĀĀĀĀĀĀĀĀĀĀ 0.14-2etch3
librplay3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.3.2-11
librpm4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.4.1-13
librrd2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.15-0.3
librrd2-devĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.15-0.3
libsamplerate0ĀĀĀĀĀĀĀĀĀ 0.1.2-2
libsasl2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.1.22.dfsg1-8
libsasl2-2ĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.1.22.dfsg1-8
libselinux1ĀĀĀĀĀĀĀĀĀĀĀĀ 1.32-3
libsemanage1ĀĀĀĀĀĀĀĀĀĀĀ 1.8-1
libsensors3ĀĀĀĀĀĀĀĀĀĀĀĀ 2.10.1-3
libsepol1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.14-2
libsigc++-1.2-5c102ĀĀĀĀ 1.2.5-4
libsigc++-2.0-0c2aĀĀĀĀĀ 2.0.17-2
libslang2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.0.6-4
libslp1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.1-6.2
libsm-devĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-3
libsm6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-3
libsndfile1ĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.16-2
libsnmp-baseĀĀĀĀĀĀĀĀĀĀĀ 5.2.3-7etch2
libsnmp9ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.2.3-7etch2
libspeex1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.12-3etch1
libsqlite3-0ĀĀĀĀĀĀĀĀĀĀĀ 3.3.8-1.1
libss2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.39+1.40-WIP-2006.11.14+dfsg-2etch1
libssl0.9.7ĀĀĀĀĀĀĀĀĀĀĀĀ 0.9.7k-3.1etch1
libssl0.9.8ĀĀĀĀĀĀĀĀĀĀĀĀ 0.9.8c-4etch3
libssp0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-21
libstdc++2.10-devĀĀĀĀĀĀ 2.95.4-27
libstdc++2.10-glibc2.2Ā 2.95.4-27
libstdc++5ĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.3.6-15
libstdc++5-3.3-devĀĀĀĀĀ 3.3.6-15
libstdc++6ĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.1-21
libstdc++6-4.1-devĀĀĀĀĀ 4.1.1-21
libstonith0ĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.5-3
libstroke0ĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.5.1-5
libsvga1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.3-24
libsysfs-devĀĀĀĀĀĀĀĀĀĀĀ 2.1.0-1
libsysfs2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.1.0-1
libt1-5ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.1.0-2etch1
libtag1c2aĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4-4
libtagc0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4-4
libtasn1-0ĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.1.2-5
libtasn1-2ĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.2.10-3
libtasn1-3ĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.3.6-2
libtasn1-3-devĀĀĀĀĀĀĀĀĀ 0.3.6-2
libterm-readkey-perlĀĀĀ 2.30-3
libtext-charwidth-perlĀ 0.04-4
libtext-iconv-perlĀĀĀĀĀ 1.4-3
libtext-wrapi18n-perlĀĀ 0.06-5
libtextwrap1ĀĀĀĀĀĀĀĀĀĀĀ 0.1-5
libtiff4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.8.2-7+etch1
libungif4gĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.4-4
libusb-0.1-4ĀĀĀĀĀĀĀĀĀĀĀ 0.1.12-5
libuuid1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.39+1.40-WIP-2006.11.14+dfsg-2etch1
libvolume-id0ĀĀĀĀĀĀĀĀĀĀ 0.105-4
libvorbis0aĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.2.dfsg-1.4
libvorbisfile3ĀĀĀĀĀĀĀĀĀ 1.1.2.dfsg-1.4
libwrap0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 7.6.dbs-13
libwww0ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.4.0-11
libx11-6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.3-7
libx11-dataĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.3-7
libx11-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.3-7
libxau-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-2
libxau6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-2
libxaw-headersĀĀĀĀĀĀĀĀĀ 1.0.2-4
libxaw7ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.2-4
libxaw7-devĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.2-4
libxcursor-devĀĀĀĀĀĀĀĀĀ 1.1.7-4
libxcursor1ĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.7-4
libxdmcp-devĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-2
libxdmcp6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-2
libxext-devĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-2
libxext6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-2
libxfixes-devĀĀĀĀĀĀĀĀĀĀ 4.0.1-5
libxfixes3ĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.0.1-5
libxfont-devĀĀĀĀĀĀĀĀĀĀĀ 1.2.2-2.etch1
libxfont1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.2-2.etch1
libxft-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.1.8.2-8
libxft2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.1.8.2-8
libxi-devĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-4
libxi6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-4
libxinerama-devĀĀĀĀĀĀĀĀ 1.0.1-4.1
libxinerama1ĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-4.1
libxkbfile1ĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.3-2
libxml1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.8.17-14
libxml2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.6.27.dfsg-4
libxmu-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.2-2
libxmu-headersĀĀĀĀĀĀĀĀĀ 1.0.2-2
libxmu6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.2-2
libxmuu-devĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.2-2
libxmuu1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.2-2
libxp-devĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.0.xsf1-1
libxp6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.0.xsf1-1
libxpm-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.5.5-2
libxpm4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.5.5-2
libxrandr-devĀĀĀĀĀĀĀĀĀĀ 1.1.0.2-5
libxrandr2ĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.0.2-5
libxrender-devĀĀĀĀĀĀĀĀĀ 0.9.1-3
libxrender1ĀĀĀĀĀĀĀĀĀĀĀĀ 0.9.1-3
libxss1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.0-1
libxt-devĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.2-2
libxt6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.2-2
libxtrap-devĀĀĀĀĀĀĀĀĀĀĀ 1.0.0-4
libxtrap6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.0-4
libxtst-devĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-5
libxtst6ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-5
libxv-devĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.2-1
libxv1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.2-1
libxxf86dga1ĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-2
libxxf86vm1ĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-2
libzvt2ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.2-34
linux-headers-2.6.18-5Ā 2.6.18.dfsg.1-13etch6
linux-headers-2.6.18-5-686-bigmemĀ ĀĀĀĀĀĀĀĀĀĀĀĀ 2.6.18.dfsg.1-13etch6
linux-headers-2.6.24-etchnhalf.1-686-bigmemĀĀĀĀ 2.6.24-6~etchnhalf.4
linux-headers-2.6.24-etchnhalf.1-commonĀĀĀĀĀĀĀĀ 2.6.24-6~etchnhalf.4
linux-image-2.6.18-5-686-bigmemĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.6.18.dfsg.1-13etch6
linux-kbuild-2.6.18ĀĀĀĀ 2.6.18-1
linux-kbuild-2.6.24ĀĀĀĀ 2.6.24-1~etchnhalf.1
linux-kernel-headersĀĀĀ 2.6.18-7
linux-patch-debian-2.6.18ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.6.18.dfsg.1-22etch2
linux-patch-debian-2.6.24ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.6.24-6~etchnhalf.4
linux-source-2.6.18ĀĀĀĀ 2.6.18.dfsg.1-22etch2
linux-source-2.6.24ĀĀĀĀ 2.6.24-6~etchnhalf.4
linux-tree-2.6.24ĀĀĀĀĀĀ 2.6.24-6~etchnhalf.4
localesĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.3.6.ds1-13etch7
localization-configĀĀĀĀ 0.116
loginĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.0.18.1-7
logrotateĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.7.1-3
lsb-baseĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.1-23.2etch1
lsofĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.77.dfsg.1-3
ltraceĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.4-1
lynxĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.8.5-2sarge2.2
m4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.8-2
mailxĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.1.2-0.20050715cvs-1
makeĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.81-2
makedevĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.3.1-83
man-dbĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.3-6
manpagesĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.39-1
manpages-devĀĀĀĀĀĀĀĀĀĀĀ 2.39-1
manpages-esĀĀĀĀĀĀĀĀĀĀĀĀ 1.55-4
mawkĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.3.3-11
mbrĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.9-2
mdadmĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.5.6-9
memstatĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.4.0.0.1
mesa-common-devĀĀĀĀĀĀĀĀ 6.5.1-0.6
mime-supportĀĀĀĀĀĀĀĀĀĀĀ 3.39-1
mktempĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.5-2
mocĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.1-1
modconfĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.3.1
module-init-toolsĀĀĀĀĀĀ 3.3-pre4-2
modutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.27.0-6
mountĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.12r-19etch1
mozilla-firefoxĀĀĀĀĀĀĀĀ 2.0.0.16-0etch1
mpackĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.6-4
mtoolsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.9.10.ds1-3
mtr-tinyĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.71-2etch1
muttĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.5.13-1.1etch1
myspell-esĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.9-8
nagios-nrpe-serverĀĀĀĀĀ 2.5.1-3
nagios-plugins-basicĀĀĀ 1.4.5-1etch1
nanoĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.0.2-1etch1
ncurses-baseĀĀĀĀĀĀĀĀĀĀĀ 5.5-5
ncurses-binĀĀĀĀĀĀĀĀĀĀĀĀ 5.5-5
ncurses-termĀĀĀĀĀĀĀĀĀĀĀ 5.5-5
net-toolsĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.60-17
netbaseĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.29
netcatĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.10-32
netcdfg3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.5.0-7.1
netkit-pingĀĀĀĀĀĀĀĀĀĀĀĀ 20020927-6
netpbmĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 10.0-11.1+etch1
nfs-commonĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.10-6+etch.1
nfs-kernel-serverĀĀĀĀĀĀ 1.0.10-6+etch.1
nisĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.17-6
nowebmĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.11b-2
ntpĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.2.2.p4+dfsg-2
ntpdateĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.2.2.p4+dfsg-2
nviĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.79-25
oafĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.6.10-8
openbsd-inetdĀĀĀĀĀĀĀĀĀĀ 0.20050402-6
openssh-blacklistĀĀĀĀĀĀ 0.1.1
openssh-clientĀĀĀĀĀĀĀĀĀ 4.3p2-9etch2
openssh-serverĀĀĀĀĀĀĀĀĀ 4.3p2-9etch2
opensslĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.9.8c-4etch3
partedĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.7.1-5.1
passwdĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.0.18.1-7
patchĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.5.9-4
pciutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.2.4~pre4-1
pdlĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.3-3
perlĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.8.8-7etch3
perl-baseĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.8.8-7etch3
perl-modulesĀĀĀĀĀĀĀĀĀĀĀ 5.8.8-7etch3
php5-commonĀĀĀĀĀĀĀĀĀĀĀĀ 5.2.0-8+etch11
php5-gdĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.2.0-8+etch11
pidentdĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.0.19.ds1-1
pkg-configĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.21-1
plotutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.1-15
po-debconfĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.8
policycoreutilsĀĀĀĀĀĀĀĀ 1.32-3
portmapĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5-26
procmailĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.22-16
procpsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.2.7-3
projĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.4.9d-2
psmiscĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 22.3-1
psutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.17-24
pythonĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.4-2
python-centralĀĀĀĀĀĀĀĀĀ 0.5.12
python-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.4-2
python-gadflyĀĀĀĀĀĀĀĀĀĀ 1.0.0-11
python-gdk-imlib-1.2ĀĀĀ 0.6.12-8
python-gendocĀĀĀĀ ĀĀĀĀĀ 0.73-11
python-glade-1.2ĀĀĀĀĀĀĀ 0.6.12-8
python-gtk-1.2ĀĀĀĀĀĀĀĀĀ 0.6.12-8
python-htmlgenĀĀĀĀĀĀĀĀĀ 2.2.2-11
python-minimalĀĀĀĀĀĀĀĀĀ 2.4.4-2
python-newtĀĀĀĀĀĀĀĀĀĀĀĀ 0.52.2-10
python-pmwĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2-5
python-selinuxĀĀĀĀĀĀĀĀĀ 1.32-3
python-semanageĀĀĀĀĀĀĀĀ 1.8-1
python-supportĀĀĀĀĀĀĀĀĀ 0.5.6
python-tkĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.4-1
python2.4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.4.4-3+etch1
python2.4-devĀĀĀĀĀĀĀĀĀĀ 2.4.4-3+etch1
python2.4-minimalĀĀĀĀĀĀ 2.4.4-3+etch1
python2.4-numericĀĀĀĀĀĀ 23.8-1
python2.4-xmlĀĀĀĀĀĀĀĀĀĀ 0.8.4-1
qt3-designerĀĀĀĀĀĀĀĀĀĀĀ 3.3.7-4etch2
qt3-dev-toolĀĀĀĀĀĀĀĀĀĀĀ 3.3.7-4etch2
quiltĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.45-6
rasmolĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.7.2.1.1-5
rcsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.7-18
rdateĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4-8
readline-commonĀĀĀĀĀĀĀĀ 5.2-2
reiserfsprogsĀĀĀĀĀĀĀĀĀĀ 3.6.19-4
render-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.9.2-4
reportbugĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.31
rpmĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.4.1-13
rrdtoolĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.15-0.3
rsh-serverĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.17-13
rsyncĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.6.9-2etch2
sedĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1.5-1
setserialĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.17-43
sharutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.2.1-15
shellutilsĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.97-5.3
slang1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.9dbs-8
slang1a-utf8ĀĀĀĀĀĀĀĀĀĀĀ 1.4.9dbs-8
slatecĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.1-4
sshĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.3p2-9etch2
straceĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.5.14-2
sudoĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.6.8p12-4
svgalibg1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.3-24
sysklogdĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4.1-18
syslinuxĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.31-4
sysstatĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 7.0.0-4
sysv-rcĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.86.ds1-38+etchnhalf.1
sysvinitĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.86.ds1-38+etchnhalf.1
sysvinit-utilsĀĀĀĀĀĀĀĀĀ 2.86.ds1-38+etchnhalf.1
tarĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.16-2etch1
taskselĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.66
tasksel-dataĀĀĀĀĀĀĀĀĀĀĀ 2.66
tcl8.3ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.3.5-5
tcl8.3-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.3.5-5
tcl8.4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.4.12-1.1
tcl8.4-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.4.12-1.1
tcpdĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 7.6.dbs-13
tcshĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 6.14.00-7
telnetĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.17-34
tetex-baseĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.0.dfsg.3-5etch1
tetex-binĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.0-30
tetex-docĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.0.dfsg.3-5etch1
tex-commonĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1
texinfoĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.8.dfsg.1-4
textutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.97-5.3
timeĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.7-21
tk8.4ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.4.12-1etch2
tk8.4-devĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 8.4.12-1etch2
tktableĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.9-1
tktable-devĀĀĀĀĀĀĀĀĀĀĀĀ 2.9-1
tofrodosĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.7.6-2
tracerouteĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.4a12-21
ttf-bitstream-veraĀĀĀĀĀ 1.10-7
ttf-dejavuĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.15-1
tzdataĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2007k-1etch1
ucfĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.0020
udevĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.105-4
untexĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 9210-10
unzipĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5.52-9etch1
update-inetdĀĀĀĀĀĀĀĀĀĀĀ 4.27-0.5
usbutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.72-7
user-esĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.34
util-linuxĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.12r-19etch1
util-linux-localesĀĀĀĀĀ 2.12r-19etch1
vim-commonĀĀĀĀĀĀĀĀĀĀĀĀĀ 7.0-122+1etch3
vim-tinyĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 7.0-122+1etch3
w3mĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.5.1-5.1
wakeonlanĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.41-6
wamericanĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 6-2
wcatalanĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.5-3
wenglishĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 5-4
wgetĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.10.2-2
whiptailĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.52.2-10
whoisĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 4.7.20
wspanishĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.19
x-devĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 7.0.7-2
x11-commonĀĀĀĀĀĀĀĀĀĀĀĀĀ 7.1.0-19
x11proto-core-devĀĀĀĀĀĀ 7.0.7-2
x11proto-fixes-devĀĀĀĀĀ 4.0-2
x11proto-fonts-devĀĀĀĀĀ 2.0.2-5
x11proto-input-devĀĀĀĀĀ 1.3.2-4
x11proto-kb-devĀĀĀĀĀĀĀĀ 1.0.3-2
x11proto-print-devĀĀĀĀĀ 1.0.3.xsf1-1
x11proto-randr-devĀĀĀĀĀ 1.1.2-4
x11proto-record-devĀĀĀĀ 1.13.2-4
x11proto-render-devĀĀĀĀ 0.9.2-4
x11proto-trap-devĀĀĀĀĀĀ 3.4.3-5
x11proto-video-devĀĀĀĀĀ 2.2.2-4
x11proto-xext-devĀĀĀĀĀĀ 7.0.2-5
x11proto-xinerama-devĀĀ 1.1.2-4
xaw3dgĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.5+E-14
xbase-clientsĀĀĀĀĀĀĀĀĀĀ 7.1.ds1-2
xbitmapsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-2
xcursor-themesĀĀĀĀĀĀĀĀĀ 1.0.1-5
xdmĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.5-2
xfigĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.2.5-alpha5-9
xfonts-100dpiĀĀĀĀĀĀĀĀĀĀ 1.0.0-3
xfonts-75dpiĀĀĀĀĀĀĀĀĀĀĀ 1.0.0-3
xfonts-baseĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.0-4
xfonts-encodingsĀĀĀĀĀĀĀ 1.0.0-6
xfonts-scalableĀĀĀĀĀĀĀĀ 1.0.0-6
xfonts-utilsĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-1
xfsprogsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.8.11-1
xkb-dataĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 0.9-4
xlibmesa-glĀĀĀĀĀĀĀĀĀĀĀĀ 7.1.0-19
xlibmesa-gl-devĀĀĀĀĀĀĀĀ 7.1.0-19
xlibmesa-gluĀĀĀĀĀĀĀĀĀĀĀ 7.1.0-19
xlibs-dataĀĀĀĀĀĀĀĀĀĀĀĀĀ 7.1.0-19
xlibs-static-devĀĀĀĀĀĀĀ 7.1.0-19
xmhtml1ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.1.7-14
xpdfĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.01-9.1+etch5
xpdf-commonĀĀĀĀĀĀĀĀĀĀĀĀ 3.01-9.1+etch5
xpdf-readerĀĀĀĀĀĀĀĀĀĀĀĀ 3.01-9.1+etch5
xpdf-utilsĀĀĀĀĀĀĀĀĀĀĀĀĀ 3.01-9.1+etch5
xserver-xfree86ĀĀĀĀĀĀĀĀ 7.1.0-19
xserver-xorgĀĀĀĀĀĀĀĀĀĀĀ 7.1.0-19
xserver-xorg-coreĀĀĀĀĀĀ 1.1.1-21etch5
xserver-xorg-input-allĀ 7.1.0-19
xserver-xorg-input-evdĀ 1.1.2-6
xserver-xorg-input-kbdĀ 1.1.0-4
xserver-xorg-input-mouĀ 1.1.1-3
xserver-xorg-input-synĀ 0.14.6-1
xserver-xorg-input-wacĀ 0.7.4.1-5
xserver-xorg-video-allĀ 7.1.0-19
xserver-xorg-video-apmĀ 1.1.1-3
xserver-xorg-video-arkĀ 0.6.0-3
xserver-xorg-video-atiĀ 6.6.3-2
xserver-xorg-video-chiĀ 1.1.1-4
xserver-xorg-video-cirĀ 1.1.0-3
xserver-xorg-video-cyrĀ 1.1.0-4
xserver-xorg-video-dumĀ 0.2.0-3
xserver-xorg-video-fbdĀ 0.3.1-1
xserver-xorg-video-gliĀ 1.1.1-3
xserver-xorg-video-i12Ā 1.2.0-3
xserver-xorg-video-i74Ā 1.1.0-3
xserver-xorg-video-i810 1.7.2-4
xserver-xorg-video-imst 1.1.0-3
xserver-xorg-video-mgaĀ 1.4.4.dfsg.1-2
xserver-xorg-video-neoĀ 1.1.1-5
xserver-xorg-video-newp 0.2.0-3
xserver-xorg-video-nscĀ 2.8.1-3
xserver-xorg-video-nvĀĀ 2.0.3-1
xserver-xorg-video-rend 4.1.0.dfsg.1-4
xserver-xorg-video-s3ĀĀ 0.4.1-5
xserver-xorg-video-sisĀ 0.9.1-4
xserver-xorg-video-vesa 1.3.0-1
xserver-xorg-video-vgaĀ 4.1.0-3
xserver-xorg-video-viaĀ 0.2.1-6
xtermĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 222-1etch2
xtrans-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.0.1-3
xutilsĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 7.1.ds.3-1
xutils-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 7.1.ds-6
yorickĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 2.1.01cvs20060706-1
yorick-dataĀĀĀĀĀĀĀĀĀĀĀĀ 2.1.01cvs20060706-1
zlib-binĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.3-13
zlib1gĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.3-13
zlib1g-devĀĀĀĀĀĀĀĀĀĀĀĀĀ 1.2.3-13
19.2. ═ndice de
Figuras
4.1. El protocolo NFS en los
modelos OSI y TCP/IP, 21
4.2. Ejemplo de Cluster con
Lustre, 24
4.3. Ejemplo de configuraci¾n
de GlusterFS con 4 nodos de almacenamiento
ĀĀĀĀĀĀ y 1 nodo cliente, 25
5.1. Arquitectura de un cluster
tipo SSI, 27
5.2. Divisi¾n de procesos en
openMosix, 28
7.1. Esquema de cluster
openMosix de LSI, 35
7.2. el CPD de UPC en el
edificio Omega, 38
9.1. Esquema de hosts con
replicaci¾n de datos vĒa connexion de red dedicada, 44
9.2. Arquitectura del cluster
con Lustre (version 1.0), 45
9.3. Arquitectura revisada del
cluster con Lustre (version 1.1), 52
9.4. Throughput de lectura y
escritura del filesysten Lustre, 53
9.5. Throughput del filesystem
Lustre en lecturas, 54
9.6. Throughput del filesystem
Lustre en escrituras, 55
10.1. Arquitectura del cluster
con GlusterFS (version 2.0), 56
10.2. Throughput de lectura y
escritura del filesystem GlusterFS, 61
10.3.
Throughput del filesystem GlusterFS en lecturas, 62
10.4. Throughput del filesystem
GlusterFS en escrituras, 63
11.1. Esquema de las zonas
albergadas en los nodos master-cluster, 77
11.2. Esquema de cluster con
colas de ejecuci¾n y de espera, 79
11.3. Ventana de creaci¾n de
colas deasde qmon, 80
11.4. Ventana de administraci¾n
de grupos en qmon, 81
11.5. Ventana de control de
polĒticas del cluster desde qmon, 82
11.6. Ventana de control de la
polĒtica functional desde qmon, 83
13.1. Pamtalla de nodo
arrancando por PXE, 90
13.2. Interfaz de administrador
de Tivoli, 91
14.1. Daemons y flujo de datos
en un sistema Ganglia, 96
14.2. Pantalla principal de la
web Ganglia, 98
14.3. Grßfica de la mķtrica
jobs_running, 100
14.4. Grßfica de las mķtrica
jobs_queued, 101
14.5. Grßfica de la mķtrica
temperature_max, 101
14.6. Vista Ganglia general del
cluster, 103
14.7. Vista Ganglia de una cola,
104
14.8. Vista Ganglia de un nodo,
105
15.1. Vista de la web Nagios, 109
16.1. Web awstats (1), 118
16.2. Web awstats (2), 119
18.1. Esquema de cluster con
SAN y Lustre, 134
19.3. Juegos de
pruebas
A fin de evaluar los diferentes modelos de cluster propuestos, creamos un
juego de pruebas que nos ayude a valorar cada propuesta. El juego de pruebas
consta de las siguientes partes:
- Test de estabilidad: destinados a medir la capacidad de mantener
un funcionamiento adecuado en todo tipo de escenarios.
- Benchmarks sintķticos de disco: que miden el rendimiento mßximo del
filesystem.
- Test de usabilidad: mßs allß de benchmarks y n·meros
proporcionan la informaci¾n acerca del tiempo de respuesta del filesystem
a determinadas acciones de los usuarios.
Las pruebas se realizarßn
en el mismo orden que se han expuesto. Si el filesystem no tuviese el comportamiento
esperado en una de ellas, el modelo serĒa desechado y no serĒa necesario
realizar las pruebas siguientes.
19.3.1. Test de
estabilidad
El test de estabilidad del filesystem consistirß en la ejecucici¾n de un
benchmark sintķtico, explicado en el punto [19.3.2.2], pero con un juego de
pruebas de un tama±o muy grande[16]Ā que obligue al sistema a trabajar de forma
ininterrumpida durante varios dĒas.
El tiempo que tarde en finalizar el test no es importante. S¾lo cuando el
test finalice correctamente, sin ning·n error en los logs, consideraremos que
el sistema de ficheros es estable.
19.3.2.
Benchmarks sintķticos
El objetivo de la baterĒa de benchmarks sintķticos es obtener el
rendimiento mßximo o ideal de los distintos modelos de cluster. Las
prestaciones obtenidas con este tipo de pruebas rara vez se obtienen en el uso
cotidiano, y deben ser considerados como valores pico.
19.3.2.1. Throughput mßximo
dd es un commando habitual en sistemas UNIX que transfiere datos entre dos
disponisitivos. Los dispositivos pueden ser cualquier dispositivo UNIX como
discos, particiones, entrada y salida estßndar, etc.
Tras realizar la transferencia de datos especificada dd muestra la tasa de
transferencia obtenida. Utilizaremos este dato como indicativo de la tasa
mßxima de transferencia de los filesystems de los distintos sistemas
propuestos. Concretamente realizaremos las siguientes pruebas orientadas a
medir el throughput mßximo mediante m·ltiples lecturas y escrituras
secuenciales concurrentes de 1,2,3,4 y 5 ficheros de 50 MBytes.
En el caso de las pruebas de escritura leeremos de memoria, concretamente
del dispositivo /dev/null. El comando es el
siguiente:
master-cluster1> dd if=/dev/zero of=/home/usuaris/ivanc/test50MB
bs=1024
Anßlogamente, el comando de prueba de lectura escribirß en /dev/null:
master-cluster1> dd
if=/home/usuaris/shm/test50MB of=/dev/null bs=1024
19.3.2.2. Test ad-hoc
Por ·ltimo realizaremos una serie de test propios que simularßn la
ejecuci¾nĀ de multitud de procesos con
uso intensivo de E/S. Para ejecutar estos procesos aprovecharemos la
disponibilidad del sistema de colas Sun Grid, que se encargarß de repartirlos
entre los diferentes nodos del cluster.
Cada proceso leerß o escribirß un fichero de 5 Gbytes con el siguiente
contenido:
Ę
1024
directorios
o
1024 directorios
¦
1024 ficheros
de 5 Mbytes
Concretamente nuestra baterĒa de pruebas consistirß en la ejecuci¾n de 1,
2, 3, 6, 9, 18 y 36 instancias concurrentes del test con el fin de someter el
sistema de ficheros a distintos niveles de carga de E/S.
Midiendo el tiempo que tarda en finalizar cada test obtendremos la tasa de
lectura y escritura por proceso y el throughput agregado del sistema.
El funcionamiento del test es el siguiente:
master-cluster1> ./master_lectura.sh [n·mero_de_jobs] [concurrencia]
El script master_lectura.sh (apķndices [19.1.38]) lanza tantos procesos de E/S
como se especifique como parßmetro numero_de_jobs.
El parßmetro concurrencia permite
ejecutar tantos jobs como queramos en un mismo host.
El proceso de E/S, llamado slave.sh (apķndices [19.1.39]) es un shellscript Sun Grid
que ejecuta el programa test-disco_lectura.sh
(apķndices [19.1.40), que es el
encargado de leer datos del path especificado.
Anßlogamente ejecutamos el test de escritura:
master-cluster1> ./master_escritura.sh [n·mero_de_jobs] [concurrencia]
En este caso master_escritura.sh (apķndices [19.1.38]) encola tantos jobs slave2.sh
(apķndices [19.1.39]) como se especifique en el parßmetro n·mero_de_jobs.
A su vez slave2.sh ejecuta el programa test-disco_escritura.sh (apķndices [19.1.40]), que tiene como parßmetros
el archivo comprimido con los datos y el path donde se dejarßn.
Los resultados de estos tests se dejan en el directorio RESULTADOS, con nombre resultado_lectura.txt y resultado_escritura.txt. Puede
encontrarse un ejemplos delĀ formato de
estos ficheros en los apķndices [19.1.44].
19.3.3. Test de
usabilidad
El espacio de disco distribuido que planteamos en el cluster pretende ser
el lugar que albergue los datos de los usuarios. Por ello, el filesystem debe
responder como si se tratase de un filesystem local, sin importar los niveles
de carga del sistema.
De nada nos sirve un sistema de ficheros paralelo con un throughput muy alto si las latencias y los tiempos de respuesta que aprecian los usuarios al trabajar con ķl son altos.
Con el prop¾sito de comprobar la respuesta del filesystem en tareas cotidianas de un usuario medio medimos el tiempo de respuesta en acciones de usuario tĒpicas como:
Ę Hacer login en el sistema.
Ę Listar ficheros de un directorio.
Ę Listar ficheros de un directorio con miles de ficheros.
Ę Abrir fichero con un editor (vi).
Ę Modificar y guardar cambios en fichero (vi).
19.4.
Referencias bibliogrßficas
La siguiente lista contiene las referencias de la informaci¾n consultada en
la realizaci¾n de este proyecto.
Ę
Wikipedia.org, The Free Encyclopedia
Wikimedia Foundation, Inc.
URL: http://wikipedia.org/.
Wikipedia es una enciclopedia colaborativa que contiene gran cantidad de
informaci¾n relacionada con la informßica.
Ę
LinuxHPC.org, Linux High performance
Computing
URL: http://linuxhpc.org/.
Portal que ofrece noticas relacionadas con computaci¾n de altas
prestaciones, alta disponibilidad y clusters paralelos en Linux.
Ę
Lustre wiki
Sun Microsystems, Inc.
URL: http://wiki.lustre.org/.
Wikipedia official del sistema de ficheros Lustre, con todo tipo de
recursos, incluyendo enlaces a descargas, manuales, foros de discussion, etc.
Ę
Lustre File System
Sun Microsystems, Inc.
URL: http://www.sun.com/software/products/lustre
Espacio de la web de Sun Microsystems dedicado a su filesystem Lustre.
Ę
Global Parallel Filesystem
IBM, Inc.
URL: http://www-03.ibm.com/systems/cluster/gpfs/.
Espacio de la web de IBM dedicado a su filesystem GPFS.
Ę
GlusterFS ¢ Non stop cluster storage
URL: http://gluster.org/.
Web official del proyecto GlusterFS, con todo tipo de recursos.
Ę
Samba.org
URL: http://samba.org/.
Web official del proyecto Samba.
Ę
Debian.org
Software in the Public Interest, Inc.
URL: http://www.debian.org/.
Sitio web oficial de la distribuci¾n de Linux Debian.
Ę
High Availability Linux Project
URL: http://www.linux-ha.org/.
Web dedicada a proyectos relacionados con la alta disponibilidad en
entornos Linux, como heartbeat.
Ę
DRBD
Linbit HA-Solutions
URL: http://www.drbd.org/.
Web official del proyecto DRBD.
Ę
Sun Grid Engine
Sun Microsystems, Inc.
URL: http://sun.com/software/gridware/.
Espacio de la web de Sun microsystems dedicado a su sistema de colas Sun
Grid.
Ę
PBS GridWorks
Altair Corporate
Web official del sistemas de colas openPBS.
Ę
Condor project homepage
URL: http://www.cs.wisc.edu/condor/.
Pßgina del proyecto Condor, con manuales de instalaci¾n y administraci¾n.
Ę
Using Samba
Richard Sharpe, Tim Potter, Jim Morris. Ed. McMillian, 2000.
Libro de referencia sobre el protocolo Samba.
Ę
Managing NFS and NIS
Hal Stern, Mike Eisler & Ricardo Labiaga. Ed. OÆ Reilly, 2001.
Manual de administraci¾n de los servicios NFS y NIS.
Ę
SANs and NAS
W. Curtis Preston. Ed. OÆ Reilly, 2002.
Manual para administradores de sistemas de almacenamiento.
Ę
IBM Tivoli software
IBM, Inc.
URL: http://www.ibm.com/software/tiovli/.
Espacio de la web de IBM dedicado a su software Tivoli.
Ę
Nagios.org
Nagios Enterprises
URL: http://ww.nagios.org/.
Web official del proyecto de monitorizaci¾n de clusters Nagios.
Ę
The DHCP Handbook
Ralph Droms, Ted Lemon. Ed. MacMillan
Publishing Company, 1999.
Libro de referencia de DHCP. Contiene informaci¾n sobre todas sus
caracterĒsticas, configuraciones, opciones, etc.
Ę
Exim.org
URL: http://www.exim.org/.
Pßgina web official del proyecto MTA exim.
Ę
NTP: The Network Time Protocol
ntp.org
URL: http://www.ntp.org/.
Pßgina web official del proyecto NTP con manuales y acceso a mailing list.
Ę
Google Groups
Google, Inc.
Servicio de grupos de discusi¾n de todo tipo, incluidos temas informßticos.
Ę
Dell.com
Dell, Inc.
URL: http://www.dell.com/.
Fabricante de hardware.